feat: 切换后端至PaddleOCR-NCNN,切换工程为CMake
1.项目后端整体迁移至PaddleOCR-NCNN算法,已通过基本的兼容性测试 2.工程改为使用CMake组织,后续为了更好地兼容第三方库,不再提供QMake工程 3.重整权利声明文件,重整代码工程,确保最小化侵权风险 Log: 切换后端至PaddleOCR-NCNN,切换工程为CMake Change-Id: I4d5d2c5d37505a4a24b389b1a4c5d12f17bfa38c
This commit is contained in:
43
3rdparty/ncnn/tools/CMakeLists.txt
vendored
Normal file
43
3rdparty/ncnn/tools/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,43 @@
|
||||
cmake_minimum_required(VERSION 3.1) # for CMAKE_CXX_STANDARD
|
||||
set(CMAKE_CXX_STANDARD 11)
|
||||
macro(ncnn_install_tool toolname)
|
||||
install(TARGETS ${toolname} RUNTIME DESTINATION bin)
|
||||
endmacro()
|
||||
if(MSVC)
|
||||
# warning C4018: '<': signed/unsigned mismatch
|
||||
# warning C4244: 'argument': conversion from 'uint64_t' to 'const unsigned int', possible loss of data
|
||||
# warning C4996: 'fopen': This function or variable may be unsafe. Consider using fopen_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
|
||||
add_definitions(/wd4018 /wd4244 /wd4996)
|
||||
endif()
|
||||
|
||||
add_subdirectory(caffe)
|
||||
add_subdirectory(mxnet)
|
||||
add_subdirectory(onnx)
|
||||
add_subdirectory(darknet)
|
||||
if(NCNN_INT8)
|
||||
add_subdirectory(quantize)
|
||||
else()
|
||||
message(WARNING "NCNN_INT8 disabled, quantize tools won't be built")
|
||||
endif()
|
||||
|
||||
add_executable(ncnn2mem ncnn2mem.cpp)
|
||||
target_link_libraries(ncnn2mem PRIVATE ncnn)
|
||||
if(NCNN_VULKAN)
|
||||
target_link_libraries(ncnn2mem PRIVATE ${Vulkan_LIBRARY})
|
||||
endif()
|
||||
|
||||
add_executable(ncnnoptimize ncnnoptimize.cpp)
|
||||
target_link_libraries(ncnnoptimize PRIVATE ncnn)
|
||||
if(NCNN_VULKAN)
|
||||
target_link_libraries(ncnnoptimize PRIVATE ${Vulkan_LIBRARY})
|
||||
endif()
|
||||
|
||||
add_executable(ncnnmerge ncnnmerge.cpp)
|
||||
|
||||
# add all tools to a virtual project group
|
||||
set_property(TARGET ncnn2mem PROPERTY FOLDER "tools")
|
||||
set_property(TARGET ncnnoptimize PROPERTY FOLDER "tools")
|
||||
set_property(TARGET ncnnmerge PROPERTY FOLDER "tools")
|
||||
ncnn_install_tool(ncnn2mem)
|
||||
ncnn_install_tool(ncnnmerge)
|
||||
ncnn_install_tool(ncnnoptimize)
|
||||
18
3rdparty/ncnn/tools/caffe/CMakeLists.txt
vendored
Normal file
18
3rdparty/ncnn/tools/caffe/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,18 @@
|
||||
|
||||
find_package(Protobuf)
|
||||
|
||||
if(PROTOBUF_FOUND)
|
||||
protobuf_generate_cpp(CAFFE_PROTO_SRCS CAFFE_PROTO_HDRS caffe.proto)
|
||||
add_executable(caffe2ncnn caffe2ncnn.cpp ${CAFFE_PROTO_SRCS} ${CAFFE_PROTO_HDRS})
|
||||
target_include_directories(caffe2ncnn
|
||||
PRIVATE
|
||||
${PROTOBUF_INCLUDE_DIR}
|
||||
${CMAKE_CURRENT_BINARY_DIR})
|
||||
target_link_libraries(caffe2ncnn PRIVATE ${PROTOBUF_LIBRARIES})
|
||||
|
||||
# add all caffe2ncnn tool to a virtual project group
|
||||
set_property(TARGET caffe2ncnn PROPERTY FOLDER "tools/converter")
|
||||
ncnn_install_tool(caffe2ncnn)
|
||||
else()
|
||||
message(WARNING "Protobuf not found, caffe model convert tool won't be built")
|
||||
endif()
|
||||
1663
3rdparty/ncnn/tools/caffe/caffe.proto
vendored
Normal file
1663
3rdparty/ncnn/tools/caffe/caffe.proto
vendored
Normal file
File diff suppressed because it is too large
Load Diff
1187
3rdparty/ncnn/tools/caffe/caffe2ncnn.cpp
vendored
Normal file
1187
3rdparty/ncnn/tools/caffe/caffe2ncnn.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
3
3rdparty/ncnn/tools/darknet/CMakeLists.txt
vendored
Normal file
3
3rdparty/ncnn/tools/darknet/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
add_executable(darknet2ncnn darknet2ncnn.cpp)
|
||||
set_property(TARGET darknet2ncnn PROPERTY FOLDER "tools/converter")
|
||||
ncnn_install_tool(darknet2ncnn)
|
||||
65
3rdparty/ncnn/tools/darknet/README.md
vendored
Normal file
65
3rdparty/ncnn/tools/darknet/README.md
vendored
Normal file
@@ -0,0 +1,65 @@
|
||||
# Darknet To NCNN Conversion Tools
|
||||
|
||||
This is a standalone darknet2ncnn converter without additional dependency.
|
||||
|
||||
Support yolov4, yolov4-tiny, yolov3, yolov3-tiny and enet-coco.cfg (EfficientNetB0-Yolov3).
|
||||
|
||||
Another conversion tool based on darknet can be found at: [darknet2ncnn](https://github.com/xiangweizeng/darknet2ncnn)
|
||||
|
||||
## Usage
|
||||
|
||||
```
|
||||
Usage: darknet2ncnn [darknetcfg] [darknetweights] [ncnnparam] [ncnnbin] [merge_output]
|
||||
[darknetcfg] .cfg file of input darknet model.
|
||||
[darknetweights] .weights file of input darknet model.
|
||||
[cnnparam] .param file of output ncnn model.
|
||||
[ncnnbin] .bin file of output ncnn model.
|
||||
[merge_output] merge all output yolo layers into one, enabled by default.
|
||||
```
|
||||
|
||||
## Example
|
||||
|
||||
### 1. Convert yolov4-tiny cfg and weights
|
||||
|
||||
Download pre-trained [yolov4-tiny.cfg](https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny.cfg) and [yolov4-tiny.weights](https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights) or with your own trained weight.
|
||||
|
||||
Convert cfg and weights:
|
||||
```
|
||||
./darknet2ncnn yolov4-tiny.cfg yolov4-tiny.weights yolov4-tiny.param yolov4-tiny.bin 1
|
||||
```
|
||||
|
||||
If succeeded, the output would be:
|
||||
```
|
||||
Loading cfg...
|
||||
WARNING: The ignore_thresh=0.700000 of yolo0 is too high. An alternative value 0.25 is written instead.
|
||||
WARNING: The ignore_thresh=0.700000 of yolo1 is too high. An alternative value 0.25 is written instead.
|
||||
Loading weights...
|
||||
Converting model...
|
||||
83 layers, 91 blobs generated.
|
||||
NOTE: The input of darknet uses: mean_vals=0 and norm_vals=1/255.f.
|
||||
NOTE: Remember to use ncnnoptimize for better performance.
|
||||
```
|
||||
|
||||
### 2. Optimize graphic
|
||||
|
||||
```
|
||||
./ncnnoptimize yolov4-tiny.param yolov4-tiny.bin yolov4-tiny-opt.param yolov4-tiny-opt.bin 0
|
||||
```
|
||||
|
||||
### 3. Test
|
||||
|
||||
build examples/yolov4.cpp and test with:
|
||||
|
||||
```
|
||||
./yolov4 dog.jpg
|
||||
```
|
||||
|
||||
The result will be:
|
||||
|
||||

|
||||
|
||||
|
||||
## How to run with benchncnn
|
||||
|
||||
Set 2=0.3 for Yolov3DetectionOutput layer.
|
||||
|
||||
964
3rdparty/ncnn/tools/darknet/darknet2ncnn.cpp
vendored
Normal file
964
3rdparty/ncnn/tools/darknet/darknet2ncnn.cpp
vendored
Normal file
@@ -0,0 +1,964 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <algorithm>
|
||||
#include <assert.h>
|
||||
#include <cctype>
|
||||
#include <deque>
|
||||
#include <fstream>
|
||||
#include <iostream>
|
||||
#include <locale>
|
||||
#include <sstream>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <string>
|
||||
#include <unordered_map>
|
||||
#include <vector>
|
||||
|
||||
#define OUTPUT_LAYER_MAP 0 //enable this to generate darknet style layer output
|
||||
|
||||
void file_error(const char* s)
|
||||
{
|
||||
fprintf(stderr, "Couldn't open file: %s\n", s);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
void fread_or_error(void* buffer, size_t size, size_t count, FILE* fp, const char* s)
|
||||
{
|
||||
if (count != fread(buffer, size, count, fp))
|
||||
{
|
||||
fprintf(stderr, "Couldn't read from file: %s\n", s);
|
||||
fclose(fp);
|
||||
assert(0);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
}
|
||||
|
||||
void error(const char* s)
|
||||
{
|
||||
perror(s);
|
||||
assert(0);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
typedef struct Section
|
||||
{
|
||||
std::string name;
|
||||
int line_number = -1;
|
||||
int original_layer_count;
|
||||
|
||||
std::unordered_map<std::string, std::string> options;
|
||||
int w = 416, h = 416, c = 3, inputs = 256, letter_box = 0;
|
||||
int out_w, out_h, out_c;
|
||||
int batch_normalize = 0, filters = 1, size = 1, groups = 1, stride = 1, padding = -1, pad = 0, dilation = 1;
|
||||
std::string activation;
|
||||
int from, reverse;
|
||||
std::vector<int> layers, mask, anchors;
|
||||
int group_id = -1;
|
||||
int classes = 0, num = 0;
|
||||
float ignore_thresh = 0.45f, scale_x_y = 1.f;
|
||||
|
||||
std::vector<float> weights, bias, scales, rolling_mean, rolling_variance;
|
||||
|
||||
std::string layer_type, layer_name;
|
||||
std::vector<std::string> input_blobs, output_blobs;
|
||||
std::vector<std::string> real_output_blobs;
|
||||
std::vector<std::string> param;
|
||||
} Section;
|
||||
|
||||
static inline std::string& trim(std::string& s)
|
||||
{
|
||||
s.erase(s.begin(), std::find_if(s.begin(), s.end(), [](int ch) {
|
||||
return !std::isspace(ch);
|
||||
}));
|
||||
s.erase(std::find_if(s.rbegin(), s.rend(), [](int ch) {
|
||||
return !std::isspace(ch);
|
||||
}).base(),
|
||||
s.end());
|
||||
return s;
|
||||
}
|
||||
|
||||
typedef enum FIELD_TYPE
|
||||
{
|
||||
INT,
|
||||
FLOAT,
|
||||
IARRAY,
|
||||
FARRAY,
|
||||
STRING,
|
||||
UNSUPPORTED
|
||||
} FIELD_TYPE;
|
||||
|
||||
typedef struct Section_Field
|
||||
{
|
||||
const char* name;
|
||||
FIELD_TYPE type;
|
||||
size_t offset;
|
||||
} Section_Field;
|
||||
|
||||
#define FIELD_OFFSET(c) ((size_t) & (((Section*)0)->c))
|
||||
|
||||
int yolo_layer_count = 0;
|
||||
bool letter_box_enabled = false;
|
||||
|
||||
std::vector<std::string> split(const std::string& s, char delimiter)
|
||||
{
|
||||
std::vector<std::string> tokens;
|
||||
std::string token;
|
||||
std::istringstream tokenStream(s);
|
||||
while (std::getline(tokenStream, token, delimiter))
|
||||
{
|
||||
tokens.push_back(token);
|
||||
}
|
||||
return tokens;
|
||||
}
|
||||
|
||||
template<typename... Args>
|
||||
std::string format(const char* fmt, Args... args)
|
||||
{
|
||||
size_t size = snprintf(nullptr, 0, fmt, args...);
|
||||
std::string buf;
|
||||
buf.reserve(size + 1);
|
||||
buf.resize(size);
|
||||
snprintf(&buf[0], size + 1, fmt, args...);
|
||||
return buf;
|
||||
}
|
||||
|
||||
void update_field(Section* section, std::string key, std::string value)
|
||||
{
|
||||
static const Section_Field fields[] = {
|
||||
//net
|
||||
{"width", INT, FIELD_OFFSET(w)},
|
||||
{"height", INT, FIELD_OFFSET(h)},
|
||||
{"channels", INT, FIELD_OFFSET(c)},
|
||||
{"inputs", INT, FIELD_OFFSET(inputs)},
|
||||
{"letter_box", INT, FIELD_OFFSET(letter_box)},
|
||||
//convolutional, upsample, maxpool
|
||||
{"batch_normalize", INT, FIELD_OFFSET(batch_normalize)},
|
||||
{"filters", INT, FIELD_OFFSET(filters)},
|
||||
{"size", INT, FIELD_OFFSET(size)},
|
||||
{"groups", INT, FIELD_OFFSET(groups)},
|
||||
{"stride", INT, FIELD_OFFSET(stride)},
|
||||
{"padding", INT, FIELD_OFFSET(padding)},
|
||||
{"pad", INT, FIELD_OFFSET(pad)},
|
||||
{"dilation", INT, FIELD_OFFSET(dilation)},
|
||||
{"activation", STRING, FIELD_OFFSET(activation)},
|
||||
//shortcut
|
||||
{"from", INT, FIELD_OFFSET(from)},
|
||||
{"reverse", INT, FIELD_OFFSET(reverse)},
|
||||
//route
|
||||
{"layers", IARRAY, FIELD_OFFSET(layers)},
|
||||
{"group_id", INT, FIELD_OFFSET(group_id)},
|
||||
//yolo
|
||||
{"mask", IARRAY, FIELD_OFFSET(mask)},
|
||||
{"anchors", IARRAY, FIELD_OFFSET(anchors)},
|
||||
{"classes", INT, FIELD_OFFSET(classes)},
|
||||
{"num", INT, FIELD_OFFSET(num)},
|
||||
{"ignore_thresh", FLOAT, FIELD_OFFSET(ignore_thresh)},
|
||||
{"scale_x_y", FLOAT, FIELD_OFFSET(scale_x_y)},
|
||||
};
|
||||
|
||||
for (size_t i = 0; i < sizeof(fields) / sizeof(fields[0]); i++)
|
||||
{
|
||||
auto f = fields[i];
|
||||
if (key != f.name)
|
||||
continue;
|
||||
char* addr = ((char*)section) + f.offset;
|
||||
switch (f.type)
|
||||
{
|
||||
case INT:
|
||||
*(int*)(addr) = std::stoi(value);
|
||||
return;
|
||||
|
||||
case FLOAT:
|
||||
*(float*)(addr) = std::stof(value);
|
||||
return;
|
||||
|
||||
case IARRAY:
|
||||
for (auto v : split(value, ','))
|
||||
reinterpret_cast<std::vector<int>*>(addr)->push_back(std::stoi(v));
|
||||
return;
|
||||
|
||||
case FARRAY:
|
||||
for (auto v : split(value, ','))
|
||||
reinterpret_cast<std::vector<float>*>(addr)->push_back(std::stof(v));
|
||||
return;
|
||||
|
||||
case STRING:
|
||||
*reinterpret_cast<std::string*>(addr) = value;
|
||||
return;
|
||||
|
||||
case UNSUPPORTED:
|
||||
printf("unsupported option: %s\n", key.c_str());
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void load_cfg(const char* filename, std::deque<Section*>& dnet)
|
||||
{
|
||||
std::string line;
|
||||
std::ifstream icfg(filename, std::ifstream::in);
|
||||
if (!icfg.good())
|
||||
{
|
||||
fprintf(stderr, "Couldn't cfg open file: %s\n", filename);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
Section* section = NULL;
|
||||
size_t pos;
|
||||
int section_count = 0, line_count = 0;
|
||||
while (!icfg.eof())
|
||||
{
|
||||
line_count++;
|
||||
std::getline(icfg, line);
|
||||
trim(line);
|
||||
if (line.length() == 0 || line.at(0) == '#')
|
||||
continue;
|
||||
if (line.at(0) == '[' && line.at(line.length() - 1) == ']')
|
||||
{
|
||||
line = line.substr(1, line.length() - 2);
|
||||
section = new Section;
|
||||
section->name = line;
|
||||
section->line_number = line_count;
|
||||
section->original_layer_count = section_count++;
|
||||
dnet.push_back(section);
|
||||
}
|
||||
else if ((pos = line.find_first_of('=')) != std::string::npos)
|
||||
{
|
||||
std::string key = line.substr(0, pos);
|
||||
std::string value = line.substr(pos + 1, line.length() - 1);
|
||||
section->options[trim(key)] = trim(value);
|
||||
update_field(section, key, value);
|
||||
}
|
||||
}
|
||||
|
||||
icfg.close();
|
||||
}
|
||||
|
||||
Section* get_original_section(std::deque<Section*>& dnet, int count, int offset)
|
||||
{
|
||||
if (offset >= 0)
|
||||
count = offset + 1;
|
||||
else
|
||||
count += offset;
|
||||
for (auto s : dnet)
|
||||
if (s->original_layer_count == count)
|
||||
return s;
|
||||
return dnet[0];
|
||||
}
|
||||
|
||||
template<typename T>
|
||||
std::string array_to_float_string(std::vector<T> vec)
|
||||
{
|
||||
std::string ret;
|
||||
for (size_t i = 0; i < vec.size(); i++)
|
||||
ret.append(format(",%f", (float)vec[i]));
|
||||
return ret;
|
||||
}
|
||||
|
||||
Section* get_section_by_output_blob(std::deque<Section*>& dnet, std::string blob)
|
||||
{
|
||||
for (auto s : dnet)
|
||||
for (auto b : s->output_blobs)
|
||||
if (b == blob)
|
||||
return s;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
std::vector<Section*> get_sections_by_input_blob(std::deque<Section*>& dnet, std::string blob)
|
||||
{
|
||||
std::vector<Section*> ret;
|
||||
for (auto s : dnet)
|
||||
for (auto b : s->input_blobs)
|
||||
if (b == blob)
|
||||
ret.push_back(s);
|
||||
return ret;
|
||||
}
|
||||
|
||||
void addActivationLayer(Section* s, std::deque<Section*>::iterator& it, std::deque<Section*>& dnet)
|
||||
{
|
||||
Section* act = new Section;
|
||||
|
||||
if (s->activation == "relu")
|
||||
{
|
||||
act->layer_type = "ReLU";
|
||||
act->param.push_back("0=0");
|
||||
}
|
||||
else if (s->activation == "leaky")
|
||||
{
|
||||
act->layer_type = "ReLU";
|
||||
act->param.push_back("0=0.1");
|
||||
}
|
||||
else if (s->activation == "mish")
|
||||
act->layer_type = "Mish";
|
||||
else if (s->activation == "logistic")
|
||||
act->layer_type = "Sigmoid";
|
||||
else if (s->activation == "swish")
|
||||
act->layer_type = "Swish";
|
||||
|
||||
if (s->batch_normalize)
|
||||
act->layer_name = s->layer_name + "_bn";
|
||||
else
|
||||
act->layer_name = s->layer_name;
|
||||
act->h = s->out_h;
|
||||
act->w = s->out_w;
|
||||
act->c = s->out_c;
|
||||
act->out_h = s->out_h;
|
||||
act->out_w = s->out_w;
|
||||
act->out_c = s->out_c;
|
||||
act->layer_name += "_" + s->activation;
|
||||
act->input_blobs = s->real_output_blobs;
|
||||
act->output_blobs.push_back(act->layer_name);
|
||||
|
||||
s->real_output_blobs = act->real_output_blobs = act->output_blobs;
|
||||
it = dnet.insert(it + 1, act);
|
||||
}
|
||||
|
||||
void parse_cfg(std::deque<Section*>& dnet, int merge_output)
|
||||
{
|
||||
int input_w = 416, input_h = 416;
|
||||
int yolo_count = 0;
|
||||
std::vector<Section*> yolo_layers;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf(" layer filters size/strd(dil) input output\n");
|
||||
#endif
|
||||
for (auto it = dnet.begin(); it != dnet.end(); it++)
|
||||
{
|
||||
auto s = *it;
|
||||
if (s->line_number < 0)
|
||||
continue;
|
||||
|
||||
auto p = get_original_section(dnet, s->original_layer_count, -1);
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
if (s->original_layer_count > 0)
|
||||
printf("%4d ", s->original_layer_count - 1);
|
||||
#endif
|
||||
|
||||
s->layer_name = format("%d_%d", s->original_layer_count - 1, s->line_number);
|
||||
s->input_blobs = p->real_output_blobs;
|
||||
s->output_blobs.push_back(s->layer_name);
|
||||
s->real_output_blobs = s->output_blobs;
|
||||
|
||||
if (s->name == "net")
|
||||
{
|
||||
if (s->letter_box)
|
||||
{
|
||||
fprintf(stderr, "WARNING: letter_box enabled.\n");
|
||||
letter_box_enabled = true;
|
||||
}
|
||||
|
||||
s->out_h = s->h;
|
||||
s->out_w = s->w;
|
||||
s->out_c = s->c;
|
||||
input_h = s->h;
|
||||
input_w = s->w;
|
||||
|
||||
s->layer_type = "Input";
|
||||
s->layer_name = "data";
|
||||
s->input_blobs.clear();
|
||||
s->output_blobs.clear();
|
||||
s->output_blobs.push_back("data");
|
||||
s->real_output_blobs = s->output_blobs;
|
||||
s->param.push_back(format("0=%d", s->w));
|
||||
s->param.push_back(format("1=%d", s->h));
|
||||
s->param.push_back(format("2=%d", s->c));
|
||||
}
|
||||
else if (s->name == "convolutional")
|
||||
{
|
||||
if (s->pad)
|
||||
s->padding = s->size / 2;
|
||||
if (s->padding == -1)
|
||||
s->padding = 0;
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = (s->h + 2 * s->padding - s->size) / s->stride + 1;
|
||||
s->out_w = (s->w + 2 * s->padding - s->size) / s->stride + 1;
|
||||
s->out_c = s->filters;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
if (s->groups == 1)
|
||||
printf("conv %5d %2d x%2d/%2d ", s->filters, s->size, s->size, s->stride);
|
||||
else
|
||||
printf("conv %5d/%4d %2d x%2d/%2d ", s->filters, s->groups, s->size, s->size, s->stride);
|
||||
printf("%4d x%4d x%4d -> %4d x%4d x%4d\n", s->h, s->w, s->c, s->out_h, s->out_w, s->out_c);
|
||||
#endif
|
||||
|
||||
if (s->groups == 1)
|
||||
s->layer_type = "Convolution";
|
||||
else
|
||||
s->layer_type = "ConvolutionDepthWise";
|
||||
s->param.push_back(format("0=%d", s->filters)); //num_output
|
||||
s->param.push_back(format("1=%d", s->size)); //kernel_w
|
||||
s->param.push_back(format("2=%d", s->dilation)); //dilation_w
|
||||
s->param.push_back(format("3=%d", s->stride)); //stride_w
|
||||
s->param.push_back(format("4=%d", s->padding)); //pad_left
|
||||
|
||||
if (s->batch_normalize)
|
||||
{
|
||||
s->param.push_back("5=0"); //bias_term
|
||||
|
||||
Section* bn = new Section;
|
||||
bn->layer_type = "BatchNorm";
|
||||
bn->layer_name = s->layer_name + "_bn";
|
||||
bn->h = s->out_h;
|
||||
bn->w = s->out_w;
|
||||
bn->c = s->out_c;
|
||||
bn->out_h = s->out_h;
|
||||
bn->out_w = s->out_w;
|
||||
bn->out_c = s->out_c;
|
||||
bn->input_blobs = s->real_output_blobs;
|
||||
bn->output_blobs.push_back(bn->layer_name);
|
||||
bn->param.push_back(format("0=%d", s->filters)); //channels
|
||||
bn->param.push_back("1=.00001"); //eps
|
||||
|
||||
s->real_output_blobs = bn->real_output_blobs = bn->output_blobs;
|
||||
it = dnet.insert(it + 1, bn);
|
||||
}
|
||||
else
|
||||
{
|
||||
s->param.push_back("5=1"); //bias_term
|
||||
}
|
||||
s->param.push_back(format("6=%d", s->c * s->size * s->size * s->filters / s->groups)); //weight_data_size
|
||||
|
||||
if (s->groups > 1)
|
||||
s->param.push_back(format("7=%d", s->groups)); //stride_w
|
||||
|
||||
if (s->activation.size() > 0)
|
||||
{
|
||||
if (s->activation == "relu" || s->activation == "leaky" || s->activation == "mish" || s->activation == "logistic" || s->activation == "swish")
|
||||
{
|
||||
addActivationLayer(s, it, dnet);
|
||||
}
|
||||
else if (s->activation != "linear")
|
||||
error(format("Unsupported convolutional activation type: %s", s->activation.c_str()).c_str());
|
||||
}
|
||||
}
|
||||
else if (s->name == "shortcut")
|
||||
{
|
||||
auto q = get_original_section(dnet, s->original_layer_count, s->from);
|
||||
if (p->out_h != q->out_h || p->out_w != q->out_w)
|
||||
error("shortcut dim not match");
|
||||
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = s->h;
|
||||
s->out_w = s->w;
|
||||
s->out_c = p->out_c;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("Shortcut Layer: %d, ", q->original_layer_count - 1);
|
||||
printf("outputs: %4d x%4d x%4d\n", s->out_h, s->out_w, s->out_c);
|
||||
if (p->out_c != q->out_c)
|
||||
printf("(%4d x%4d x%4d) + (%4d x%4d x%4d)\n", p->out_h, p->out_w, p->out_c,
|
||||
q->out_h, q->out_w, q->out_c);
|
||||
#endif
|
||||
|
||||
if (s->activation.size() > 0)
|
||||
{
|
||||
if (s->activation == "relu" || s->activation == "leaky" || s->activation == "mish" || s->activation == "logistic" || s->activation == "swish")
|
||||
{
|
||||
addActivationLayer(s, it, dnet);
|
||||
}
|
||||
else if (s->activation != "linear")
|
||||
error(format("Unsupported convolutional activation type: %s", s->activation.c_str()).c_str());
|
||||
}
|
||||
|
||||
s->layer_type = "Eltwise";
|
||||
s->input_blobs.clear();
|
||||
s->input_blobs.push_back(p->real_output_blobs[0]);
|
||||
s->input_blobs.push_back(q->real_output_blobs[0]);
|
||||
|
||||
s->param.push_back("0=1"); //op_type=Operation_SUM
|
||||
}
|
||||
else if (s->name == "maxpool")
|
||||
{
|
||||
if (s->padding == -1)
|
||||
s->padding = s->size - 1;
|
||||
int pad = s->padding / 2;
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = (s->h + s->padding - s->size) / s->stride + 1;
|
||||
s->out_w = (s->w + s->padding - s->size) / s->stride + 1;
|
||||
s->out_c = s->c;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("max %2d x%2d/%2d ", s->size, s->size, s->stride);
|
||||
printf("%4d x%4d x%4d -> %4d x%4d x%4d\n", s->h, s->w, s->c, s->out_h, s->out_w, s->out_c);
|
||||
#endif
|
||||
|
||||
s->layer_type = "Pooling";
|
||||
s->param.push_back("0=0"); //pooling_type=PoolMethod_MAX
|
||||
s->param.push_back(format("1=%d", s->size)); //kernel_w
|
||||
s->param.push_back(format("2=%d", s->stride)); //stride_w
|
||||
s->param.push_back("5=1"); //pad_mode=SAME_UPPER
|
||||
s->param.push_back(format("3=%d", pad)); //pad_left
|
||||
s->param.push_back(format("13=%d", pad)); //pad_top
|
||||
s->param.push_back(format("14=%d", s->padding - pad)); //pad_right
|
||||
s->param.push_back(format("15=%d", s->padding - pad)); //pad_bottom
|
||||
}
|
||||
else if (s->name == "avgpool")
|
||||
{
|
||||
if (s->padding == -1)
|
||||
s->padding = s->size - 1;
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = 1;
|
||||
s->out_w = s->out_h;
|
||||
s->out_c = s->c;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("avg %4d x%4d x%4d -> %4d\n", s->h, s->w, s->c, s->out_c);
|
||||
#endif
|
||||
|
||||
s->layer_type = "Pooling";
|
||||
s->param.push_back("0=1"); //pooling_type=PoolMethod_AVE
|
||||
s->param.push_back("4=1"); //global_pooling
|
||||
|
||||
Section* r = new Section;
|
||||
r->layer_type = "Reshape";
|
||||
r->layer_name = s->layer_name + "_reshape";
|
||||
r->h = s->out_h;
|
||||
r->w = s->out_w;
|
||||
r->c = s->out_c;
|
||||
r->out_h = 1;
|
||||
r->out_w = 1;
|
||||
r->out_c = r->h * r->w * r->c;
|
||||
r->input_blobs.push_back(s->output_blobs[0]);
|
||||
r->output_blobs.push_back(r->layer_name);
|
||||
r->param.push_back("0=1"); //w
|
||||
r->param.push_back("1=1"); //h
|
||||
r->param.push_back(format("2=%d", r->out_c)); //c
|
||||
|
||||
s->real_output_blobs.clear();
|
||||
s->real_output_blobs.push_back(r->layer_name);
|
||||
|
||||
it = dnet.insert(it + 1, r);
|
||||
}
|
||||
else if (s->name == "sam")
|
||||
{
|
||||
auto q = get_original_section(dnet, s->original_layer_count, s->from);
|
||||
if (p->out_w != q->out_w || p->out_h != q->out_h || p->out_c != q->out_c)
|
||||
error("sam layer dimension not match");
|
||||
|
||||
s->h = q->out_h;
|
||||
s->w = q->out_w;
|
||||
s->c = q->out_c;
|
||||
s->out_h = s->h;
|
||||
s->out_w = s->w;
|
||||
s->out_c = q->out_c;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("scale Layer: %d\n", q->original_layer_count - 1);
|
||||
#endif
|
||||
|
||||
s->layer_type = "BinaryOp";
|
||||
s->input_blobs.clear();
|
||||
s->input_blobs.push_back(q->real_output_blobs[0]);
|
||||
s->input_blobs.push_back(p->real_output_blobs[0]);
|
||||
s->param.push_back("0=2"); //op_type=Operation_MUL
|
||||
}
|
||||
else if (s->name == "scale_channels")
|
||||
{
|
||||
auto q = get_original_section(dnet, s->original_layer_count, s->from);
|
||||
if (p->out_c != q->out_c)
|
||||
error("scale channels not match");
|
||||
|
||||
s->h = q->out_h;
|
||||
s->w = q->out_w;
|
||||
s->c = q->out_c;
|
||||
s->out_h = s->h;
|
||||
s->out_w = s->w;
|
||||
s->out_c = q->out_c;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("scale Layer: %d\n", q->original_layer_count - 1);
|
||||
#endif
|
||||
|
||||
if (s->activation.size() > 0 && s->activation != "linear")
|
||||
error(format("Unsupported scale_channels activation type: %s", s->activation.c_str()).c_str());
|
||||
|
||||
s->layer_type = "BinaryOp";
|
||||
s->input_blobs.clear();
|
||||
s->input_blobs.push_back(q->real_output_blobs[0]);
|
||||
s->input_blobs.push_back(p->real_output_blobs[0]);
|
||||
s->param.push_back("0=2"); //op_type=Operation_MUL
|
||||
}
|
||||
else if (s->name == "route")
|
||||
{
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("route ");
|
||||
#endif
|
||||
s->out_c = 0;
|
||||
s->input_blobs.clear();
|
||||
for (int l : s->layers)
|
||||
{
|
||||
auto q = get_original_section(dnet, s->original_layer_count, l);
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("%d ", q->original_layer_count - 1);
|
||||
#endif
|
||||
s->out_h = q->out_h;
|
||||
s->out_w = q->out_w;
|
||||
s->out_c += q->out_c;
|
||||
|
||||
for (auto blob : q->real_output_blobs)
|
||||
s->input_blobs.push_back(blob);
|
||||
}
|
||||
if (s->input_blobs.size() == 1)
|
||||
{
|
||||
if (s->groups <= 1 || s->group_id == -1)
|
||||
s->layer_type = "Noop";
|
||||
else
|
||||
{
|
||||
s->out_c /= s->groups;
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("%31d/%d -> %4d x%4d x%4d", 1, s->groups, s->out_w, s->out_h, s->out_c);
|
||||
#endif
|
||||
|
||||
s->layer_type = "Crop";
|
||||
s->param.push_back(format("2=%d", s->out_c * s->group_id));
|
||||
s->param.push_back(format("3=%d", s->out_w));
|
||||
s->param.push_back(format("4=%d", s->out_h));
|
||||
s->param.push_back(format("5=%d", s->out_c));
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("%30c-> %4d x%4d x%4d", ' ', s->out_w, s->out_h, s->out_c);
|
||||
#endif
|
||||
s->layer_type = "Concat";
|
||||
}
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("\n");
|
||||
#endif
|
||||
}
|
||||
else if (s->name == "upsample")
|
||||
{
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = s->h * s->stride;
|
||||
s->out_w = s->w * s->stride;
|
||||
s->out_c = s->c;
|
||||
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("upsample %2dx ", s->stride);
|
||||
printf("%4d x%4d x%4d -> %4d x%4d x%4d\n", s->h, s->w, s->c, s->out_h, s->out_w, s->out_c);
|
||||
#endif
|
||||
s->layer_type = "Interp";
|
||||
s->param.push_back("0=1"); //resize_type=nearest
|
||||
s->param.push_back("1=2.f"); //height_scale
|
||||
s->param.push_back("2=2.f"); //width_scale
|
||||
}
|
||||
else if (s->name == "yolo")
|
||||
{
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("yolo%d\n", yolo_count);
|
||||
#endif
|
||||
|
||||
if (s->ignore_thresh > 0.25)
|
||||
{
|
||||
fprintf(stderr, "WARNING: The ignore_thresh=%f of yolo%d is too high. "
|
||||
"An alternative value 0.25 is written instead.\n",
|
||||
s->ignore_thresh, yolo_count);
|
||||
s->ignore_thresh = 0.25;
|
||||
}
|
||||
|
||||
s->layer_type = "Yolov3DetectionOutput";
|
||||
s->layer_name = format("yolo%d", yolo_count++);
|
||||
s->output_blobs[0] = s->layer_name;
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = s->h;
|
||||
s->out_w = s->w;
|
||||
s->out_c = s->c * (int)s->mask.size();
|
||||
s->param.push_back(format("0=%d", s->classes)); //num_class
|
||||
s->param.push_back(format("1=%d", s->mask.size())); //num_box
|
||||
s->param.push_back(format("2=%f", s->ignore_thresh)); //confidence_threshold
|
||||
s->param.push_back(format("-23304=%d%s", s->anchors.size(), array_to_float_string(s->anchors).c_str())); //biases
|
||||
s->param.push_back(format("-23305=%d%s", s->mask.size(), array_to_float_string(s->mask).c_str())); //mask
|
||||
s->param.push_back(format("-23306=2,%f,%f", input_w * s->scale_x_y / s->w, input_h * s->scale_x_y / s->h)); //biases_index
|
||||
|
||||
yolo_layer_count++;
|
||||
yolo_layers.push_back(s);
|
||||
}
|
||||
else if (s->name == "dropout")
|
||||
{
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("dropout\n");
|
||||
#endif
|
||||
s->h = p->out_h;
|
||||
s->w = p->out_w;
|
||||
s->c = p->out_c;
|
||||
s->out_h = s->h;
|
||||
s->out_w = s->w;
|
||||
s->out_c = p->out_c;
|
||||
s->layer_type = "Noop";
|
||||
}
|
||||
else
|
||||
{
|
||||
#if OUTPUT_LAYER_MAP
|
||||
printf("%-8s (unsupported)\n", s->name.c_str());
|
||||
#endif
|
||||
}
|
||||
}
|
||||
|
||||
for (auto it = dnet.begin(); it != dnet.end(); it++)
|
||||
{
|
||||
auto s = *it;
|
||||
for (size_t i = 0; i < s->input_blobs.size(); i++)
|
||||
{
|
||||
auto p = get_section_by_output_blob(dnet, s->input_blobs[i]);
|
||||
if (p == NULL || p->layer_type != "Noop")
|
||||
continue;
|
||||
s->input_blobs[i] = p->input_blobs[0];
|
||||
}
|
||||
}
|
||||
|
||||
for (auto it = dnet.begin(); it != dnet.end();)
|
||||
if ((*it)->layer_type == "Noop")
|
||||
it = dnet.erase(it);
|
||||
else
|
||||
it++;
|
||||
|
||||
for (auto it = dnet.begin(); it != dnet.end(); it++)
|
||||
{
|
||||
auto s = *it;
|
||||
for (std::string output_name : s->output_blobs)
|
||||
{
|
||||
auto q = get_sections_by_input_blob(dnet, output_name);
|
||||
if (q.size() <= 1 || s->layer_type == "Split")
|
||||
continue;
|
||||
Section* p = new Section;
|
||||
p->layer_type = "Split";
|
||||
p->layer_name = s->layer_name + "_split";
|
||||
p->w = s->w;
|
||||
p->h = s->h;
|
||||
p->c = s->c;
|
||||
p->out_w = s->out_w;
|
||||
p->out_h = s->out_h;
|
||||
p->out_c = s->out_c;
|
||||
p->input_blobs.push_back(output_name);
|
||||
for (size_t i = 0; i < q.size(); i++)
|
||||
{
|
||||
std::string new_output_name = p->layer_name + "_" + std::to_string(i);
|
||||
p->output_blobs.push_back(new_output_name);
|
||||
|
||||
for (size_t j = 0; j < q[i]->input_blobs.size(); j++)
|
||||
if (q[i]->input_blobs[j] == output_name)
|
||||
q[i]->input_blobs[j] = new_output_name;
|
||||
}
|
||||
it = dnet.insert(it + 1, p);
|
||||
}
|
||||
}
|
||||
|
||||
if (merge_output && yolo_layer_count > 0)
|
||||
{
|
||||
std::vector<int> masks;
|
||||
std::vector<float> scale_x_y;
|
||||
|
||||
Section* s = new Section;
|
||||
s->classes = yolo_layers[0]->classes;
|
||||
s->anchors = yolo_layers[0]->anchors;
|
||||
s->mask = yolo_layers[0]->mask;
|
||||
|
||||
for (auto p : yolo_layers)
|
||||
{
|
||||
if (s->classes != p->classes)
|
||||
error("yolo object classes number not match, output cannot be merged.");
|
||||
|
||||
if (s->anchors.size() != p->anchors.size())
|
||||
error("yolo layer anchor count not match, output cannot be merged.");
|
||||
|
||||
for (size_t i = 0; i < s->anchors.size(); i++)
|
||||
if (s->anchors[i] != p->anchors[i])
|
||||
error("yolo anchor size not match, output cannot be merged.");
|
||||
|
||||
if (s->ignore_thresh > p->ignore_thresh)
|
||||
s->ignore_thresh = p->ignore_thresh;
|
||||
|
||||
for (int m : p->mask)
|
||||
masks.push_back(m);
|
||||
|
||||
scale_x_y.push_back(input_w * p->scale_x_y / p->w);
|
||||
s->input_blobs.push_back(p->input_blobs[0]);
|
||||
}
|
||||
|
||||
for (auto it = dnet.begin(); it != dnet.end();)
|
||||
if ((*it)->name == "yolo")
|
||||
it = dnet.erase(it);
|
||||
else
|
||||
it++;
|
||||
|
||||
s->layer_type = "Yolov3DetectionOutput";
|
||||
s->layer_name = "detection_out";
|
||||
s->output_blobs.push_back("output");
|
||||
s->param.push_back(format("0=%d", s->classes)); //num_class
|
||||
s->param.push_back(format("1=%d", s->mask.size())); //num_box
|
||||
s->param.push_back(format("2=%f", s->ignore_thresh)); //confidence_threshold
|
||||
s->param.push_back(format("-23304=%d%s", s->anchors.size(), array_to_float_string(s->anchors).c_str())); //biases
|
||||
s->param.push_back(format("-23305=%d%s", masks.size(), array_to_float_string(masks).c_str())); //mask
|
||||
s->param.push_back(format("-23306=%d%s", scale_x_y.size(), array_to_float_string(scale_x_y).c_str())); //biases_index
|
||||
|
||||
dnet.push_back(s);
|
||||
}
|
||||
}
|
||||
|
||||
void read_to(std::vector<float>& vec, size_t size, FILE* fp)
|
||||
{
|
||||
vec.resize(size);
|
||||
size_t read_size = fread(&vec[0], sizeof(float), size, fp);
|
||||
if (read_size != size)
|
||||
error("\n Warning: Unexpected end of wights-file!\n");
|
||||
}
|
||||
|
||||
void load_weights(const char* filename, std::deque<Section*>& dnet)
|
||||
{
|
||||
FILE* fp = fopen(filename, "rb");
|
||||
if (fp == NULL)
|
||||
file_error(filename);
|
||||
|
||||
int major, minor, revision;
|
||||
|
||||
fread_or_error(&major, sizeof(int), 1, fp, filename);
|
||||
fread_or_error(&minor, sizeof(int), 1, fp, filename);
|
||||
fread_or_error(&revision, sizeof(int), 1, fp, filename);
|
||||
if ((major * 10 + minor) >= 2)
|
||||
{
|
||||
uint64_t iseen = 0;
|
||||
fread_or_error(&iseen, sizeof(uint64_t), 1, fp, filename);
|
||||
}
|
||||
else
|
||||
{
|
||||
uint32_t iseen = 0;
|
||||
fread_or_error(&iseen, sizeof(uint32_t), 1, fp, filename);
|
||||
}
|
||||
|
||||
for (auto s : dnet)
|
||||
{
|
||||
if (s->name == "convolutional")
|
||||
{
|
||||
read_to(s->bias, s->filters, fp);
|
||||
if (s->batch_normalize)
|
||||
{
|
||||
read_to(s->scales, s->filters, fp);
|
||||
read_to(s->rolling_mean, s->filters, fp);
|
||||
read_to(s->rolling_variance, s->filters, fp);
|
||||
}
|
||||
|
||||
if (s->layer_type == "Convolution")
|
||||
read_to(s->weights, (size_t)(s->c) * s->filters * s->size * s->size, fp);
|
||||
else if (s->layer_type == "ConvolutionDepthWise")
|
||||
read_to(s->weights, s->c * s->filters * s->size * s->size / s->groups, fp);
|
||||
}
|
||||
}
|
||||
|
||||
fclose(fp);
|
||||
}
|
||||
|
||||
int count_output_blob(std::deque<Section*>& dnet)
|
||||
{
|
||||
int count = 0;
|
||||
for (auto s : dnet)
|
||||
count += (int)s->output_blobs.size();
|
||||
return count;
|
||||
}
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
if (!(argc == 3 || argc == 5 || argc == 6))
|
||||
{
|
||||
fprintf(stderr, "Usage: %s [darknetcfg] [darknetweights] [ncnnparam] [ncnnbin] [merge_output]\n"
|
||||
"\t[darknetcfg] .cfg file of input darknet model.\n"
|
||||
"\t[darknetweights] .weights file of input darknet model.\n"
|
||||
"\t[cnnparam] .param file of output ncnn model.\n"
|
||||
"\t[ncnnbin] .bin file of output ncnn model.\n"
|
||||
"\t[merge_output] merge all output yolo layers into one, enabled by default.\n",
|
||||
argv[0]);
|
||||
return -1;
|
||||
}
|
||||
|
||||
const char* darknetcfg = argv[1];
|
||||
const char* darknetweights = argv[2];
|
||||
const char* ncnn_param = argc >= 5 ? argv[3] : "ncnn.param";
|
||||
const char* ncnn_bin = argc >= 5 ? argv[4] : "ncnn.bin";
|
||||
int merge_output = argc >= 6 ? atoi(argv[5]) : 1;
|
||||
|
||||
std::deque<Section*> dnet;
|
||||
|
||||
printf("Loading cfg...\n");
|
||||
load_cfg(darknetcfg, dnet);
|
||||
parse_cfg(dnet, merge_output);
|
||||
|
||||
printf("Loading weights...\n");
|
||||
load_weights(darknetweights, dnet);
|
||||
|
||||
FILE* pp = fopen(ncnn_param, "wb");
|
||||
if (pp == NULL)
|
||||
file_error(ncnn_param);
|
||||
|
||||
FILE* bp = fopen(ncnn_bin, "wb");
|
||||
if (bp == NULL)
|
||||
file_error(ncnn_bin);
|
||||
|
||||
printf("Converting model...\n");
|
||||
|
||||
fprintf(pp, "7767517\n");
|
||||
fprintf(pp, "%d %d\n", (int)dnet.size(), count_output_blob(dnet));
|
||||
|
||||
for (auto s : dnet)
|
||||
{
|
||||
fprintf(pp, "%-22s %-20s %d %d", s->layer_type.c_str(), s->layer_name.c_str(), (int)s->input_blobs.size(), (int)s->output_blobs.size());
|
||||
for (auto b : s->input_blobs)
|
||||
fprintf(pp, " %s", b.c_str());
|
||||
for (auto b : s->output_blobs)
|
||||
fprintf(pp, " %s", b.c_str());
|
||||
for (auto p : s->param)
|
||||
fprintf(pp, " %s", p.c_str());
|
||||
fprintf(pp, "\n");
|
||||
|
||||
if (s->name == "convolutional")
|
||||
{
|
||||
fseek(bp, 4, SEEK_CUR);
|
||||
if (s->weights.size() > 0)
|
||||
fwrite(&s->weights[0], sizeof(float), s->weights.size(), bp);
|
||||
if (s->scales.size() > 0)
|
||||
fwrite(&s->scales[0], sizeof(float), s->scales.size(), bp);
|
||||
if (s->rolling_mean.size() > 0)
|
||||
fwrite(&s->rolling_mean[0], sizeof(float), s->rolling_mean.size(), bp);
|
||||
if (s->rolling_variance.size() > 0)
|
||||
fwrite(&s->rolling_variance[0], sizeof(float), s->rolling_variance.size(), bp);
|
||||
if (s->bias.size() > 0)
|
||||
fwrite(&s->bias[0], sizeof(float), s->bias.size(), bp);
|
||||
}
|
||||
}
|
||||
fclose(pp);
|
||||
|
||||
printf("%d layers, %d blobs generated.\n", (int)dnet.size(), count_output_blob(dnet));
|
||||
printf("NOTE: The input of darknet uses: mean_vals=0 and norm_vals=1/255.f.\n");
|
||||
if (!merge_output)
|
||||
printf("NOTE: There are %d unmerged yolo output layer. Make sure all outputs are processed with nms.\n", yolo_layer_count);
|
||||
if (letter_box_enabled)
|
||||
printf("NOTE: Make sure your pre-processing and post-processing support letter_box.\n");
|
||||
printf("NOTE: Remember to use ncnnoptimize for better performance.\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
BIN
3rdparty/ncnn/tools/darknet/output.jpg
vendored
Normal file
BIN
3rdparty/ncnn/tools/darknet/output.jpg
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 181 KiB |
10
3rdparty/ncnn/tools/keras/readme.md
vendored
Normal file
10
3rdparty/ncnn/tools/keras/readme.md
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
## You can find keras2ncnn tools here
|
||||
|
||||
[https://github.com/MarsTechHAN/keras2ncnn](https://github.com/MarsTechHAN/keras2ncnn)
|
||||
[https://github.com/azeme1/keras2ncnn](https://github.com/azeme1/keras2ncnn)
|
||||
|
||||
----
|
||||
### From tensorflow 2.x, you can also export mlir and use mlir2ncnn which is maintained by the official.
|
||||
|
||||
The source code is located here: [https://github.com/Tencent/ncnn/tree/master/tools/mlir](https://github.com/Tencent/ncnn/tree/master/tools/mlir)
|
||||
For Chinese, you can refer the guide here [https://zhuanlan.zhihu.com/p/152535430](https://zhuanlan.zhihu.com/p/152535430)
|
||||
61
3rdparty/ncnn/tools/mlir/CMakeLists.txt
vendored
Normal file
61
3rdparty/ncnn/tools/mlir/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,61 @@
|
||||
project(mlir2ncnn)
|
||||
|
||||
cmake_minimum_required(VERSION 3.10)
|
||||
set(CMAKE_CXX_STANDARD 14)
|
||||
|
||||
set(LLVM_PROJECT_INSTALL_DIR "/home/nihui/osd/llvm-project/build/install" CACHE STRING "")
|
||||
|
||||
set(LLVM_DIR "${LLVM_PROJECT_INSTALL_DIR}/lib/cmake/llvm")
|
||||
find_package(LLVM REQUIRED)
|
||||
|
||||
set(MLIR_DIR "${LLVM_PROJECT_INSTALL_DIR}/lib/cmake/mlir")
|
||||
find_package(MLIR REQUIRED)
|
||||
|
||||
add_definitions(-fno-rtti -fno-exceptions)
|
||||
|
||||
include_directories("${LLVM_PROJECT_INSTALL_DIR}/include")
|
||||
|
||||
include_directories(${CMAKE_CURRENT_BINARY_DIR})
|
||||
|
||||
include(${LLVM_DIR}/TableGen.cmake)
|
||||
include(${MLIR_DIR}/AddMLIR.cmake)
|
||||
|
||||
set(LLVM_TARGET_DEFINITIONS tf_ops.td)
|
||||
mlir_tablegen(tf_all_ops.h.inc -gen-op-decls)
|
||||
mlir_tablegen(tf_all_ops.cc.inc -gen-op-defs)
|
||||
add_public_tablegen_target(tf_opsIncGen)
|
||||
|
||||
set(LLVM_TARGET_DEFINITIONS ncnn_ops.td)
|
||||
mlir_tablegen(ncnn_ops.h.inc -gen-op-decls)
|
||||
mlir_tablegen(ncnn_ops.cc.inc -gen-op-defs)
|
||||
add_public_tablegen_target(ncnn_opsIncGen)
|
||||
|
||||
set(LLVM_TARGET_DEFINITIONS ncnn_rewriter.td)
|
||||
mlir_tablegen(ncnn_rewriter.inc -gen-rewriters)
|
||||
add_public_tablegen_target(ncnn_rewriterIncGen)
|
||||
|
||||
add_executable(mlir2ncnn
|
||||
mlir2ncnn.cpp
|
||||
ncnn_dialect.cpp
|
||||
ncnn_rewriter.cpp
|
||||
tf_dialect.cpp
|
||||
tf_attributes.cc
|
||||
tf_types.cc
|
||||
)
|
||||
|
||||
add_dependencies(mlir2ncnn
|
||||
tf_opsIncGen
|
||||
ncnn_opsIncGen
|
||||
ncnn_rewriterIncGen
|
||||
)
|
||||
|
||||
target_link_libraries(mlir2ncnn
|
||||
MLIRIR
|
||||
MLIRDialect
|
||||
MLIRInferTypeOpInterface
|
||||
MLIRParser
|
||||
MLIRPass
|
||||
MLIRStandard
|
||||
MLIRTransforms
|
||||
)
|
||||
ncnn_install_tool(mlir2ncnn)
|
||||
13
3rdparty/ncnn/tools/mlir/fix_td.sh
vendored
Normal file
13
3rdparty/ncnn/tools/mlir/fix_td.sh
vendored
Normal file
@@ -0,0 +1,13 @@
|
||||
#!/bin/sh
|
||||
|
||||
# This dirty script eat td files :P
|
||||
# https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compiler/mlir/tensorflow/ir
|
||||
|
||||
sed -i 's!tensorflow/compiler/mlir/tensorflow/ir/!!g' *.td tf_traits.h tf_types.h tf_types.cc tf_attributes.cc
|
||||
|
||||
sed -i '/let hasCanonicalizer = 1;/d' *.td
|
||||
sed -i '/let hasFolder = 1;/d' *.td
|
||||
sed -i '/StringRef GetOptimalLayout(const RuntimeDevices& devices);/d' *.td
|
||||
sed -i '/LogicalResult UpdateDataFormat(StringRef data_format);/d' *.td
|
||||
sed -i '/LogicalResult FoldOperandsPermutation(ArrayRef<int64_t> permutation);/d' *.td
|
||||
sed -i '/Optional<ContractionFusion> GetContractionFusion();/d' *.td
|
||||
1819
3rdparty/ncnn/tools/mlir/mlir2ncnn.cpp
vendored
Normal file
1819
3rdparty/ncnn/tools/mlir/mlir2ncnn.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
41
3rdparty/ncnn/tools/mlir/ncnn_dialect.cpp
vendored
Normal file
41
3rdparty/ncnn/tools/mlir/ncnn_dialect.cpp
vendored
Normal file
@@ -0,0 +1,41 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "ncnn_dialect.h"
|
||||
|
||||
#include <mlir/IR/Builders.h>
|
||||
|
||||
namespace mlir {
|
||||
|
||||
namespace ncnn {
|
||||
|
||||
NCNNDialect::NCNNDialect(mlir::MLIRContext* context)
|
||||
: mlir::Dialect("ncnn", context, TypeID::get<NCNNDialect>())
|
||||
{
|
||||
addOperations<
|
||||
#define GET_OP_LIST
|
||||
#include "ncnn_ops.cc.inc"
|
||||
>();
|
||||
|
||||
// Support unknown operations because not all NCNN operations are
|
||||
// registered.
|
||||
allowUnknownOperations();
|
||||
}
|
||||
|
||||
} // namespace ncnn
|
||||
|
||||
#define GET_OP_CLASSES
|
||||
#include "ncnn_ops.cc.inc"
|
||||
|
||||
} // namespace mlir
|
||||
47
3rdparty/ncnn/tools/mlir/ncnn_dialect.h
vendored
Normal file
47
3rdparty/ncnn/tools/mlir/ncnn_dialect.h
vendored
Normal file
@@ -0,0 +1,47 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef NCNN_DIALECT_H
|
||||
#define NCNN_DIALECT_H
|
||||
|
||||
#include <mlir/IR/BuiltinTypes.h>
|
||||
#include <mlir/IR/Dialect.h>
|
||||
#include <mlir/Interfaces/SideEffectInterfaces.h>
|
||||
#include <mlir/Pass/Pass.h>
|
||||
|
||||
namespace mlir {
|
||||
|
||||
namespace ncnn {
|
||||
|
||||
class NCNNDialect : public mlir::Dialect
|
||||
{
|
||||
public:
|
||||
NCNNDialect(mlir::MLIRContext* context);
|
||||
|
||||
static StringRef getDialectNamespace()
|
||||
{
|
||||
return "ncnn";
|
||||
}
|
||||
};
|
||||
|
||||
std::unique_ptr<OperationPass<FuncOp> > createNCNNOptimizePass();
|
||||
|
||||
} // namespace ncnn
|
||||
|
||||
#define GET_OP_CLASSES
|
||||
#include "ncnn_ops.h.inc"
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
#endif // NCNN_DIALECT_H
|
||||
133
3rdparty/ncnn/tools/mlir/ncnn_ops.td
vendored
Normal file
133
3rdparty/ncnn/tools/mlir/ncnn_ops.td
vendored
Normal file
@@ -0,0 +1,133 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef NCNN_OPS_TD
|
||||
#define NCNN_OPS_TD
|
||||
|
||||
include "mlir/IR/OpBase.td"
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td"
|
||||
include "tf_op_base.td"
|
||||
|
||||
def NCNN_Dialect : Dialect {
|
||||
let name = "ncnn";
|
||||
let cppNamespace = "ncnn";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// NCNN op definitions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
class NCNN_Op<string mnemonic, list<OpTrait> traits = []> :
|
||||
Op<NCNN_Dialect, mnemonic, traits>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// NCNN operations
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def NCNN_KerasConv2DOp : NCNN_Op<"KerasConv2D", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x,
|
||||
F32Tensor:$weight,
|
||||
F32Tensor:$bias,
|
||||
|
||||
I64ArrayAttr:$strides,
|
||||
TF_AnyStrAttrOf<["SAME", "VALID", "EXPLICIT"]>:$padding,
|
||||
DefaultValuedAttr<I64ArrayAttr, "{}">:$explicit_paddings,
|
||||
DefaultValuedAttr<I64ArrayAttr, "{1, 1, 1, 1}">:$dilations
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
def NCNN_KerasDenseOp : NCNN_Op<"KerasDense", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x,
|
||||
F32Tensor:$weight,
|
||||
F32Tensor:$bias
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
def NCNN_KerasBatchNormOp : NCNN_Op<"KerasBatchNorm", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x,
|
||||
F32Tensor:$gamma,
|
||||
F32Tensor:$bias
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
def NCNN_BinaryOpOp : NCNN_Op<"BinaryOp", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x,
|
||||
I32Attr:$op_type,
|
||||
I32Attr:$with_scalar,
|
||||
F32Attr:$b
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
def NCNN_InstanceNormOp : NCNN_Op<"InstanceNorm", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x,
|
||||
F32Attr:$epsilon
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
def NCNN_InstanceNormAffineOp : NCNN_Op<"InstanceNormAffine", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x,
|
||||
F32Tensor:$gamma,
|
||||
F32Tensor:$beta,
|
||||
F32Attr:$epsilon
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
def NCNN_SwishOp : NCNN_Op<"Swish", [NoSideEffect]> {
|
||||
|
||||
let arguments = (ins
|
||||
F32Tensor:$x
|
||||
);
|
||||
|
||||
let results = (outs
|
||||
F32Tensor:$y
|
||||
);
|
||||
}
|
||||
|
||||
#endif // NCNN_OPS_TD
|
||||
54
3rdparty/ncnn/tools/mlir/ncnn_rewriter.cpp
vendored
Normal file
54
3rdparty/ncnn/tools/mlir/ncnn_rewriter.cpp
vendored
Normal file
@@ -0,0 +1,54 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <mlir/IR/MLIRContext.h>
|
||||
#include <mlir/IR/PatternMatch.h>
|
||||
#include <mlir/Pass/Pass.h>
|
||||
#include <mlir/Transforms/GreedyPatternRewriteDriver.h>
|
||||
|
||||
#include "tf_dialect.h"
|
||||
#include "ncnn_dialect.h"
|
||||
|
||||
using namespace mlir;
|
||||
|
||||
namespace mlir {
|
||||
|
||||
namespace ncnn {
|
||||
|
||||
#include "ncnn_rewriter.inc"
|
||||
|
||||
class NCNNOptimizePass : public PassWrapper<NCNNOptimizePass, FunctionPass>
|
||||
{
|
||||
public:
|
||||
void runOnFunction();
|
||||
};
|
||||
|
||||
void NCNNOptimizePass::runOnFunction()
|
||||
{
|
||||
mlir::OwningRewritePatternList patterns;
|
||||
mlir::ncnn::populateWithGenerated(&getContext(), patterns);
|
||||
|
||||
(void)mlir::applyPatternsAndFoldGreedily(getFunction(), std::move(patterns));
|
||||
}
|
||||
|
||||
std::unique_ptr<OperationPass<FuncOp> > createNCNNOptimizePass()
|
||||
{
|
||||
return std::make_unique<NCNNOptimizePass>();
|
||||
}
|
||||
|
||||
static PassRegistration<NCNNOptimizePass> pass("ncnn-optimize", "ncnn optimization");
|
||||
|
||||
} // namespace ncnn
|
||||
|
||||
} // namespace mlir
|
||||
210
3rdparty/ncnn/tools/mlir/ncnn_rewriter.td
vendored
Normal file
210
3rdparty/ncnn/tools/mlir/ncnn_rewriter.td
vendored
Normal file
@@ -0,0 +1,210 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef NCNN_REWRITER_TD
|
||||
#define NCNN_REWRITER_TD
|
||||
|
||||
include "tf_ops.td"
|
||||
include "ncnn_ops.td"
|
||||
|
||||
def get_attr_f : NativeCodeCall<"$0.getValue<FloatAttr>(0)">;
|
||||
|
||||
def OneElementAttrPred : CPred<"$_self.cast<ElementsAttr>().getType().getNumElements() == 1">;
|
||||
|
||||
def OneElementAttr : ElementsAttrBase<And<[ElementsAttr.predicate, OneElementAttrPred]>, "Scalar ElementsAttr">;
|
||||
|
||||
def EqualOperands : Constraint<CPred<"$0 == $1">>;
|
||||
|
||||
def FuseBinaryOpPattern0 : Pat<
|
||||
(TF_MulOp
|
||||
$x,
|
||||
(TF_ConstOp OneElementAttr:$b)
|
||||
),
|
||||
|
||||
(NCNN_BinaryOpOp $x, ConstantAttr<I32Attr, "2">, ConstantAttr<I32Attr, "1">, (get_attr_f $b))
|
||||
>;
|
||||
|
||||
def FuseBinaryOpPattern1 : Pat<
|
||||
(TF_AddV2Op
|
||||
$x,
|
||||
(TF_ConstOp OneElementAttr:$b)
|
||||
),
|
||||
|
||||
(NCNN_BinaryOpOp $x, ConstantAttr<I32Attr, "0">, ConstantAttr<I32Attr, "1">, (get_attr_f $b))
|
||||
>;
|
||||
|
||||
def FuseKerasConv2DOpPattern : Pat<
|
||||
(TF_BiasAddOp
|
||||
(TF_Conv2DOp $x, $weight, $strides, $use_cudnn_on_gpu, $padding, $explicit_paddings, $data_format, $dilations),
|
||||
$bias,
|
||||
$data_format_
|
||||
),
|
||||
|
||||
(NCNN_KerasConv2DOp $x, $weight, $bias, $strides, $padding, $explicit_paddings, $dilations)
|
||||
>;
|
||||
|
||||
def FuseKerasConv2DOpPattern1 : Pat<
|
||||
(TF_AddV2Op
|
||||
(TF_Conv2DOp $x, $weight, $strides, $use_cudnn_on_gpu, $padding, $explicit_paddings, $data_format, $dilations),
|
||||
$bias
|
||||
),
|
||||
|
||||
(NCNN_KerasConv2DOp $x, $weight, $bias, $strides, $padding, $explicit_paddings, $dilations)
|
||||
>;
|
||||
|
||||
def FuseKerasDenseOpPattern : Pat<
|
||||
(TF_BiasAddOp
|
||||
(TF_MatMulOp $x, $weight, $transpose_a, $transpose_b),
|
||||
$bias,
|
||||
$data_format_
|
||||
),
|
||||
|
||||
(NCNN_KerasDenseOp $x, $weight, $bias)
|
||||
>;
|
||||
|
||||
def NonOneElementAttrPred : CPred<"$_self.cast<ElementsAttr>().getType().getNumElements() != 1">;
|
||||
|
||||
def NonOneElementAttr : ElementsAttrBase<And<[ElementsAttr.predicate, NonOneElementAttrPred]>, "Non Scalar ElementsAttr">;
|
||||
|
||||
def FuseKerasBatchNormOpPattern : Pat<
|
||||
(TF_AddV2Op
|
||||
(TF_MulOp
|
||||
$x,
|
||||
(TF_ConstOp:$gamma NonOneElementAttr)
|
||||
),
|
||||
(TF_ConstOp:$bias NonOneElementAttr)
|
||||
),
|
||||
|
||||
(NCNN_KerasBatchNormOp $x, $gamma, $bias)
|
||||
>;
|
||||
|
||||
def FuseInstanceNormPattern0 : Pat<
|
||||
(TF_MulOp
|
||||
(TF_RsqrtOp
|
||||
(TF_AddV2Op
|
||||
(TF_MeanOp
|
||||
(TF_SquaredDifferenceOp
|
||||
(TF_MeanOp:$mean
|
||||
$x,
|
||||
(TF_ConstOp:$reduce_axis ElementsAttr),
|
||||
ConstBoolAttrTrue // keep_dims
|
||||
),
|
||||
$x_
|
||||
),
|
||||
$reduce_axis_,
|
||||
ConstBoolAttrTrue // keep_dims
|
||||
),
|
||||
(TF_ConstOp ElementsAttr:$epsilon)
|
||||
)
|
||||
),
|
||||
(TF_SubOp $x__, $mean_)
|
||||
),
|
||||
|
||||
(NCNN_InstanceNormOp $x, (get_attr_f $epsilon)),
|
||||
|
||||
[
|
||||
(EqualOperands $x, $x_),
|
||||
(EqualOperands $x, $x__),
|
||||
(EqualOperands $reduce_axis, $reduce_axis_),
|
||||
(EqualOperands $mean, $mean_)
|
||||
]
|
||||
>;
|
||||
|
||||
def FuseInstanceNormPattern1 : Pat<
|
||||
(TF_MulOp
|
||||
(TF_RsqrtOp
|
||||
(TF_AddV2Op
|
||||
(TF_MeanOp
|
||||
(TF_SquaredDifferenceOp
|
||||
$x_,
|
||||
(TF_MeanOp:$mean
|
||||
$x,
|
||||
(TF_ConstOp:$reduce_axis ElementsAttr),
|
||||
ConstBoolAttrTrue // keep_dims
|
||||
)
|
||||
),
|
||||
$reduce_axis_,
|
||||
ConstBoolAttrTrue // keep_dims
|
||||
),
|
||||
(TF_ConstOp ElementsAttr:$epsilon)
|
||||
)
|
||||
),
|
||||
(TF_SubOp $x__, $mean_)
|
||||
),
|
||||
|
||||
(NCNN_InstanceNormOp $x, (get_attr_f $epsilon)),
|
||||
|
||||
[
|
||||
(EqualOperands $x, $x_),
|
||||
(EqualOperands $x, $x__),
|
||||
(EqualOperands $reduce_axis, $reduce_axis_),
|
||||
(EqualOperands $mean, $mean_)
|
||||
]
|
||||
>;
|
||||
|
||||
def FuseInstanceNormAffinePattern : Pat<
|
||||
(TF_ReshapeOp
|
||||
(TF_AddV2Op
|
||||
(TF_MulOp
|
||||
$reshaped__,
|
||||
(TF_MulOp:$rsqrt_var_eps_gamma
|
||||
(TF_RsqrtOp
|
||||
(TF_AddV2Op
|
||||
(TF_MeanOp
|
||||
(TF_SquaredDifferenceOp
|
||||
$reshaped_,
|
||||
(TF_MeanOp:$mean
|
||||
(TF_ReshapeOp:$reshaped $x, (TF_ConstOp ElementsAttr)),
|
||||
(TF_ConstOp:$reduce_axis ElementsAttr),
|
||||
ConstBoolAttrTrue // keep_dims
|
||||
)
|
||||
),
|
||||
$reduce_axis_,
|
||||
ConstBoolAttrTrue // keep_dims
|
||||
),
|
||||
(TF_ConstOp ElementsAttr:$epsilon)
|
||||
)
|
||||
),
|
||||
$gamma
|
||||
)
|
||||
),
|
||||
(TF_SubOp
|
||||
$beta,
|
||||
(TF_MulOp $rsqrt_var_eps_gamma_, $mean_)
|
||||
)
|
||||
),
|
||||
(TF_ConstOp ElementsAttr)
|
||||
),
|
||||
|
||||
(NCNN_InstanceNormAffineOp $x, $gamma, $beta, (get_attr_f $epsilon)),
|
||||
|
||||
[
|
||||
(EqualOperands $reshaped, $reshaped_),
|
||||
(EqualOperands $reshaped, $reshaped__),
|
||||
(EqualOperands $reduce_axis, $reduce_axis_),
|
||||
(EqualOperands $rsqrt_var_eps_gamma, $rsqrt_var_eps_gamma_),
|
||||
(EqualOperands $mean, $mean_)
|
||||
]
|
||||
>;
|
||||
|
||||
def FuseSwishPattern : Pat<
|
||||
(TF_MulOp
|
||||
(TF_SigmoidOp $x),
|
||||
$x
|
||||
),
|
||||
|
||||
(NCNN_SwishOp $x)
|
||||
>;
|
||||
|
||||
#endif // NCNN_REWRITER_TD
|
||||
163
3rdparty/ncnn/tools/mlir/tf_attributes.cc
vendored
Normal file
163
3rdparty/ncnn/tools/mlir/tf_attributes.cc
vendored
Normal file
@@ -0,0 +1,163 @@
|
||||
/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
#include "tf_attributes.h"
|
||||
|
||||
namespace mlir {
|
||||
namespace TF {
|
||||
|
||||
namespace detail {
|
||||
|
||||
// The storage class for ShapeAttr.
|
||||
struct ShapeAttrStorage : public AttributeStorage
|
||||
{
|
||||
using KeyTy = std::pair<ArrayRef<int64_t>, bool>;
|
||||
|
||||
explicit ShapeAttrStorage(ArrayRef<int64_t> shape, bool unranked = false)
|
||||
: shape(shape), unranked(unranked)
|
||||
{
|
||||
}
|
||||
|
||||
bool operator==(const KeyTy& key) const
|
||||
{
|
||||
return key == KeyTy(shape, unranked);
|
||||
}
|
||||
static unsigned hashKey(const KeyTy& key)
|
||||
{
|
||||
return llvm::hash_combine(key.first, static_cast<char>(key.second));
|
||||
}
|
||||
|
||||
// NOLINTNEXTLINE
|
||||
static ShapeAttrStorage* construct(mlir::AttributeStorageAllocator& allocator,
|
||||
const KeyTy& key)
|
||||
{
|
||||
return new (allocator.allocate<ShapeAttrStorage>())
|
||||
ShapeAttrStorage(allocator.copyInto(key.first), key.second);
|
||||
}
|
||||
|
||||
ArrayRef<int64_t> shape;
|
||||
bool unranked = false;
|
||||
};
|
||||
|
||||
// The storage class for FuncAttr.
|
||||
struct FuncAttrStorage : public AttributeStorage
|
||||
{
|
||||
using KeyTy = std::pair<Attribute, Attribute>;
|
||||
|
||||
explicit FuncAttrStorage(Attribute name, Attribute attrs)
|
||||
: name(name), attrs(attrs)
|
||||
{
|
||||
}
|
||||
|
||||
bool operator==(const KeyTy& key) const
|
||||
{
|
||||
return key == KeyTy(name, attrs);
|
||||
}
|
||||
static unsigned hashKey(const KeyTy& key)
|
||||
{
|
||||
return llvm::hash_combine(key.first, key.second);
|
||||
}
|
||||
|
||||
static FuncAttrStorage* construct(mlir::AttributeStorageAllocator& allocator,
|
||||
const KeyTy& key)
|
||||
{
|
||||
return new (allocator.allocate<FuncAttrStorage>())
|
||||
FuncAttrStorage(key.first, key.second);
|
||||
}
|
||||
|
||||
Attribute name;
|
||||
Attribute attrs;
|
||||
};
|
||||
|
||||
} // namespace detail
|
||||
|
||||
// Get or create a shape attribute.
|
||||
ShapeAttr ShapeAttr::get(mlir::MLIRContext* context,
|
||||
llvm::Optional<ArrayRef<int64_t> > shape)
|
||||
{
|
||||
if (shape) return Base::get(context, *shape, /*unranked=*/false);
|
||||
|
||||
return Base::get(context, ArrayRef<int64_t>(), /*unranked=*/true);
|
||||
}
|
||||
|
||||
// Get or create a shape attribute.
|
||||
ShapeAttr ShapeAttr::get(mlir::MLIRContext* context, ShapedType shaped_type)
|
||||
{
|
||||
if (shaped_type.hasRank())
|
||||
return Base::get(context, shaped_type.getShape(), /*unranked=*/false);
|
||||
|
||||
return Base::get(context, ArrayRef<int64_t>(), /*unranked=*/true);
|
||||
}
|
||||
|
||||
llvm::Optional<ArrayRef<int64_t> > ShapeAttr::getValue() const
|
||||
{
|
||||
if (hasRank()) return getShape();
|
||||
return llvm::None;
|
||||
}
|
||||
|
||||
bool ShapeAttr::hasRank() const
|
||||
{
|
||||
return !getImpl()->unranked;
|
||||
}
|
||||
|
||||
int64_t ShapeAttr::getRank() const
|
||||
{
|
||||
assert(hasRank());
|
||||
return getImpl()->shape.size();
|
||||
}
|
||||
|
||||
ArrayRef<int64_t> ShapeAttr::getShape() const
|
||||
{
|
||||
assert(hasRank());
|
||||
return getImpl()->shape;
|
||||
}
|
||||
|
||||
bool ShapeAttr::hasStaticShape() const
|
||||
{
|
||||
if (!hasRank()) return false;
|
||||
|
||||
for (auto dim : getShape())
|
||||
{
|
||||
if (dim < 0) return false;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
FuncAttr FuncAttr::get(mlir::MLIRContext* context, llvm::StringRef name,
|
||||
DictionaryAttr attr)
|
||||
{
|
||||
auto symbol = SymbolRefAttr::get(context, name);
|
||||
return Base::get(context, symbol, attr);
|
||||
}
|
||||
|
||||
FuncAttr FuncAttr::get(mlir::MLIRContext* context, SymbolRefAttr symbol,
|
||||
DictionaryAttr attr)
|
||||
{
|
||||
return Base::get(context, symbol, attr);
|
||||
}
|
||||
|
||||
SymbolRefAttr FuncAttr::GetName() const
|
||||
{
|
||||
return getImpl()->name.cast<SymbolRefAttr>();
|
||||
}
|
||||
|
||||
DictionaryAttr FuncAttr::GetAttrs() const
|
||||
{
|
||||
return getImpl()->attrs.cast<DictionaryAttr>();
|
||||
}
|
||||
|
||||
} // namespace TF
|
||||
} // namespace mlir
|
||||
97
3rdparty/ncnn/tools/mlir/tf_attributes.h
vendored
Normal file
97
3rdparty/ncnn/tools/mlir/tf_attributes.h
vendored
Normal file
@@ -0,0 +1,97 @@
|
||||
/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
// This file defines the attributes used in the TensorFlow dialect.
|
||||
|
||||
#ifndef TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_ATTRIBUTES_H_
|
||||
#define TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_ATTRIBUTES_H_
|
||||
|
||||
#include "llvm/ADT/StringRef.h"
|
||||
#include "mlir/IR/BuiltinAttributes.h" // from @llvm-project
|
||||
#include "mlir/IR/BuiltinTypes.h" // from @llvm-project
|
||||
#include "mlir/IR/MLIRContext.h" // from @llvm-project
|
||||
|
||||
namespace mlir {
|
||||
namespace TF {
|
||||
|
||||
namespace detail {
|
||||
|
||||
struct ShapeAttrStorage;
|
||||
struct FuncAttrStorage;
|
||||
|
||||
} // namespace detail
|
||||
|
||||
class ShapeAttr : public Attribute::AttrBase<ShapeAttr, Attribute,
|
||||
detail::ShapeAttrStorage>
|
||||
{
|
||||
public:
|
||||
using Base::Base;
|
||||
|
||||
// Get or create a shape attribute. If shape is llvm::None, then it is
|
||||
// unranked. Otherwise it is ranked. And for ranked shapes, the value of the
|
||||
// dimension size must be >= -1. The value of -1 means the dimension is
|
||||
// dynamic. Otherwise, the dimension is static.
|
||||
static ShapeAttr get(mlir::MLIRContext* context,
|
||||
llvm::Optional<ArrayRef<int64_t> > shape);
|
||||
|
||||
// Get or create a shape attribute from a ShapedType type.
|
||||
static ShapeAttr get(mlir::MLIRContext* context, ShapedType shaped_type);
|
||||
|
||||
llvm::Optional<ArrayRef<int64_t> > getValue() const;
|
||||
|
||||
bool hasRank() const;
|
||||
|
||||
// If this is ranked, return the rank. Otherwise, abort.
|
||||
int64_t getRank() const;
|
||||
|
||||
// If this is ranked, return the shape. Otherwise, abort.
|
||||
ArrayRef<int64_t> getShape() const;
|
||||
|
||||
// If this is unranked type or any dimension has unknown size (<0), it doesn't
|
||||
// have static shape. If all dimensions have known size (>= 0), it has static
|
||||
// shape.
|
||||
bool hasStaticShape() const;
|
||||
};
|
||||
|
||||
// Custom attribute to model AttrValue.value.func (NameAttrList type attribute).
|
||||
// This attribute holds a SymbolRefAttr, for the NameAttrList.name string and a
|
||||
// DictionaryAttr for the NameAttrList.attr map<string, AttrValue>. It is
|
||||
// currently printed and parsed for the following format:
|
||||
//
|
||||
// #tf.func<@symbol, {attr = "value"}>
|
||||
//
|
||||
// where the first element is the SymbolRefAttr and the second element is the
|
||||
// DictionaryAttr.
|
||||
class FuncAttr
|
||||
: public Attribute::AttrBase<FuncAttr, Attribute, detail::FuncAttrStorage>
|
||||
{
|
||||
public:
|
||||
using Base::Base;
|
||||
|
||||
static FuncAttr get(mlir::MLIRContext* context, llvm::StringRef name,
|
||||
DictionaryAttr attr);
|
||||
|
||||
static FuncAttr get(mlir::MLIRContext* context, SymbolRefAttr symbol,
|
||||
DictionaryAttr attr);
|
||||
|
||||
SymbolRefAttr GetName() const;
|
||||
|
||||
DictionaryAttr GetAttrs() const;
|
||||
};
|
||||
|
||||
} // namespace TF
|
||||
} // namespace mlir
|
||||
|
||||
#endif // TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_ATTRIBUTES_H_
|
||||
323
3rdparty/ncnn/tools/mlir/tf_dialect.cpp
vendored
Normal file
323
3rdparty/ncnn/tools/mlir/tf_dialect.cpp
vendored
Normal file
@@ -0,0 +1,323 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "tf_dialect.h"
|
||||
|
||||
#include <mlir/Dialect/Traits.h>
|
||||
#include <mlir/IR/Attributes.h>
|
||||
#include <mlir/IR/Builders.h>
|
||||
#include <mlir/IR/Dialect.h>
|
||||
#include <mlir/IR/DialectImplementation.h>
|
||||
#include <mlir/IR/Location.h>
|
||||
#include <mlir/IR/Matchers.h>
|
||||
#include <mlir/IR/MLIRContext.h>
|
||||
#include <mlir/IR/OpDefinition.h>
|
||||
#include <mlir/IR/OpImplementation.h>
|
||||
#include <mlir/IR/Operation.h>
|
||||
#include <mlir/IR/OperationSupport.h>
|
||||
#include <mlir/IR/PatternMatch.h>
|
||||
#include <mlir/IR/TypeUtilities.h>
|
||||
#include <mlir/IR/Types.h>
|
||||
#include <mlir/IR/Value.h>
|
||||
#include <mlir/IR/Verifier.h>
|
||||
#include <mlir/Interfaces/CallInterfaces.h>
|
||||
#include <mlir/Interfaces/DerivedAttributeOpInterface.h>
|
||||
#include <mlir/Interfaces/InferTypeOpInterface.h>
|
||||
#include <mlir/Interfaces/LoopLikeInterface.h>
|
||||
#include <mlir/Interfaces/SideEffectInterfaces.h>
|
||||
#include <mlir/Parser.h>
|
||||
#include <mlir/Support/LogicalResult.h>
|
||||
#include <mlir/Transforms/InliningUtils.h>
|
||||
|
||||
#include "tf_attributes.h"
|
||||
#include "tf_side_effects.h"
|
||||
#include "tf_traits.h"
|
||||
|
||||
namespace mlir {
|
||||
|
||||
static LogicalResult Verify(...)
|
||||
{
|
||||
return success();
|
||||
}
|
||||
static LogicalResult VerifyPartitionedCall(...)
|
||||
{
|
||||
return success();
|
||||
}
|
||||
static LogicalResult VerifyStridedSliceBase(...)
|
||||
{
|
||||
return success();
|
||||
}
|
||||
static LogicalResult VerifyUnsortedSegmentReduction(...)
|
||||
{
|
||||
return success();
|
||||
}
|
||||
|
||||
namespace TF {
|
||||
|
||||
TensorFlowDialect::TensorFlowDialect(MLIRContext* context)
|
||||
: Dialect(/*name=*/"tf", context, TypeID::get<TensorFlowDialect>())
|
||||
{
|
||||
addOperations<
|
||||
#define GET_OP_LIST
|
||||
#include "tf_all_ops.cc.inc"
|
||||
>();
|
||||
addTypes<
|
||||
#define HANDLE_TF_TYPE(tftype, enumerant, name) tftype##Type,
|
||||
#define HANDLE_LAST_TF_TYPE(tftype, enumerant, name) tftype##Type
|
||||
#include "tf_types.def"
|
||||
>();
|
||||
// addInterfaces<TFInlinerInterface, TFDecodeAttributesInterface,
|
||||
// TFConstantFoldInterface>();
|
||||
addAttributes<ShapeAttr, FuncAttr>();
|
||||
|
||||
// Support unknown operations because not all TensorFlow operations are
|
||||
// registered.
|
||||
allowUnknownOperations();
|
||||
|
||||
// for (const auto &hook : *TensorFlowDialect::additional_operation_hooks_) {
|
||||
// hook(*this);
|
||||
// }
|
||||
}
|
||||
|
||||
namespace {
|
||||
|
||||
ShapeAttr ParseShapeAttr(MLIRContext* context, StringRef spec, Location loc)
|
||||
{
|
||||
auto emit_error = [&, spec]() {
|
||||
emitError(loc, "invalid TensorFlow shape attribute: ") << spec;
|
||||
return nullptr;
|
||||
};
|
||||
|
||||
if (!spec.consume_front("shape<")) return emit_error();
|
||||
|
||||
if (spec.consume_front("*>"))
|
||||
return mlir::TF::ShapeAttr::get(context, llvm::None);
|
||||
|
||||
SmallVector<int64_t, 4> shape;
|
||||
while (!spec.consume_front(">"))
|
||||
{
|
||||
int64_t dim;
|
||||
|
||||
if (spec.consume_front("?"))
|
||||
dim = -1;
|
||||
else if (spec.consumeInteger(10, dim) || dim < 0)
|
||||
return emit_error();
|
||||
|
||||
spec.consume_front("x");
|
||||
|
||||
shape.push_back(dim);
|
||||
}
|
||||
|
||||
return mlir::TF::ShapeAttr::get(context, llvm::makeArrayRef(shape));
|
||||
}
|
||||
|
||||
// Parses a #tf.func attribute of the following format:
|
||||
//
|
||||
// #tf.func<@symbol, {attr = "value"}>
|
||||
//
|
||||
// where the first element is a SymbolRefAttr and the second element is a
|
||||
// DictionaryAttr.
|
||||
FuncAttr ParseFuncAttr(MLIRContext* context, StringRef spec, Location loc)
|
||||
{
|
||||
auto emit_error = [&, spec]() {
|
||||
emitError(loc, "invalid TensorFlow func attribute: ") << spec;
|
||||
return nullptr;
|
||||
};
|
||||
|
||||
if (!spec.consume_front("func<")) return emit_error();
|
||||
|
||||
size_t func_name_num_read = 0;
|
||||
Attribute func_name_attr = mlir::parseAttribute(spec, context, func_name_num_read);
|
||||
if (!func_name_attr || !func_name_attr.isa<SymbolRefAttr>())
|
||||
return emit_error();
|
||||
spec = spec.drop_front(func_name_num_read);
|
||||
|
||||
if (!spec.consume_front(", ")) return emit_error();
|
||||
|
||||
size_t func_attrs_num_read = 0;
|
||||
Attribute func_attrs_attr = mlir::parseAttribute(spec, context, func_attrs_num_read);
|
||||
if (!func_attrs_attr || !func_attrs_attr.isa<DictionaryAttr>())
|
||||
return emit_error();
|
||||
spec = spec.drop_front(func_attrs_num_read);
|
||||
|
||||
if (!spec.consume_front(">")) return emit_error();
|
||||
|
||||
return mlir::TF::FuncAttr::get(context, func_name_attr.cast<SymbolRefAttr>(),
|
||||
func_attrs_attr.cast<DictionaryAttr>());
|
||||
}
|
||||
|
||||
} // namespace
|
||||
|
||||
Attribute TensorFlowDialect::parseAttribute(DialectAsmParser& parser,
|
||||
Type type) const
|
||||
{
|
||||
auto spec = parser.getFullSymbolSpec();
|
||||
Location loc = parser.getEncodedSourceLoc(parser.getNameLoc());
|
||||
|
||||
if (spec.startswith("shape")) return ParseShapeAttr(getContext(), spec, loc);
|
||||
|
||||
if (spec.startswith("func")) return ParseFuncAttr(getContext(), spec, loc);
|
||||
|
||||
return (emitError(loc, "unknown TensorFlow attribute: " + spec), nullptr);
|
||||
}
|
||||
|
||||
// Parses a type registered to this dialect.
|
||||
Type TensorFlowDialect::parseType(DialectAsmParser& parser) const
|
||||
{
|
||||
StringRef data;
|
||||
if (parser.parseKeyword(&data)) return Type();
|
||||
|
||||
#define HANDLE_TF_TYPE(tftype, enumerant, name) \
|
||||
if (data == name) return tftype##Type::get(getContext());
|
||||
// Custom TensorFlow types are handled separately at the end as they do partial
|
||||
// match.
|
||||
#define HANDLE_CUSTOM_TF_TYPE(tftype, enumerant, name)
|
||||
// NOLINTNEXTLINE
|
||||
#include "tf_types.def"
|
||||
|
||||
llvm::SMLoc loc = parser.getNameLoc();
|
||||
if (data.startswith("resource"))
|
||||
{
|
||||
Type ret = ParseResourceType(parser);
|
||||
if (!ret) parser.emitError(loc, "invalid resource type");
|
||||
return ret;
|
||||
}
|
||||
if (data.startswith("variant"))
|
||||
{
|
||||
Type ret = ParseVariantType(parser);
|
||||
if (!ret) parser.emitError(loc, "invalid variant type");
|
||||
return ret;
|
||||
}
|
||||
return (parser.emitError(loc, "unknown TensorFlow type: " + data), nullptr);
|
||||
}
|
||||
|
||||
namespace {
|
||||
template<typename TypeWithSubtype>
|
||||
Type ParseTypeWithSubtype(MLIRContext* context, DialectAsmParser& parser)
|
||||
{
|
||||
// Default type without inferred subtypes.
|
||||
if (failed(parser.parseOptionalLess())) return TypeWithSubtype::get(context);
|
||||
|
||||
// Most types with subtypes have only one subtype.
|
||||
SmallVector<TensorType, 1> subtypes;
|
||||
do
|
||||
{
|
||||
TensorType tensor_ty;
|
||||
if (parser.parseType(tensor_ty)) return Type();
|
||||
|
||||
// Each of the subtypes should be a valid TensorFlow type.
|
||||
// TODO(jpienaar): Remove duplication.
|
||||
if (!IsValidTFTensorType(tensor_ty))
|
||||
{
|
||||
parser.emitError(parser.getNameLoc()) << "invalid subtype: " << tensor_ty;
|
||||
return Type();
|
||||
}
|
||||
subtypes.push_back(tensor_ty);
|
||||
} while (succeeded(parser.parseOptionalComma()));
|
||||
|
||||
if (parser.parseGreater()) return Type();
|
||||
|
||||
return TypeWithSubtype::get(subtypes, context);
|
||||
}
|
||||
} // anonymous namespace
|
||||
|
||||
Type TensorFlowDialect::ParseResourceType(DialectAsmParser& parser) const
|
||||
{
|
||||
return ParseTypeWithSubtype<ResourceType>(getContext(), parser);
|
||||
}
|
||||
|
||||
Type TensorFlowDialect::ParseVariantType(DialectAsmParser& parser) const
|
||||
{
|
||||
return ParseTypeWithSubtype<VariantType>(getContext(), parser);
|
||||
}
|
||||
|
||||
Operation* TensorFlowDialect::materializeConstant(OpBuilder& builder,
|
||||
Attribute value, Type type,
|
||||
Location loc)
|
||||
{
|
||||
return builder.create<ConstOp>(loc, type, value);
|
||||
}
|
||||
|
||||
// Builds a constant op with the specified attribute `value`. The result
|
||||
// op's type is deduced from `value`; if `value` is of scalar type,
|
||||
// wraps it up with a tensor type of empty shape.
|
||||
// TODO(jpienaar): This one differs from the autogenerated one as it takes an
|
||||
// attribute but always creates an ElementsAttr internally.
|
||||
void ConstOp::build(OpBuilder& builder, OperationState& result,
|
||||
Attribute value)
|
||||
{
|
||||
ShapedType type;
|
||||
if (auto elem_attr = value.dyn_cast<ElementsAttr>())
|
||||
{
|
||||
return ConstOp::build(builder, result, elem_attr);
|
||||
}
|
||||
else if (value.isa<BoolAttr, FloatAttr, IntegerAttr>())
|
||||
{
|
||||
// All TensorFlow types must be tensor types. In the build() method,
|
||||
// we want to provide more flexibility by allowing attributes of scalar
|
||||
// types. But we need to wrap it up with ElementsAttr to construct
|
||||
// valid TensorFlow constants.
|
||||
type = RankedTensorType::get(/*shape=*/ {}, value.getType());
|
||||
return ConstOp::build(builder, result, DenseElementsAttr::get(type, value));
|
||||
}
|
||||
// TODO(jpienaar): support other TensorFlow specific types.
|
||||
llvm_unreachable("unsupported attribute type for building tf.Const");
|
||||
}
|
||||
|
||||
void ConstOp::build(OpBuilder& builder, OperationState& result, Type type,
|
||||
Attribute value)
|
||||
{
|
||||
// Handle the case where the type and value are already tensors.
|
||||
if (type.isa<TensorType>() && value.isa<ElementsAttr>())
|
||||
{
|
||||
result.addTypes(type);
|
||||
result.addAttribute("value", value);
|
||||
return;
|
||||
}
|
||||
|
||||
// Otherwise, default to the attribute builder.
|
||||
ConstOp::build(builder, result, value);
|
||||
assert(type == result.types[0] && "type mismatch in construction");
|
||||
}
|
||||
|
||||
Region& WhileRegionOp::getLoopBody()
|
||||
{
|
||||
return body();
|
||||
}
|
||||
|
||||
bool WhileRegionOp::isDefinedOutsideOfLoop(Value value)
|
||||
{
|
||||
// If the Op defining the value exists and the defining op is outside the
|
||||
// scope of this WhileRegion, then we can infer that its defined outside.
|
||||
// The defining Op is outside the scope of this WhileRegion if this
|
||||
// WhileRegionOp is not an ancestor of the defining op in the parent chain.
|
||||
Operation* def_op = value.getDefiningOp();
|
||||
return def_op && !getOperation()->isAncestor(def_op);
|
||||
}
|
||||
|
||||
LogicalResult WhileRegionOp::moveOutOfLoop(
|
||||
llvm::ArrayRef<mlir::Operation*> ops)
|
||||
{
|
||||
// Move the hoisted value to just before the while.
|
||||
Operation* while_op = this->getOperation();
|
||||
for (auto op : ops) op->moveBefore(while_op);
|
||||
return success();
|
||||
}
|
||||
|
||||
} // namespace TF
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
#define GET_OP_CLASSES
|
||||
#include "tf_all_ops.cc.inc"
|
||||
68
3rdparty/ncnn/tools/mlir/tf_dialect.h
vendored
Normal file
68
3rdparty/ncnn/tools/mlir/tf_dialect.h
vendored
Normal file
@@ -0,0 +1,68 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef TF_DIALECT_H
|
||||
#define TF_DIALECT_H
|
||||
|
||||
#include <mlir/Dialect/Traits.h>
|
||||
#include <mlir/IR/BuiltinOps.h>
|
||||
#include <mlir/IR/Dialect.h>
|
||||
#include <mlir/IR/OpImplementation.h>
|
||||
#include <mlir/Interfaces/ControlFlowInterfaces.h>
|
||||
#include <mlir/Interfaces/DerivedAttributeOpInterface.h>
|
||||
#include <mlir/Interfaces/InferTypeOpInterface.h>
|
||||
#include <mlir/Interfaces/LoopLikeInterface.h>
|
||||
#include <mlir/Interfaces/SideEffectInterfaces.h>
|
||||
|
||||
#include "tf_traits.h"
|
||||
|
||||
namespace mlir {
|
||||
|
||||
namespace TF {
|
||||
|
||||
class TensorFlowDialect : public mlir::Dialect
|
||||
{
|
||||
public:
|
||||
TensorFlowDialect(mlir::MLIRContext* context);
|
||||
|
||||
static StringRef getDialectNamespace()
|
||||
{
|
||||
return "tf";
|
||||
}
|
||||
|
||||
Attribute parseAttribute(DialectAsmParser& parser, Type type) const override;
|
||||
|
||||
// Parse a type registered to this dialect.
|
||||
Type parseType(DialectAsmParser& parser) const override;
|
||||
|
||||
// Parses resource type with potential subtypes.
|
||||
Type ParseResourceType(DialectAsmParser& parser) const;
|
||||
|
||||
// Parse and print variant type. It may have subtypes inferred using shape
|
||||
// inference.
|
||||
Type ParseVariantType(DialectAsmParser& parser) const;
|
||||
|
||||
// Registered hook to materialize a constant operation from a given attribute
|
||||
// value with the desired resultant type.
|
||||
Operation* materializeConstant(OpBuilder& builder, Attribute value, Type type, Location loc) override;
|
||||
};
|
||||
|
||||
} // namespace TF
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
#define GET_OP_CLASSES
|
||||
#include "tf_all_ops.h.inc"
|
||||
|
||||
#endif // TF_DIALECT_H
|
||||
18565
3rdparty/ncnn/tools/mlir/tf_generated_ops.td
vendored
Normal file
18565
3rdparty/ncnn/tools/mlir/tf_generated_ops.td
vendored
Normal file
File diff suppressed because it is too large
Load Diff
617
3rdparty/ncnn/tools/mlir/tf_op_base.td
vendored
Normal file
617
3rdparty/ncnn/tools/mlir/tf_op_base.td
vendored
Normal file
@@ -0,0 +1,617 @@
|
||||
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
// This is the base operation definition file for TensorFlow.
|
||||
//
|
||||
// This file includes the definition for the TensorFlow dialect, base TensorFlow
|
||||
// op, and various commonly used TensorFlow traits, types, attributes, and
|
||||
// builders.
|
||||
|
||||
#ifndef TF_OP_BASE
|
||||
#define TF_OP_BASE
|
||||
|
||||
include "mlir/IR/OpBase.td"
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td"
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow dialect definitions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def TF_Dialect : Dialect {
|
||||
let name = "tf";
|
||||
|
||||
let description = [{
|
||||
The TensorFlow dialect.
|
||||
|
||||
This dialect maps to TensorFlow operations.
|
||||
|
||||
Invariants:
|
||||
|
||||
* All values are of Tensor type (in particular, scalars are
|
||||
represented using zero-dimensional tensors);
|
||||
|
||||
TODO: Make invariants more structured so that we can reference them in ops.
|
||||
}];
|
||||
|
||||
let cppNamespace = "::mlir::TF";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow traits
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
// Specify this trait if the op requires all outputs to have the same type and
|
||||
// the inputs either have the same type as result or a ref type corresponding to
|
||||
// the result type.
|
||||
def TF_OperandsSameAsResultsTypeOrRef : NativeOpTrait<
|
||||
"TF::OperandsSameAsResultsTypeOrRef">;
|
||||
|
||||
// Op has the same operand and result element types (or type itself, if scalar)
|
||||
// after resolving reference types (i.e., after converting reference types to
|
||||
// their corresponding TensorFlow or standard types).
|
||||
def TF_SameOperandsAndResultElementTypeResolveRef : NativeOpTrait<
|
||||
"TF::SameOperandsAndResultElementTypeResolveRef">;
|
||||
|
||||
// Op has the same operand and result types after resolving reference types
|
||||
// (i.e., after converting reference types to their corresponding TensorFlow or
|
||||
// standard types).
|
||||
def TF_SameOperandsAndResultTypeResolveRef : NativeOpTrait<
|
||||
"TF::SameOperandsAndResultTypeResolveRef">;
|
||||
|
||||
// Layout agnostic operations do not depend on the operands data layout (data
|
||||
// format), as an example all element wise operations are layout agnostic.
|
||||
def TF_LayoutAgnostic : NativeOpTrait<"TF::LayoutAgnostic">;
|
||||
|
||||
// Trait to indicate operations that cannot be duplicated as they might carry
|
||||
// certain state around within their implementations.
|
||||
def TF_CannotDuplicate : NativeOpTrait<"TF::CannotDuplicate">;
|
||||
|
||||
// Trait to indicate an operation cannot be constant folded.
|
||||
def TF_NoConstantFold : NativeOpTrait<"TF::NoConstantFold">;
|
||||
|
||||
// Coefficient wise binary operation with implicit broadcasting support, for
|
||||
// example tf.Sub operation.
|
||||
def TF_CwiseBinary : NativeOpTrait<"TF::CwiseBinary">;
|
||||
|
||||
// Coefficient wise unary operation, for example tf.Sqrt operation.
|
||||
def TF_CwiseUnary : NativeOpTrait<"TF::CwiseUnary">;
|
||||
|
||||
// Variant of broadcastable trait that considers TF's subtype behavior.
|
||||
class TF_OpIsBroadcastableToRes<int opId, int resId> : And<[
|
||||
TCOpResIsShapedTypePred<opId, resId>,
|
||||
CPred<"mlir::TF::BroadcastCompatible("
|
||||
"$_op.getOperand(" # opId # ").getType(), "
|
||||
"$_op.getResult(" # resId # ").getType())">]>;
|
||||
|
||||
|
||||
class TF_AllTypesMatchPred<list<string> values> :
|
||||
CPred<"TF::AreCastCompatible(llvm::makeArrayRef({" #
|
||||
!interleave(values, ", ") # "}))">;
|
||||
|
||||
class TF_AllTypesMatch<list<string> names> :
|
||||
PredOpTrait<
|
||||
"all of {" # !interleave(names, ", ") #
|
||||
"} have dynamically equal types ",
|
||||
TF_AllTypesMatchPred<
|
||||
!foreach(n, names, !subst("$_self", "$" # n, "$_self.getType()"))>>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Rank/Shape helpers.
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
class TF_OperandIsUnrankedPred<int n> :
|
||||
CPred<"$_op.getOperand(" # n # ").getType().isa<UnrankedTensorType>()">;
|
||||
|
||||
class TF_ResultIsUnrankedPred<int n> :
|
||||
CPred<"$_op.getResult(" # n # ").getType().isa<UnrankedTensorType>()">;
|
||||
|
||||
// Returns true if the n-th operand has unknown rank or has rank m.
|
||||
class TF_OperandHasRank<int n, int m> :
|
||||
PredOpTrait<"operand " # n # " is " # m # "-D",
|
||||
Or<[TF_OperandIsUnrankedPred<n>,
|
||||
CPred<"$_op.getOperand(" # n #
|
||||
").getType().cast<ShapedType>().getRank() == " # m>]>>;
|
||||
|
||||
// Returns true if the n-th result has unknown rank or has rank m.
|
||||
class TF_ResultHasRank<int n, int m> :
|
||||
PredOpTrait<"result " # n # " is " # m # "-D",
|
||||
Or<[TF_ResultIsUnrankedPred<n>,
|
||||
CPred<"$_op.getResult(" # n #
|
||||
").getType().cast<ShapedType>().getRank() == " # m>]>>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow op side effects
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
class TF_ResourceBase<string resourceKind> :
|
||||
Resource<!strconcat("::mlir::TF::ResourceEffects::", resourceKind)> {
|
||||
}
|
||||
|
||||
def TF_VariableResource : TF_ResourceBase<"Variable">;
|
||||
def TF_StackResource : TF_ResourceBase<"Stack">;
|
||||
def TF_TensorArrayResource : TF_ResourceBase<"TensorArray">;
|
||||
def TF_SummaryResource : TF_ResourceBase<"Summary">;
|
||||
def TF_LookupTableResource : TF_ResourceBase<"LookupTable">;
|
||||
def TF_DatasetSeedGeneratorResource : TF_ResourceBase<"DatasetSeedGenerator">;
|
||||
def TF_DatasetMemoryCacheResource : TF_ResourceBase<"DatasetMemoryCache">;
|
||||
def TF_DatasetIteratorResource : TF_ResourceBase<"DatasetIterator">;
|
||||
def TF_TPUEmbeddingResource : TF_ResourceBase<"TPUEmbedding">;
|
||||
|
||||
def TF_VariableRead : MemRead<TF_VariableResource>;
|
||||
def TF_StackRead : MemRead<TF_StackResource>;
|
||||
def TF_TensorArrayRead : MemRead<TF_TensorArrayResource>;
|
||||
def TF_LookupTableRead : MemRead<TF_LookupTableResource>;
|
||||
def TF_DatasetSeedGeneratorRead : MemRead<TF_DatasetSeedGeneratorResource>;
|
||||
def TF_DatasetMemoryCacheRead : MemRead<TF_DatasetMemoryCacheResource>;
|
||||
def TF_DatasetIteratorRead : MemRead<TF_DatasetIteratorResource>;
|
||||
|
||||
def TF_VariableWrite : MemWrite<TF_VariableResource>;
|
||||
def TF_StackWrite : MemWrite<TF_StackResource>;
|
||||
def TF_TensorArrayWrite : MemWrite<TF_TensorArrayResource>;
|
||||
def TF_SummaryWrite : MemWrite<TF_SummaryResource>;
|
||||
def TF_LookupTableWrite : MemWrite<TF_LookupTableResource>;
|
||||
def TF_DatasetSeedGeneratorWrite : MemWrite<TF_DatasetSeedGeneratorResource>;
|
||||
def TF_DatasetMemoryCacheWrite : MemWrite<TF_DatasetMemoryCacheResource>;
|
||||
def TF_DatasetIteratorWrite : MemWrite<TF_DatasetIteratorResource>;
|
||||
|
||||
def TF_VariableAlloc : MemAlloc<TF_VariableResource>;
|
||||
def TF_StackAlloc : MemAlloc<TF_StackResource>;
|
||||
def TF_TensorArrayAlloc : MemAlloc<TF_TensorArrayResource>;
|
||||
def TF_SummaryAlloc : MemAlloc<TF_SummaryResource>;
|
||||
def TF_LookupTableAlloc : MemAlloc<TF_LookupTableResource>;
|
||||
def TF_DatasetSeedGeneratorAlloc : MemAlloc<TF_DatasetSeedGeneratorResource>;
|
||||
def TF_DatasetMemoryCacheAlloc : MemAlloc<TF_DatasetMemoryCacheResource>;
|
||||
def TF_DatasetIteratorAlloc : MemAlloc<TF_DatasetIteratorResource>;
|
||||
|
||||
def TF_StackFree : MemFree<TF_StackResource>;
|
||||
def TF_TensorArrayFree : MemFree<TF_TensorArrayResource>;
|
||||
def TF_SummaryFree : MemFree<TF_SummaryResource>;
|
||||
def TF_DatasetSeedGeneratorFree : MemFree<TF_DatasetSeedGeneratorResource>;
|
||||
def TF_DatasetMemoryCacheFree : MemFree<TF_DatasetMemoryCacheResource>;
|
||||
def TF_DatasetIteratorFree : MemFree<TF_DatasetIteratorResource>;
|
||||
|
||||
def TF_TPUEmbeddingSideEffect : MemoryEffects<[MemWrite<TF_TPUEmbeddingResource>]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow op definitions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
class TF_Op<string mnemonic, list<OpTrait> traits = []> :
|
||||
Op<TF_Dialect, mnemonic, traits>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow attribute definitions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
class TF_TensorFlowAttr <string name, string description> :
|
||||
Attr<CPred<"$_self.isa<mlir::TF::" # name # "Attr>()">,
|
||||
"TensorFlow " # description # " attribute">;
|
||||
|
||||
def TF_ShapeAttr : TF_TensorFlowAttr<"Shape", "shape"> {
|
||||
let returnType = "llvm::Optional<llvm::ArrayRef<int64_t>>";
|
||||
let convertFromStorage = "$_self.cast<mlir::TF::ShapeAttr>().getValue()";
|
||||
|
||||
// Create a ranked shape attr by default.
|
||||
let constBuilderCall = "mlir::TF::ShapeAttr::get($_builder.getContext(), $0)";
|
||||
}
|
||||
|
||||
def TF_ShapeAttrArray :
|
||||
TypedArrayAttrBase<TF_ShapeAttr, "tensorflow shape attribute array">;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow type definitions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
// Any tensor element type defined in the TensorFlow dialect
|
||||
def TF_TFDialectType :
|
||||
Type<CPred<"$_self.isa<mlir::TF::TensorFlowType>()">, "TensorFlow type">;
|
||||
|
||||
// Class for any TensorFlow dialect specific type
|
||||
class TF_TensorFlowType <string name, string description> :
|
||||
Type<CPred<"$_self.isa<mlir::TF::" # name # "Type>()">,
|
||||
"TensorFlow " # description # " type">,
|
||||
BuildableType<"getType<mlir::TF::" # name # "Type>()">;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Reference types
|
||||
|
||||
// Float reference types
|
||||
def TF_Float16Ref : TF_TensorFlowType<"HalfRef", "f16ref">;
|
||||
def TF_Float32Ref : TF_TensorFlowType<"FloatRef", "f32ref">;
|
||||
def TF_Float64Ref : TF_TensorFlowType<"DoubleRef", "f64ref">;
|
||||
def TF_Bfloat16Ref : TF_TensorFlowType<"Bfloat16Ref", "bf16ref">;
|
||||
|
||||
// Complex reference types
|
||||
def TF_Complex64Ref : TF_TensorFlowType<"Complex64Ref", "complex64ref">;
|
||||
def TF_Complex128Ref : TF_TensorFlowType<"Complex128Ref", "complex128ref">;
|
||||
|
||||
// Integer reference types
|
||||
def TF_Int8Ref : TF_TensorFlowType<"Int8Ref", "i8ref">;
|
||||
def TF_Int16Ref : TF_TensorFlowType<"Int16Ref", "i16ref">;
|
||||
def TF_Int32Ref : TF_TensorFlowType<"Int32Ref", "i32ref">;
|
||||
def TF_Int64Ref : TF_TensorFlowType<"Int64Ref", "i64ref">;
|
||||
|
||||
def TF_Uint8Ref : TF_TensorFlowType<"Uint8Ref", "ui8ref">;
|
||||
def TF_Uint16Ref : TF_TensorFlowType<"Uint16Ref", "ui16ref">;
|
||||
def TF_Uint32Ref : TF_TensorFlowType<"Uint32Ref", "ui32ref">;
|
||||
def TF_Uint64Ref : TF_TensorFlowType<"Uint64Ref", "ui64ref">;
|
||||
|
||||
// Quantized reference types
|
||||
def TF_Qint8Ref : TF_TensorFlowType<"Qint8Ref", "qint8ref">;
|
||||
def TF_Qint16Ref : TF_TensorFlowType<"Qint16Ref", "qint16ref">;
|
||||
def TF_Qint32Ref : TF_TensorFlowType<"Qint32Ref", "qint32ref">;
|
||||
def TF_Quint8Ref : TF_TensorFlowType<"Quint8Ref", "quint8ref">;
|
||||
def TF_Quint16Ref : TF_TensorFlowType<"Quint16Ref", "quint16ref">;
|
||||
|
||||
// Other reference types
|
||||
def TF_BoolRef : TF_TensorFlowType<"BoolRef", "boolref">;
|
||||
def TF_ResourceRef : TF_TensorFlowType<"ResourceRef", "resourceref">;
|
||||
def TF_StrRef : TF_TensorFlowType<"StringRef", "stringref">;
|
||||
def TF_VariantRef : TF_TensorFlowType<"VariantRef", "variantref">;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Integer types (including corresponding reference types)
|
||||
|
||||
def TF_Bool : AnyTypeOf<[I<1>, TF_BoolRef], "bool">;
|
||||
|
||||
def TF_Int8 : AnyTypeOf<[I8, TF_Int8Ref], "8-bit integer">;
|
||||
def TF_Int16 : AnyTypeOf<[I16, TF_Int16Ref], "16-bit integer">;
|
||||
def TF_Int32 : AnyTypeOf<[I32, TF_Int32Ref], "32-bit integer">;
|
||||
def TF_Int64 : AnyTypeOf<[I64, TF_Int64Ref], "64-bit integer">;
|
||||
def TF_I32OrI64 : AnyTypeOf<[I32, I64, TF_Int32Ref, TF_Int64Ref],
|
||||
"32/64-bit signed integer">;
|
||||
|
||||
def TF_Uint8 : AnyTypeOf<[UI<8>, TF_Uint8Ref], "8-bit unsigned integer">;
|
||||
def TF_Uint16 : AnyTypeOf<[UI<16>, TF_Uint16Ref], "16-bit unsigned integer">;
|
||||
def TF_Uint32 : AnyTypeOf<[UI<32>, TF_Uint32Ref], "32-bit unsigned integer">;
|
||||
def TF_Uint64 : AnyTypeOf<[UI<64>, TF_Uint64Ref], "64-bit unsigned integer">;
|
||||
|
||||
// Any unsigned integer type
|
||||
def TF_UInt : AnyTypeOf<[TF_Uint8, TF_Uint16, TF_Uint32, TF_Uint64],
|
||||
"unsigned integer">;
|
||||
|
||||
// Any signed integer type
|
||||
def TF_SInt : AnyTypeOf<[TF_Int8, TF_Int16, TF_Int32, TF_Int64],
|
||||
"signed integer">;
|
||||
|
||||
// Any integer type
|
||||
def TF_Int : AnyTypeOf<[TF_SInt, TF_UInt], "integer">;
|
||||
|
||||
// Tensor types
|
||||
def TF_BoolTensor : TensorOf<[TF_Bool]>;
|
||||
|
||||
def TF_IntTensor : TensorOf<[TF_Int]>;
|
||||
def TF_Int8Tensor : TensorOf<[TF_Int8]>;
|
||||
def TF_Int16Tensor : TensorOf<[TF_Int16]>;
|
||||
def TF_Int32Tensor : TensorOf<[TF_Int32]>;
|
||||
def TF_Int64Tensor : TensorOf<[TF_Int64]>;
|
||||
def TF_I32OrI64Tensor : TensorOf<[TF_I32OrI64]>;
|
||||
|
||||
def TF_Uint8Tensor : TensorOf<[TF_Uint8]>;
|
||||
def TF_Uint16Tensor : TensorOf<[TF_Uint16]>;
|
||||
def TF_Uint32Tensor : TensorOf<[TF_Uint32]>;
|
||||
def TF_Uint64Tensor : TensorOf<[TF_Uint64]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Quantized types (including corresponding reference types)
|
||||
|
||||
def TF_Qint8 : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Qint8", "qint8">, TF_Qint8Ref],
|
||||
"8-bit quantized integer">;
|
||||
def TF_Qint16 : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Qint16", "qint16">, TF_Qint16Ref],
|
||||
"16-bit quantized integer">;
|
||||
def TF_Qint32 : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Qint32", "qint32">, TF_Qint32Ref],
|
||||
"32-bit quantized integer">;
|
||||
def TF_Quint8 : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Quint8", "quint8">, TF_Quint8Ref],
|
||||
"8-bit quantized unsigned integer">;
|
||||
def TF_Quint16 : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Quint16", "quint16">, TF_Quint16Ref],
|
||||
"16-bit quantized unsigned integer">;
|
||||
|
||||
// Any quantized type
|
||||
def TF_Quantized : AnyTypeOf<
|
||||
[TF_Qint8, TF_Qint16, TF_Qint32, TF_Quint8, TF_Quint16], "quantized">;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Floating-point types (including corresponding reference types)
|
||||
|
||||
def TF_Float16 : AnyTypeOf<[F16, TF_Float16Ref], "16-bit float">;
|
||||
def TF_Float32 : AnyTypeOf<[F32, TF_Float32Ref], "32-bit float">;
|
||||
def TF_Float64 : AnyTypeOf<[F64, TF_Float64Ref], "64-bit float">;
|
||||
def TF_Bfloat16 : AnyTypeOf<[BF16, TF_Bfloat16Ref], "bfloat16">;
|
||||
|
||||
def TF_F32OrF64 : AnyTypeOf<[TF_Float32, TF_Float64], "32/64-bit float">;
|
||||
|
||||
def TF_Float : AnyTypeOf<
|
||||
[TF_Float16, TF_Float32, TF_Float64, TF_Bfloat16],
|
||||
"floating-point">;
|
||||
|
||||
// Tensor types
|
||||
def TF_FloatTensor : TensorOf<[TF_Float]>;
|
||||
def TF_F32OrF64Tensor : TensorOf<[TF_F32OrF64]>;
|
||||
def TF_Float16Tensor : TensorOf<[TF_Float16]>;
|
||||
def TF_Float32Tensor : TensorOf<[TF_Float32]>;
|
||||
def TF_Float64Tensor : TensorOf<[TF_Float64]>;
|
||||
def TF_Bfloat16Tensor : TensorOf<[TF_Bfloat16]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Complex types (including corresponding reference types)
|
||||
|
||||
// TODO(suderman): Remove TF_Complex64 and use a standard ops declaration, along
|
||||
// with the associated cleanup.
|
||||
def TF_Complex64 : AnyTypeOf<[Complex<F<32>>, TF_Complex64Ref],
|
||||
"64-bit complex">;
|
||||
def TF_Complex128 : AnyTypeOf<[Complex<F<64>>, TF_Complex128Ref],
|
||||
"128-bit complex">;
|
||||
def TF_Complex : AnyTypeOf<[TF_Complex64, TF_Complex128], "complex">;
|
||||
|
||||
// Tensor types
|
||||
def TF_ComplexTensor : TensorOf<[TF_Complex]>;
|
||||
def TF_Complex64Tensor : TensorOf<[TF_Complex64]>;
|
||||
def TF_Complex128Tensor : TensorOf<[TF_Complex128]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// String/variant/resource types (including corresponding reference types)
|
||||
|
||||
def TF_Str : AnyTypeOf<
|
||||
[TF_TensorFlowType<"String", "str">, TF_StrRef], "string">;
|
||||
def TF_StrTensor : TensorOf<[TF_Str]>;
|
||||
|
||||
def TF_Variant : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Variant", "var">, TF_VariantRef], "variant">;
|
||||
def TF_VariantTensor : TensorOf<[TF_Variant]>;
|
||||
|
||||
def TF_Resource : AnyTypeOf<
|
||||
[TF_TensorFlowType<"Resource", "res">, TF_ResourceRef], "resource">;
|
||||
def TF_ResourceTensor : TensorOf<[TF_Resource]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Multi-category type constraints
|
||||
|
||||
def TF_IntOrF32OrF64Tensor: TensorOf<[TF_Int, TF_F32OrF64]>;
|
||||
def TF_FpOrI32OrI64Tensor : TensorOf<[TF_Float, TF_I32OrI64]>;
|
||||
def TF_IntOrFpTensor : TensorOf<[TF_Int, TF_Float]>;
|
||||
def TF_SintOrFpTensor : TensorOf<[TF_SInt, TF_Float]>;
|
||||
def TF_FpOrComplexTensor : TensorOf<[TF_Float, TF_Complex]>;
|
||||
|
||||
def TF_Number : AnyTypeOf<
|
||||
[TF_Int, TF_Float, TF_Quantized, TF_Complex], "number">;
|
||||
def TF_NumberTensor : TensorOf<[TF_Number]>;
|
||||
|
||||
def TF_NumberNotQuantizedOrStr :
|
||||
AnyTypeOf<[TF_Float, TF_SInt, TF_Complex, TF_Uint8, TF_Str]>;
|
||||
def TF_NumberNotQuantizedOrStrTensor : TensorOf<[TF_NumberNotQuantizedOrStr]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Tensor and tensor element types
|
||||
|
||||
// Any tensor element type allowed in TensorFlow ops
|
||||
// (see https://www.tensorflow.org/api_docs/python/tf/dtypes/DType)
|
||||
def TF_ElementType : Type<Or<[TF_Float.predicate,
|
||||
TF_Complex.predicate,
|
||||
TF_Int.predicate,
|
||||
TF_Bool.predicate,
|
||||
TF_TFDialectType.predicate]>,
|
||||
"tf.dtype">;
|
||||
|
||||
// Any TensorFlow tensor type
|
||||
def TF_Tensor : TensorOf<[TF_ElementType]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow attribute definitions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Tensorflow devices metadata
|
||||
|
||||
// Tensorflow GPU device metadata.
|
||||
def TF_GpuDeviceMetadata : StructAttr<"GpuDeviceMetadata", TF_Dialect, [
|
||||
// GPU device compute capability: major:minor.
|
||||
StructFieldAttr<"cc_major", I32Attr>,
|
||||
StructFieldAttr<"cc_minor", I32Attr>
|
||||
]>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// String attribute constraints
|
||||
|
||||
// A string attribute whose value are one of the values in `cases`.
|
||||
class TF_AnyStrAttrOf<list<string> cases> : StringBasedAttr<
|
||||
CPred<!foldl(
|
||||
"$_self.cast<StringAttr>().getValue() == \"" # !head(cases) # "\"",
|
||||
!foreach(case, !tail(cases),
|
||||
"$_self.cast<StringAttr>().getValue() == \"" # case # "\""),
|
||||
prev, cur, prev # " || " # cur)>,
|
||||
"string attribute whose value is " #
|
||||
!foldl(/*init*/!head(cases), /*list*/!tail(cases),
|
||||
prev, cur, prev # ", or " # cur)>;
|
||||
|
||||
// TODO: Use EnumAttr to define the common attribute cases
|
||||
|
||||
def TF_ConvnetDataFormatAttr : StringBasedAttr<
|
||||
CPred<"$_self.cast<StringAttr>().getValue() == \"NHWC\" || " #
|
||||
"$_self.cast<StringAttr>().getValue() == \"NCHW\"">,
|
||||
"'NHWC' or 'NCHW' convnet data format">;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Type attributes
|
||||
|
||||
// A derived attribute that returns the size of `idx`-th ODS-declared variadic
|
||||
// operand.
|
||||
class TF_DerivedOperandSizeAttr<int idx> : DerivedAttr<
|
||||
"size_t",
|
||||
"auto range = getODSOperands(" # idx # ");\n"
|
||||
"return std::distance(range.begin(), range.end());",
|
||||
[{ $_builder.getI64IntegerAttr($_self) }]>;
|
||||
|
||||
// A derived attribute that returns the element type of `idx`-th ODS-declared
|
||||
// operand. If the `idx`-th operand is a variadic operand, then this attribute
|
||||
// just returns the element type of its first tensor, which is only meaningful
|
||||
// when the variadic operand has at least one tensor and the tensors all have
|
||||
// the same element type.
|
||||
class TF_DerivedOperandTypeAttr<int idx> : DerivedTypeAttr<
|
||||
"return mlir::getElementTypeOrSelf(*getODSOperands(" # idx # ").begin());">;
|
||||
|
||||
// A derived attribute that returns the element types of the tensors in the
|
||||
// actual value pack that corresponds to the `idx`-th ODS-declared variadic
|
||||
// operand. This returns a list of element types so it is used for variadic
|
||||
// operands that can have different element types.
|
||||
class TF_DerivedOperandTypeListAttr<int idx> : DerivedAttr<
|
||||
"mlir::OperandElementTypeRange",
|
||||
"auto values = getODSOperands(" # idx # ");\n"
|
||||
"return {mlir::OperandElementTypeIterator(values.begin()), "
|
||||
"mlir::OperandElementTypeIterator(values.end())};",
|
||||
[{
|
||||
ArrayAttr::get($_ctx,
|
||||
[&]() {
|
||||
llvm::SmallVector<Attribute, 4> ret;
|
||||
for (auto t : $_self)
|
||||
ret.push_back(TypeAttr::get(t));
|
||||
return ret;
|
||||
}())
|
||||
}]
|
||||
>;
|
||||
|
||||
// A derived attribute that returns the shapes of the tensors in the actual
|
||||
// value pack that corresponds to the `idx`-th ODS-declared variadic operand.
|
||||
// This returns a list of shapes so it is used for variadic operands that
|
||||
// can have different shapes.
|
||||
class TF_DerivedOperandShapeListAttr<int idx> : DerivedAttr<
|
||||
"::mlir::TF::OperandShapeRange",
|
||||
"auto values = getODSOperands(" # idx # ");\n"
|
||||
"return {mlir::TF::OperandShapeIterator(values.begin()), "
|
||||
"mlir::TF::OperandShapeIterator(values.end())};",
|
||||
[{
|
||||
ArrayAttr::get($_ctx,
|
||||
[&](){
|
||||
llvm::SmallVector<Attribute, 4> ret;
|
||||
for (auto shape : $_self)
|
||||
ret.push_back(mlir::TF::ShapeAttr::get($_ctx, shape));
|
||||
return ret;
|
||||
}())
|
||||
}]
|
||||
>;
|
||||
|
||||
// A derived attribute that returns the size of `idx`-th ODS-declared variadic
|
||||
// result.
|
||||
class TF_DerivedResultSizeAttr<int idx> : DerivedAttr<
|
||||
"size_t",
|
||||
"auto range = getODSResults(" # idx # ");\n"
|
||||
"return std::distance(range.begin(), range.end());",
|
||||
[{ $_builder.getI64IntegerAttr($_self) }]>;
|
||||
|
||||
// A derived attribute that returns the element type of `idx`-th ODS-declared
|
||||
// result. If the `idx`-th result is a variadic result, then this attribute
|
||||
// just returns the element type of its first tensor, which is only meaningful
|
||||
// when the variadic result has at least one tensor and the tensors all have
|
||||
// the same element type.
|
||||
class TF_DerivedResultTypeAttr<int idx> : DerivedTypeAttr<
|
||||
"return mlir::getElementTypeOrSelf(*getODSResults(" # idx # ").begin());">;
|
||||
|
||||
// A derived attribute that returns the element types of the tensors in the
|
||||
// actual value pack that corresponds to the `idx`-th ODS-declared variadic
|
||||
// result. This returns a list of element types so it is used for variadic
|
||||
// results that can have different element types.
|
||||
class TF_DerivedResultTypeListAttr<int idx> : DerivedAttr<
|
||||
"mlir::ResultElementTypeRange",
|
||||
"auto values = getODSResults(" # idx # ");\n"
|
||||
"return {mlir::ResultElementTypeIterator(values.begin()), "
|
||||
"mlir::ResultElementTypeIterator(values.end())};",
|
||||
[{
|
||||
ArrayAttr::get($_ctx,
|
||||
[&]() {
|
||||
llvm::SmallVector<Attribute, 4> ret;
|
||||
for (auto t : $_self)
|
||||
ret.push_back(TypeAttr::get(t));
|
||||
return ret;
|
||||
}())
|
||||
}]
|
||||
>;
|
||||
|
||||
// A derived attribute that returns the shapes of the tensors in the actual
|
||||
// value pack that corresponds to the `idx`-th ODS-declared variadic result.
|
||||
// This returns a list of shapes so it is used for variadic results that
|
||||
// can have different shapes.
|
||||
class TF_DerivedResultShapeListAttr<int idx> : DerivedAttr<
|
||||
"mlir::TF::ResultShapeRange",
|
||||
"auto values = getODSResults(" # idx # ");\n"
|
||||
"return {mlir::TF::ResultShapeIterator(values.begin()), "
|
||||
"mlir::TF::ResultShapeIterator(values.end())};",
|
||||
[{
|
||||
ArrayAttr::get($_ctx,
|
||||
[&](){
|
||||
llvm::SmallVector<Attribute, 4> ret;
|
||||
for (auto shape : $_self)
|
||||
ret.push_back(mlir::TF::ShapeAttr::get($_ctx, shape));
|
||||
return ret;
|
||||
}())
|
||||
}]
|
||||
>;
|
||||
|
||||
// A derived attribute that returns the shape of the first result type.
|
||||
def TF_DerivedResultShapeAttr : DerivedAttr<"ShapedType",
|
||||
"return (*getOperation()->result_type_begin()).cast<ShapedType>();",
|
||||
[{ mlir::TF::ShapeAttr::get($_ctx, $_self) }]>;
|
||||
|
||||
def TF_IntTypeAttr : TypeAttrBase<"IntegerType", "integer type"> {
|
||||
let returnType = "Type";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow common builders
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
// Mixin class defining a builder for binary ops supporting broadcast
|
||||
// behavior. The result type has the same element type as both operands.
|
||||
class WithBroadcastableBinOpBuilder {
|
||||
list<OpBuilder> builders = [
|
||||
OpBuilder<(ins "Value":$x, "Value":$y),
|
||||
[{
|
||||
auto resultType =
|
||||
OpTrait::util::getBroadcastedType(x.getType(), y.getType());
|
||||
if (!resultType)
|
||||
mlir::emitError($_state.location, "non-broadcastable operands");
|
||||
return build($_builder, $_state, resultType, x, y);
|
||||
}]>];
|
||||
}
|
||||
|
||||
// Mixin class defining a builder for comparison ops supporting broadcast
|
||||
// behavior. The result type has bool element type.
|
||||
class WithBroadcastableCmpOpBuilder {
|
||||
list<OpBuilder> builders = [
|
||||
OpBuilder<(ins "Value":$x, "Value":$y),
|
||||
[{
|
||||
Type resultType;
|
||||
if (x.getType().isa<UnrankedTensorType>() ||
|
||||
y.getType().isa<UnrankedTensorType>()) {
|
||||
resultType = UnrankedTensorType::get($_builder.getI1Type());
|
||||
} else {
|
||||
SmallVector<int64_t, 4> resultShape;
|
||||
if (!OpTrait::util::getBroadcastedShape(
|
||||
x.getType().cast<ShapedType>().getShape(),
|
||||
y.getType().cast<ShapedType>().getShape(), resultShape)) {
|
||||
mlir::emitError($_state.location,
|
||||
"operands have no broadcastable shapes");
|
||||
}
|
||||
|
||||
resultType = RankedTensorType::get(resultShape, $_builder.getI1Type());
|
||||
}
|
||||
return build($_builder, $_state, resultType, x, y);
|
||||
}]>];
|
||||
}
|
||||
|
||||
#endif // TF_OP_BASE
|
||||
2037
3rdparty/ncnn/tools/mlir/tf_ops.td
vendored
Normal file
2037
3rdparty/ncnn/tools/mlir/tf_ops.td
vendored
Normal file
File diff suppressed because it is too large
Load Diff
106
3rdparty/ncnn/tools/mlir/tf_side_effects.h
vendored
Normal file
106
3rdparty/ncnn/tools/mlir/tf_side_effects.h
vendored
Normal file
@@ -0,0 +1,106 @@
|
||||
/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
// This is the side effect definition file for TensorFlow.
|
||||
#ifndef TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_SIDE_EFFECTS_H_
|
||||
#define TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_SIDE_EFFECTS_H_
|
||||
|
||||
#include "mlir/Interfaces/SideEffectInterfaces.h" // from @llvm-project
|
||||
|
||||
namespace mlir {
|
||||
namespace TF {
|
||||
namespace ResourceEffects {
|
||||
|
||||
struct Variable : ::mlir::SideEffects::Resource::Base<Variable>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "Variable";
|
||||
}
|
||||
};
|
||||
|
||||
struct Stack : ::mlir::SideEffects::Resource::Base<Stack>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "Stack";
|
||||
}
|
||||
};
|
||||
|
||||
struct TensorArray : ::mlir::SideEffects::Resource::Base<TensorArray>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "TensorArray";
|
||||
}
|
||||
};
|
||||
|
||||
struct Summary : ::mlir::SideEffects::Resource::Base<Summary>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "Summary";
|
||||
}
|
||||
};
|
||||
|
||||
struct LookupTable : ::mlir::SideEffects::Resource::Base<LookupTable>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "LookupTable";
|
||||
}
|
||||
};
|
||||
|
||||
struct DatasetSeedGenerator
|
||||
: ::mlir::SideEffects::Resource::Base<DatasetSeedGenerator>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "DatasetSeedGenerator";
|
||||
}
|
||||
};
|
||||
|
||||
struct DatasetMemoryCache
|
||||
: ::mlir::SideEffects::Resource::Base<DatasetMemoryCache>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "DatasetMemoryCache";
|
||||
}
|
||||
};
|
||||
|
||||
struct DatasetIterator : ::mlir::SideEffects::Resource::Base<DatasetIterator>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "DatasetIterator";
|
||||
}
|
||||
};
|
||||
|
||||
// Special resource type to track TPU Embedding specific ops, which must execute
|
||||
// but do not have side effects with one another or with resource variable ops.
|
||||
struct TPUEmbedding : ::mlir::SideEffects::Resource::Base<TPUEmbedding>
|
||||
{
|
||||
StringRef getName() final
|
||||
{
|
||||
return "TPUEmbedding";
|
||||
}
|
||||
};
|
||||
|
||||
} // namespace ResourceEffects
|
||||
} // namespace TF
|
||||
} // namespace mlir
|
||||
|
||||
#endif // TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_SIDE_EFFECTS_H_
|
||||
189
3rdparty/ncnn/tools/mlir/tf_traits.h
vendored
Normal file
189
3rdparty/ncnn/tools/mlir/tf_traits.h
vendored
Normal file
@@ -0,0 +1,189 @@
|
||||
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
// This file defines the op traits used in the MLIR TensorFlow dialect.
|
||||
|
||||
#ifndef TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_TRAITS_H_
|
||||
#define TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_TRAITS_H_
|
||||
|
||||
#include "mlir/IR/BuiltinTypes.h" // from @llvm-project
|
||||
#include "mlir/IR/OpDefinition.h" // from @llvm-project
|
||||
#include "mlir/IR/TypeUtilities.h" // from @llvm-project
|
||||
#include "mlir/Interfaces/SideEffectInterfaces.h" // from @llvm-project
|
||||
#include "mlir/Support/LogicalResult.h" // from @llvm-project
|
||||
#include "tf_types.h"
|
||||
|
||||
namespace mlir {
|
||||
namespace OpTrait {
|
||||
namespace TF {
|
||||
|
||||
// Verifies if 'ref_type' is a REF type corresponding to 'type'.
|
||||
static inline LogicalResult VerifyRefTypeMatch(mlir::Type type,
|
||||
mlir::Type maybe_ref_type)
|
||||
{
|
||||
if (auto ref_type = maybe_ref_type.dyn_cast<mlir::TF::TensorFlowRefType>())
|
||||
return success(ref_type.RemoveRef().getTypeID() == type.getTypeID());
|
||||
return failure();
|
||||
}
|
||||
|
||||
// This class provides verification for ops that are known to have the same
|
||||
// result types and all operands are either of the same type as result or a REF
|
||||
// type corresponding to the result type.
|
||||
// TODO(jpienaar): Update the name and the description.
|
||||
template<typename ConcreteType>
|
||||
class OperandsSameAsResultsTypeOrRef
|
||||
: public TraitBase<ConcreteType, OperandsSameAsResultsTypeOrRef>
|
||||
{
|
||||
public:
|
||||
static LogicalResult verifyTrait(Operation* op)
|
||||
{
|
||||
LogicalResult shapeMatch = impl::verifySameOperandsAndResultShape(op);
|
||||
if (failed(shapeMatch)) return shapeMatch;
|
||||
Type type = op->getResult(0).getType();
|
||||
// Verify that the first result type is same as the rest of the results.
|
||||
// We skip the comparison against itself.
|
||||
for (auto result_type : llvm::drop_begin(op->getResultTypes(), 1))
|
||||
{
|
||||
if (!mlir::TF::HasCompatibleElementTypes(type, result_type))
|
||||
return op->emitOpError()
|
||||
<< "requires all return types to have compatible element types";
|
||||
}
|
||||
for (auto operand_type : op->getOperandTypes())
|
||||
{
|
||||
if (!mlir::TF::HasCompatibleElementTypes(
|
||||
operand_type, type, /*may_ignore_ref_type_lhs=*/true))
|
||||
return op->emitError() << "requires all operands and results to have "
|
||||
"compatible element types";
|
||||
}
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
namespace detail {
|
||||
inline LogicalResult verifySameOperandsAndResultElementTypeResolveRef(
|
||||
Operation* op)
|
||||
{
|
||||
Type element_type;
|
||||
if (op->getNumResults() > 0)
|
||||
{
|
||||
element_type = mlir::TF::GetElementTypeOrSelfResolveRef(op->getResult(0).getType());
|
||||
}
|
||||
else if (op->getNumOperands() > 0)
|
||||
{
|
||||
element_type = mlir::TF::GetElementTypeOrSelfResolveRef(op->getOperand(0).getType());
|
||||
}
|
||||
else
|
||||
{
|
||||
// Nothing to check.
|
||||
return success();
|
||||
}
|
||||
// Verify that all result element types are compatible to `element_type`.
|
||||
for (const auto& result_type : op->getResultTypes())
|
||||
{
|
||||
if (mlir::TF::GetElementTypeOrSelfResolveRef(result_type) != element_type)
|
||||
{
|
||||
return op->emitOpError(
|
||||
"requires compatible element types for all operands and results");
|
||||
}
|
||||
}
|
||||
// Verify that all operand element types are compatible to `element_type`.
|
||||
for (const auto& operand_type : op->getOperandTypes())
|
||||
{
|
||||
if (mlir::TF::GetElementTypeOrSelfResolveRef(operand_type) != element_type)
|
||||
{
|
||||
return op->emitOpError(
|
||||
"requires compatible element types for all operands and results");
|
||||
}
|
||||
}
|
||||
return success();
|
||||
}
|
||||
} // namespace detail
|
||||
|
||||
// Verifies that op has the same operand and result element types (or type
|
||||
// itself, if scalar) after resolving reference types (i.e., after converting
|
||||
// reference types to their corresponding TensorFlow or standard types).
|
||||
template<typename ConcreteType>
|
||||
class SameOperandsAndResultElementTypeResolveRef
|
||||
: public TraitBase<ConcreteType,
|
||||
SameOperandsAndResultElementTypeResolveRef>
|
||||
{
|
||||
public:
|
||||
static LogicalResult verifyTrait(Operation* op)
|
||||
{
|
||||
return detail::verifySameOperandsAndResultElementTypeResolveRef(op);
|
||||
}
|
||||
};
|
||||
|
||||
// Verifies that op has the same operand and result types after resolving
|
||||
// reference types (i.e., after converting reference types to their
|
||||
// corresponding TensorFlow or standard types).
|
||||
template<typename ConcreteType>
|
||||
class SameOperandsAndResultTypeResolveRef
|
||||
: public TraitBase<ConcreteType, SameOperandsAndResultTypeResolveRef>
|
||||
{
|
||||
public:
|
||||
static LogicalResult verifyTrait(Operation* op)
|
||||
{
|
||||
if (failed(impl::verifySameOperandsAndResultShape(op))) return failure();
|
||||
return detail::verifySameOperandsAndResultElementTypeResolveRef(op);
|
||||
}
|
||||
};
|
||||
|
||||
// Layout agnostic operations do not depend on the operands data layout (data
|
||||
// format), as and example all element wise operations are layout agnostic.
|
||||
template<typename ConcreteType>
|
||||
class LayoutAgnostic : public TraitBase<ConcreteType, LayoutAgnostic>
|
||||
{
|
||||
};
|
||||
|
||||
// Trait to indicate operations that cannot be duplicated as they might carry
|
||||
// certain state around within their implementations.
|
||||
template<typename ConcreteType>
|
||||
class CannotDuplicate : public TraitBase<ConcreteType, CannotDuplicate>
|
||||
{
|
||||
public:
|
||||
static LogicalResult verifyTrait(Operation* op)
|
||||
{
|
||||
if (MemoryEffectOpInterface::hasNoEffect(op))
|
||||
return op->emitError(
|
||||
"operations with no side effects cannot have CannotDuplicate trait");
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
// Trait to indicate an operation cannot be constant folded.
|
||||
template<typename ConcreteType>
|
||||
class NoConstantFold : public TraitBase<ConcreteType, NoConstantFold>
|
||||
{
|
||||
};
|
||||
|
||||
// Coefficient-wise binary operation with implicit broadcasting support, for
|
||||
// example tf.Sub operation.
|
||||
template<typename ConcreteType>
|
||||
class CwiseBinary : public TraitBase<ConcreteType, CwiseBinary>
|
||||
{
|
||||
};
|
||||
|
||||
// Coefficient-wise unary operation, for example tf.Sqrt operation.
|
||||
template<typename ConcreteType>
|
||||
class CwiseUnary : public TraitBase<ConcreteType, CwiseUnary>
|
||||
{
|
||||
};
|
||||
|
||||
} // namespace TF
|
||||
} // namespace OpTrait
|
||||
} // namespace mlir
|
||||
|
||||
#endif // TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_TRAITS_H_
|
||||
462
3rdparty/ncnn/tools/mlir/tf_types.cc
vendored
Normal file
462
3rdparty/ncnn/tools/mlir/tf_types.cc
vendored
Normal file
@@ -0,0 +1,462 @@
|
||||
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
#include "tf_types.h"
|
||||
|
||||
#include "llvm/Support/ErrorHandling.h"
|
||||
#include "mlir/Dialect/Traits.h" // from @llvm-project
|
||||
#include "mlir/IR/BuiltinTypes.h" // from @llvm-project
|
||||
#include "mlir/IR/Dialect.h" // from @llvm-project
|
||||
#include "mlir/IR/TypeUtilities.h" // from @llvm-project
|
||||
|
||||
namespace {
|
||||
// Returns the shape of the given value if it's ranked; returns llvm::None
|
||||
// otherwise.
|
||||
llvm::Optional<llvm::ArrayRef<int64_t> > GetShape(mlir::Value value)
|
||||
{
|
||||
auto shaped_type = value.getType().cast<mlir::ShapedType>();
|
||||
if (shaped_type.hasRank()) return shaped_type.getShape();
|
||||
return llvm::None;
|
||||
}
|
||||
|
||||
// Merges cast compatible shapes and returns a more refined shape. The two
|
||||
// shapes are cast compatible if they have the same rank and at each dimension,
|
||||
// either both have same size or one of them is dynamic. Returns false if the
|
||||
// given shapes are not cast compatible. The refined shape is same or more
|
||||
// precise than the two input shapes.
|
||||
bool GetCastCompatibleShape(llvm::ArrayRef<int64_t> a_shape,
|
||||
llvm::ArrayRef<int64_t> b_shape,
|
||||
llvm::SmallVectorImpl<int64_t>* refined_shape)
|
||||
{
|
||||
if (a_shape.size() != b_shape.size()) return false;
|
||||
int64_t rank = a_shape.size();
|
||||
refined_shape->reserve(rank);
|
||||
for (auto dims : llvm::zip(a_shape, b_shape))
|
||||
{
|
||||
int64_t dim1 = std::get<0>(dims);
|
||||
int64_t dim2 = std::get<1>(dims);
|
||||
|
||||
if (mlir::ShapedType::isDynamic(dim1))
|
||||
{
|
||||
refined_shape->push_back(dim2);
|
||||
continue;
|
||||
}
|
||||
if (mlir::ShapedType::isDynamic(dim2))
|
||||
{
|
||||
refined_shape->push_back(dim1);
|
||||
continue;
|
||||
}
|
||||
if (dim1 == dim2)
|
||||
{
|
||||
refined_shape->push_back(dim1);
|
||||
continue;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
} // namespace
|
||||
|
||||
namespace mlir {
|
||||
namespace TF {
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Utility iterators
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
OperandShapeIterator::OperandShapeIterator(Operation::operand_iterator it)
|
||||
: llvm::mapped_iterator<Operation::operand_iterator,
|
||||
llvm::Optional<ArrayRef<int64_t> > (*)(Value)>(
|
||||
it, &GetShape)
|
||||
{
|
||||
}
|
||||
|
||||
ResultShapeIterator::ResultShapeIterator(Operation::result_iterator it)
|
||||
: llvm::mapped_iterator<Operation::result_iterator,
|
||||
llvm::Optional<ArrayRef<int64_t> > (*)(Value)>(
|
||||
it, &GetShape)
|
||||
{
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TF types helper functions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
bool TensorFlowType::classof(Type type)
|
||||
{
|
||||
return type.getDialect().getNamespace() == "tf";
|
||||
}
|
||||
bool TensorFlowRefType::classof(Type type)
|
||||
{
|
||||
return type.isa<
|
||||
#define HANDLE_TF_TYPE(tftype, enumerant, name)
|
||||
#define HANDLE_TF_REF_TYPE(tftype, enumerant, name) tftype##Type,
|
||||
#define HANDLE_LAST_TF_TYPE(tftype, enumerant, name) tftype##Type
|
||||
// NOLINTNEXTLINE
|
||||
#include "tf_types.def"
|
||||
>();
|
||||
}
|
||||
bool TensorFlowTypeWithSubtype::classof(Type type)
|
||||
{
|
||||
return type.isa<ResourceType, VariantType>();
|
||||
}
|
||||
|
||||
TensorFlowType TensorFlowRefType::get(Type type)
|
||||
{
|
||||
MLIRContext* ctx = type.getContext();
|
||||
type = getElementTypeOrSelf(type);
|
||||
if (type.isF16())
|
||||
{
|
||||
return HalfRefType::get(ctx);
|
||||
}
|
||||
else if (type.isF32())
|
||||
{
|
||||
return FloatRefType::get(ctx);
|
||||
}
|
||||
else if (type.isF64())
|
||||
{
|
||||
return DoubleRefType::get(ctx);
|
||||
}
|
||||
else if (type.isBF16())
|
||||
{
|
||||
return Bfloat16RefType::get(ctx);
|
||||
}
|
||||
else if (auto complex_type = type.dyn_cast<ComplexType>())
|
||||
{
|
||||
Type etype = complex_type.getElementType();
|
||||
if (etype.isF32())
|
||||
{
|
||||
return Complex64RefType::get(ctx);
|
||||
}
|
||||
else if (etype.isF64())
|
||||
{
|
||||
return Complex128RefType::get(ctx);
|
||||
}
|
||||
llvm_unreachable("unexpected complex type");
|
||||
}
|
||||
else if (auto itype = type.dyn_cast<IntegerType>())
|
||||
{
|
||||
switch (itype.getWidth())
|
||||
{
|
||||
case 1:
|
||||
return BoolRefType::get(ctx);
|
||||
case 8:
|
||||
return itype.isUnsigned() ? TensorFlowType(Uint8RefType::get(ctx))
|
||||
: Int8RefType::get(ctx);
|
||||
case 16:
|
||||
return itype.isUnsigned() ? TensorFlowType(Uint16RefType::get(ctx))
|
||||
: Int16RefType::get(ctx);
|
||||
case 32:
|
||||
return itype.isUnsigned() ? TensorFlowType(Uint32RefType::get(ctx))
|
||||
: Int32RefType::get(ctx);
|
||||
case 64:
|
||||
return itype.isUnsigned() ? TensorFlowType(Uint64RefType::get(ctx))
|
||||
: Int64RefType::get(ctx);
|
||||
default:
|
||||
llvm_unreachable("unexpected integer type");
|
||||
}
|
||||
}
|
||||
#define HANDLE_TF_TYPE(tftype, enumerant, name) \
|
||||
if (auto derived_ty = type.dyn_cast<tftype##Type>()) \
|
||||
return tftype##RefType::get(ctx);
|
||||
|
||||
#define HANDLE_TF_REF_TYPE(tftype, enumerant, name)
|
||||
// NOLINTNEXTLINE
|
||||
#include "tf_types.def"
|
||||
llvm_unreachable("unexpected type kind");
|
||||
}
|
||||
|
||||
Type TensorFlowRefType::RemoveRef()
|
||||
{
|
||||
MLIRContext* ctx = getContext();
|
||||
if (isa<HalfRefType>()) return mlir::FloatType::getF16(ctx);
|
||||
if (isa<FloatRefType>()) return mlir::FloatType::getF32(ctx);
|
||||
if (isa<DoubleRefType>()) return mlir::FloatType::getF64(ctx);
|
||||
if (isa<Bfloat16RefType>()) return mlir::FloatType::getBF16(ctx);
|
||||
if (isa<BoolRefType>()) return mlir::IntegerType::get(ctx, 1);
|
||||
if (isa<Int8RefType>()) return mlir::IntegerType::get(ctx, 8);
|
||||
if (isa<Int16RefType>()) return mlir::IntegerType::get(ctx, 16);
|
||||
if (isa<Int32RefType>()) return mlir::IntegerType::get(ctx, 32);
|
||||
if (isa<Int64RefType>()) return mlir::IntegerType::get(ctx, 64);
|
||||
if (isa<Uint8RefType>())
|
||||
return mlir::IntegerType::get(ctx, 8, IntegerType::Unsigned);
|
||||
if (isa<Uint16RefType>())
|
||||
return mlir::IntegerType::get(ctx, 16, IntegerType::Unsigned);
|
||||
if (isa<Uint32RefType>())
|
||||
return mlir::IntegerType::get(ctx, 32, IntegerType::Unsigned);
|
||||
if (isa<Uint64RefType>())
|
||||
return mlir::IntegerType::get(ctx, 64, IntegerType::Unsigned);
|
||||
if (isa<Complex64RefType>())
|
||||
return mlir::ComplexType::get(mlir::FloatType::getF32(ctx));
|
||||
if (isa<Complex128RefType>())
|
||||
return mlir::ComplexType::get(mlir::FloatType::getF64(ctx));
|
||||
#define HANDLE_TF_TYPE(tftype, enumerant, name) \
|
||||
if (isa<tftype##RefType>()) return tftype##Type::get(ctx);
|
||||
|
||||
#define HANDLE_TF_REF_TYPE(tftype, enumerant, name)
|
||||
// NOLINTNEXTLINE
|
||||
#include "tf_types.def"
|
||||
llvm_unreachable("unexpected tensorflow ref type kind");
|
||||
}
|
||||
|
||||
Type TensorFlowTypeWithSubtype::RemoveSubtypes()
|
||||
{
|
||||
MLIRContext* ctx = getContext();
|
||||
if (isa<VariantType>()) return VariantType::get(ctx);
|
||||
if (isa<ResourceType>()) return ResourceType::get(ctx);
|
||||
llvm_unreachable("unexpected tensorflow type with subtypes kind");
|
||||
}
|
||||
|
||||
ArrayRef<TensorType> TensorFlowTypeWithSubtype::GetSubtypes()
|
||||
{
|
||||
if (auto variant_type = dyn_cast<VariantType>())
|
||||
return variant_type.getSubtypes();
|
||||
if (auto resource_type = dyn_cast<ResourceType>())
|
||||
return resource_type.getSubtypes();
|
||||
llvm_unreachable("unexpected tensorflow type with subtypes kind");
|
||||
}
|
||||
|
||||
// TODO(jpienaar): BroadcastCompatible and HasCompatibleElementTypes have
|
||||
// similar structure that could be extracted into helper method.
|
||||
bool BroadcastCompatible(TypeRange lhs, TypeRange rhs)
|
||||
{
|
||||
if (lhs.size() != rhs.size()) return false;
|
||||
for (auto types : llvm::zip(lhs, rhs))
|
||||
{
|
||||
// Drop ref types because they don't affect broadcast compatibility. E.g.,
|
||||
// `tensor<!tf.f32ref>` and `tensor<f32>` should be considered broadcast
|
||||
// compatible.
|
||||
auto lhs_type = DropRefType(std::get<0>(types));
|
||||
auto rhs_type = DropRefType(std::get<1>(types));
|
||||
|
||||
// This should be true for all TF ops:
|
||||
auto lhs_tt = lhs_type.dyn_cast<TensorType>();
|
||||
auto rhs_tt = rhs_type.dyn_cast<TensorType>();
|
||||
if (!lhs_tt || !rhs_tt)
|
||||
{
|
||||
if (lhs_type != rhs_type) return false;
|
||||
continue;
|
||||
}
|
||||
|
||||
// Verify matching element types. These should be identical, except for
|
||||
// variant type where unknown subtype is considered compatible with all
|
||||
// subtypes.
|
||||
auto lhs_et = lhs_tt.getElementType();
|
||||
auto rhs_et = rhs_tt.getElementType();
|
||||
if (lhs_et != rhs_et)
|
||||
{
|
||||
// If either does not have subtypes, then the element types don't match.
|
||||
auto lhs_wst = lhs_et.dyn_cast<TF::TensorFlowTypeWithSubtype>();
|
||||
auto rhs_wst = rhs_et.dyn_cast<TF::TensorFlowTypeWithSubtype>();
|
||||
if (!lhs_wst || !rhs_wst) return false;
|
||||
|
||||
// Consider the subtype of variant types.
|
||||
auto lhs_wst_st = lhs_wst.GetSubtypes();
|
||||
auto rhs_wst_st = rhs_wst.GetSubtypes();
|
||||
if (!lhs_wst_st.empty() && !rhs_wst_st.empty())
|
||||
{
|
||||
for (auto subtypes : llvm::zip(lhs_wst_st, rhs_wst_st))
|
||||
{
|
||||
if (!BroadcastCompatible(std::get<0>(subtypes),
|
||||
std::get<1>(subtypes)))
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
auto lhs_rt = lhs_type.dyn_cast<RankedTensorType>();
|
||||
auto rhs_rt = rhs_type.dyn_cast<RankedTensorType>();
|
||||
if (!lhs_rt || !rhs_rt) return true;
|
||||
SmallVector<int64_t, 4> shape;
|
||||
return OpTrait::util::getBroadcastedShape(lhs_rt.getShape(),
|
||||
rhs_rt.getShape(), shape);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
// Given two types `a` and `b`, returns a refined type which is cast compatible
|
||||
// with both `a` and `b` and is equal to or more precise than both of them. It
|
||||
// returns empty Type if the input types are not cast compatible.
|
||||
//
|
||||
// The two types are considered cast compatible if they have dynamically equal
|
||||
// shapes and element type. For element types that do not have subtypes, they
|
||||
// must be equal. However for TensorFlow types such as Resource and Variant,
|
||||
// that also have subtypes, we recursively check for subtype compatibilty for
|
||||
// Resource types and assume all variant types are cast compatible. If either
|
||||
// one of `a` or `b` have empty subtypes, they are considered cast compatible.
|
||||
//
|
||||
// The returned type is same or more precise than the input types. For example,
|
||||
// if `a` and `b` are cast compatible types tensor<2x?x?xf32> and
|
||||
// tensor<?x4x?xf32> respectively, the returned type is tensor<2x4x?xf32>.
|
||||
//
|
||||
// Provides option to ignore ref types on 'a'. This is useful for TF ops that
|
||||
// might allow operands to either be same as result type or be a ref type
|
||||
// corresponding to it.
|
||||
mlir::Type GetCastCompatibleType(mlir::Type a, mlir::Type b,
|
||||
bool may_ignore_ref_type_a)
|
||||
{
|
||||
// Fast path if everything is equal.
|
||||
if (a == b) return b;
|
||||
|
||||
auto a_tt = a.dyn_cast<mlir::TensorType>();
|
||||
auto b_tt = b.dyn_cast<mlir::TensorType>();
|
||||
|
||||
// If only one of a or b is a tensor type, they are incompatible.
|
||||
if (static_cast<bool>(a_tt) ^ static_cast<bool>(b_tt)) return nullptr;
|
||||
|
||||
// For non-tensor types, we do not need to worry about shape and can return
|
||||
// early.
|
||||
if (!a_tt && !b_tt)
|
||||
{
|
||||
// Remove ref types.
|
||||
if (may_ignore_ref_type_a)
|
||||
{
|
||||
if (auto ref_type = a.dyn_cast<mlir::TF::TensorFlowRefType>())
|
||||
{
|
||||
a = ref_type.RemoveRef();
|
||||
if (a == b) return a;
|
||||
}
|
||||
}
|
||||
if (a.getTypeID() != b.getTypeID()) return nullptr;
|
||||
|
||||
// If either is not a type that contain subtypes then the types are not cast
|
||||
// compatible.
|
||||
auto a_wst = a.dyn_cast<mlir::TF::TensorFlowTypeWithSubtype>();
|
||||
auto b_wst = b.dyn_cast<mlir::TF::TensorFlowTypeWithSubtype>();
|
||||
if (!a_wst || !b_wst) return nullptr;
|
||||
|
||||
// For Variant types we are more permissive right now and accept all pairs
|
||||
// of Variant types. If we are more constrainted and check compatibility of
|
||||
// subtypes, we might reject valid graphs.
|
||||
// TODO(prakalps): Variant doesn't have a subtype, we assign it
|
||||
// one, so we should only assign it one when we know the subtype. Then we
|
||||
// can be more constrained and check subtypes for cast compatibility as
|
||||
// well.
|
||||
if (a.isa<mlir::TF::VariantType>()) return a;
|
||||
|
||||
// For Resource types, we recursively check the subtypes for cast
|
||||
// compatibility, if possible. Otherwise treat them as compatible.
|
||||
auto a_wst_st = a_wst.GetSubtypes();
|
||||
auto b_wst_st = b_wst.GetSubtypes();
|
||||
if (a_wst_st.empty() || b_wst_st.empty()) return a;
|
||||
if (a_wst_st.size() != b_wst_st.size()) return nullptr;
|
||||
llvm::SmallVector<mlir::TensorType, 4> refined_subtypes;
|
||||
for (auto subtypes : llvm::zip(a_wst_st, b_wst_st))
|
||||
{
|
||||
mlir::Type refined_st = GetCastCompatibleType(std::get<0>(subtypes), std::get<1>(subtypes),
|
||||
/*may_ignore_ref_type_a=*/false);
|
||||
if (!refined_st) return nullptr;
|
||||
refined_subtypes.push_back(refined_st.cast<mlir::TensorType>());
|
||||
}
|
||||
|
||||
return mlir::TF::ResourceType::get(refined_subtypes, a.getContext());
|
||||
}
|
||||
|
||||
// For tensor types, check compatibility of both element type and shape.
|
||||
mlir::Type refined_element_ty = GetCastCompatibleType(
|
||||
a_tt.getElementType(), b_tt.getElementType(), may_ignore_ref_type_a);
|
||||
if (!refined_element_ty) return nullptr;
|
||||
|
||||
if (!a_tt.hasRank() && !b_tt.hasRank())
|
||||
{
|
||||
return mlir::UnrankedTensorType::get(refined_element_ty);
|
||||
}
|
||||
if (!a_tt.hasRank())
|
||||
{
|
||||
return mlir::RankedTensorType::get(b_tt.getShape(), refined_element_ty);
|
||||
}
|
||||
if (!b_tt.hasRank())
|
||||
{
|
||||
return mlir::RankedTensorType::get(a_tt.getShape(), refined_element_ty);
|
||||
}
|
||||
|
||||
llvm::SmallVector<int64_t, 8> refined_shape;
|
||||
if (!GetCastCompatibleShape(a_tt.getShape(), b_tt.getShape(), &refined_shape))
|
||||
return nullptr;
|
||||
|
||||
return mlir::RankedTensorType::get(refined_shape, refined_element_ty);
|
||||
}
|
||||
|
||||
bool HasCompatibleElementTypes(Type lhs, Type rhs,
|
||||
bool may_ignore_ref_type_lhs)
|
||||
{
|
||||
return GetCastCompatibleType(lhs, rhs, may_ignore_ref_type_lhs) != nullptr;
|
||||
}
|
||||
|
||||
bool AreCastCompatible(TypeRange types)
|
||||
{
|
||||
Type common = types.front();
|
||||
for (auto type : types.drop_front())
|
||||
{
|
||||
Type refined_type = GetCastCompatibleType(common, type, /*may_ignore_ref_type_a=*/false);
|
||||
if (!refined_type) return false;
|
||||
common = refined_type;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
bool ArraysAreCastCompatible(TypeRange lhs, TypeRange rhs)
|
||||
{
|
||||
if (lhs.size() != rhs.size()) return false;
|
||||
for (auto pair : llvm::zip(lhs, rhs))
|
||||
{
|
||||
auto lhs_i = std::get<0>(pair);
|
||||
auto rhs_i = std::get<1>(pair);
|
||||
if (!AreCastCompatible({lhs_i, rhs_i})) return false;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
// Assumes a function `GetDefaultTypeOf(ComposedType)` that returns the default
|
||||
// type for a composed type (such as a ref type or a type with subtypes).
|
||||
template<typename ComposedType>
|
||||
Type DropTypeHelper(Type ty)
|
||||
{
|
||||
Type element_ty = getElementTypeOrSelf(ty);
|
||||
auto composed_type = element_ty.dyn_cast<ComposedType>();
|
||||
if (!composed_type) return ty;
|
||||
|
||||
Type default_ty = GetDefaultTypeOf(composed_type);
|
||||
if (auto ranked_ty = ty.dyn_cast<RankedTensorType>())
|
||||
{
|
||||
return RankedTensorType::get(ranked_ty.getShape(), default_ty);
|
||||
}
|
||||
else if (ty.dyn_cast<UnrankedTensorType>())
|
||||
{
|
||||
return UnrankedTensorType::get(default_ty);
|
||||
}
|
||||
else
|
||||
{
|
||||
return default_ty;
|
||||
}
|
||||
}
|
||||
|
||||
Type DropSubTypes(Type ty)
|
||||
{
|
||||
return DropTypeHelper<TF::TensorFlowTypeWithSubtype>(ty);
|
||||
}
|
||||
|
||||
Type DropRefType(Type ty)
|
||||
{
|
||||
return DropTypeHelper<TF::TensorFlowRefType>(ty);
|
||||
}
|
||||
|
||||
Type DropRefAndSubTypes(Type ty)
|
||||
{
|
||||
return DropRefType(DropSubTypes(ty));
|
||||
}
|
||||
|
||||
} // namespace TF
|
||||
} // namespace mlir
|
||||
77
3rdparty/ncnn/tools/mlir/tf_types.def
vendored
Normal file
77
3rdparty/ncnn/tools/mlir/tf_types.def
vendored
Normal file
@@ -0,0 +1,77 @@
|
||||
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
// This file contains descriptions of the various TensorFlow types. This is
|
||||
// used as a central place for enumerating the different types.
|
||||
|
||||
#ifdef HANDLE_TF_TYPE
|
||||
|
||||
// class, enumerant, name
|
||||
HANDLE_TF_TYPE(Qint8, QINT8, "qint8")
|
||||
HANDLE_TF_TYPE(Qint16, QINT16, "qint16")
|
||||
HANDLE_TF_TYPE(Qint32, QINT32, "qint32")
|
||||
HANDLE_TF_TYPE(Quint8, QUINT8, "quint8")
|
||||
HANDLE_TF_TYPE(Quint16, QUINT16, "quint16")
|
||||
HANDLE_TF_TYPE(String, STRING, "string")
|
||||
|
||||
#ifndef HANDLE_CUSTOM_TF_TYPE
|
||||
#define HANDLE_CUSTOM_TF_TYPE(class, enumerant, name) \
|
||||
HANDLE_TF_TYPE(class, enumerant, name)
|
||||
#endif
|
||||
HANDLE_CUSTOM_TF_TYPE(Resource, RESOURCE, "resource")
|
||||
HANDLE_CUSTOM_TF_TYPE(Variant, VARIANT, "variant")
|
||||
#undef HANDLE_CUSTOM_TF_TYPE
|
||||
|
||||
// All ref types are listed below this line and FloatRef is the first ref type.
|
||||
// This helps in easily differentiating ref and non-ref types, and converting
|
||||
// a type to/from ref types.
|
||||
|
||||
#ifndef HANDLE_TF_REF_TYPE
|
||||
#define HANDLE_TF_REF_TYPE(class, enumerant, name) \
|
||||
HANDLE_TF_TYPE(class, enumerant, name)
|
||||
#endif
|
||||
HANDLE_TF_REF_TYPE(FloatRef, FLOAT_REF, "f32ref")
|
||||
HANDLE_TF_REF_TYPE(DoubleRef, DOUBLE_REF, "f64ref")
|
||||
HANDLE_TF_REF_TYPE(Uint8Ref, UINT8_REF, "uint8ref")
|
||||
HANDLE_TF_REF_TYPE(Int8Ref, INT8_REF, "int8ref")
|
||||
HANDLE_TF_REF_TYPE(Uint16Ref, UINT16_REF, "uint16ref")
|
||||
HANDLE_TF_REF_TYPE(Int16Ref, INT16_REF, "int16ref")
|
||||
HANDLE_TF_REF_TYPE(Uint32Ref, UINT32_REF, "uint32ref")
|
||||
HANDLE_TF_REF_TYPE(Int32Ref, INT32_REF, "int32ref")
|
||||
HANDLE_TF_REF_TYPE(Uint64Ref, UINT64_REF, "uint64ref")
|
||||
HANDLE_TF_REF_TYPE(Int64Ref, INT64_REF, "int64ref")
|
||||
HANDLE_TF_REF_TYPE(StringRef, STRING_REF, "stringref")
|
||||
HANDLE_TF_REF_TYPE(BoolRef, BOOL_REF, "boolref")
|
||||
HANDLE_TF_REF_TYPE(Quint8Ref, QUINT8_REF, "quint8ref")
|
||||
HANDLE_TF_REF_TYPE(Qint8Ref, QINT8_REF, "qint8ref")
|
||||
HANDLE_TF_REF_TYPE(Quint16Ref, QUINT16_REF, "quint16ref")
|
||||
HANDLE_TF_REF_TYPE(Qint16Ref, QINT16_REF, "qint16ref")
|
||||
HANDLE_TF_REF_TYPE(Qint32Ref, QINT32_REF, "qint32ref")
|
||||
HANDLE_TF_REF_TYPE(Bfloat16Ref, BFLOAT16_REF, "bfloat16ref")
|
||||
HANDLE_TF_REF_TYPE(Complex64Ref, COMPLEX64_REF, "complex64ref")
|
||||
HANDLE_TF_REF_TYPE(Complex128Ref, COMPLEX128_REF, "complex128ref")
|
||||
HANDLE_TF_REF_TYPE(HalfRef, HALF_REF, "halfref")
|
||||
HANDLE_TF_REF_TYPE(ResourceRef, RESOURCE_REF, "resourceref")
|
||||
|
||||
#ifndef HANDLE_LAST_TF_TYPE
|
||||
#define HANDLE_LAST_TF_TYPE(class, enumerant, name) \
|
||||
HANDLE_TF_REF_TYPE(class, enumerant, name)
|
||||
#endif
|
||||
HANDLE_LAST_TF_TYPE(VariantRef, VARIANT_REF, "variantref")
|
||||
#undef HANDLE_LAST_TF_TYPE
|
||||
|
||||
#undef HANDLE_TF_REF_TYPE
|
||||
#undef HANDLE_TF_TYPE
|
||||
#endif
|
||||
380
3rdparty/ncnn/tools/mlir/tf_types.h
vendored
Normal file
380
3rdparty/ncnn/tools/mlir/tf_types.h
vendored
Normal file
@@ -0,0 +1,380 @@
|
||||
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
==============================================================================*/
|
||||
|
||||
// This file defines the types used in the standard MLIR TensorFlow dialect.
|
||||
|
||||
#ifndef TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_TYPES_H_
|
||||
#define TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_TYPES_H_
|
||||
|
||||
#include "mlir/IR/BuiltinTypes.h" // from @llvm-project
|
||||
#include "mlir/IR/Diagnostics.h" // from @llvm-project
|
||||
#include "mlir/IR/Location.h" // from @llvm-project
|
||||
#include "mlir/IR/Operation.h" // from @llvm-project
|
||||
#include "mlir/IR/TypeUtilities.h" // from @llvm-project
|
||||
#include "mlir/IR/Types.h" // from @llvm-project
|
||||
|
||||
namespace mlir {
|
||||
namespace TF {
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Utility iterators
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
// An iterator for the tensor shapes of an op's operands of shaped types.
|
||||
// Returns llvm::None if a operand is unranked; returns ArrayRef<int64_t> as the
|
||||
// shape otherwise.
|
||||
class OperandShapeIterator final
|
||||
: public llvm::mapped_iterator<Operation::operand_iterator,
|
||||
llvm::Optional<ArrayRef<int64_t> > (*)(
|
||||
Value)>
|
||||
{
|
||||
public:
|
||||
using reference = llvm::Optional<ArrayRef<int64_t> >;
|
||||
|
||||
/// Initializes the operand shape iterator to the specified operand iterator.
|
||||
explicit OperandShapeIterator(Operation::operand_iterator it);
|
||||
};
|
||||
|
||||
using OperandShapeRange = iterator_range<OperandShapeIterator>;
|
||||
|
||||
// An iterator for the tensor shapes of an op's results of shaped types.
|
||||
// Returns llvm::None if a result is unranked; returns ArrayRef<int64_t> as the
|
||||
// shape otherwise.
|
||||
class ResultShapeIterator final
|
||||
: public llvm::mapped_iterator<Operation::result_iterator,
|
||||
llvm::Optional<ArrayRef<int64_t> > (*)(
|
||||
Value)>
|
||||
{
|
||||
public:
|
||||
using reference = llvm::Optional<ArrayRef<int64_t> >;
|
||||
|
||||
/// Initializes the result shape iterator to the specified result iterator.
|
||||
explicit ResultShapeIterator(Operation::result_iterator it);
|
||||
};
|
||||
|
||||
using ResultShapeRange = iterator_range<ResultShapeIterator>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// TensorFlow types
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
// The base class in the TensorFlow type hierarchy.
|
||||
class TensorFlowType : public Type
|
||||
{
|
||||
public:
|
||||
using Type::Type;
|
||||
|
||||
// Support method to enable LLVM-style type casting.
|
||||
static bool classof(Type type);
|
||||
};
|
||||
|
||||
// Returns true if the specified type is a valid TensorFlow element type.
|
||||
static inline bool IsValidTFElementType(Type type)
|
||||
{
|
||||
return type.isa<ComplexType, FloatType, IntegerType, TensorFlowType>();
|
||||
}
|
||||
|
||||
// Returns true if this is a valid TensorFlow tensor type.
|
||||
static inline bool IsValidTFTensorType(Type type)
|
||||
{
|
||||
// TensorFlow types should be tensors of one of the valid TensorFlow element
|
||||
// types.
|
||||
if (auto tensor_ty = type.dyn_cast<TensorType>())
|
||||
return IsValidTFElementType(tensor_ty.getElementType());
|
||||
return false;
|
||||
}
|
||||
|
||||
namespace detail {
|
||||
// Common implementation of TensorFlow types. The template argument indicates
|
||||
// the concrete derived class per CRTP.
|
||||
template<typename Derived>
|
||||
class TensorFlowTypeImpl
|
||||
: public Type::TypeBase<Derived, TensorFlowType, TypeStorage>
|
||||
{
|
||||
public:
|
||||
using Base = typename Type::TypeBase<Derived, TensorFlowType, TypeStorage>;
|
||||
using TFBase = TensorFlowTypeImpl<Derived>;
|
||||
using Base::Base;
|
||||
};
|
||||
} // namespace detail
|
||||
|
||||
// TensorFlowRefType class supports all the ref types in TensorFlow dialect.
|
||||
class TensorFlowRefType : public TensorFlowType
|
||||
{
|
||||
public:
|
||||
using TensorFlowType::TensorFlowType;
|
||||
|
||||
// Checks if a type is TensorFlow Ref type.
|
||||
static bool classof(Type type);
|
||||
|
||||
// Converts a type to the corresponding TensorFlowRef type.
|
||||
static TensorFlowType get(Type type);
|
||||
static TensorFlowType getChecked(Type type, MLIRContext* context,
|
||||
Location loc)
|
||||
{
|
||||
if (failed(verify(loc, type)))
|
||||
{
|
||||
return TensorFlowRefType();
|
||||
}
|
||||
return get(type);
|
||||
}
|
||||
|
||||
static LogicalResult verify(Location loc, Type type)
|
||||
{
|
||||
// type should be a valid TensorFlow type.
|
||||
if (!IsValidTFTensorType(type))
|
||||
{
|
||||
return emitError(loc) << "invalid TensorFlow type: " << type;
|
||||
}
|
||||
return success();
|
||||
}
|
||||
|
||||
// Converts a TensorFlowRef type to the corresponding TensorFlow or standard
|
||||
// type.
|
||||
Type RemoveRef();
|
||||
};
|
||||
|
||||
// Returns the corresponding TensorFlow or standard type from TensorFlowRef
|
||||
// type.
|
||||
static inline Type GetDefaultTypeOf(TensorFlowRefType type)
|
||||
{
|
||||
return type.RemoveRef();
|
||||
}
|
||||
|
||||
// Returns the element type if `type` is a `ShapedType` and the type itself
|
||||
// otherwise, converting `TensorFlowRef` type to corresponding `TensorFlow` or
|
||||
// standard type if necessary.
|
||||
static inline Type GetElementTypeOrSelfResolveRef(Type type)
|
||||
{
|
||||
Type element_type = mlir::getElementTypeOrSelf(type);
|
||||
if (auto ref_type = element_type.dyn_cast<mlir::TF::TensorFlowRefType>())
|
||||
{
|
||||
element_type = ref_type.RemoveRef();
|
||||
}
|
||||
return element_type;
|
||||
}
|
||||
|
||||
#define HANDLE_TF_TYPE(tftype, enumerant, name) \
|
||||
class tftype##Type : public detail::TensorFlowTypeImpl<tftype##Type> \
|
||||
{ \
|
||||
public: \
|
||||
using TFBase::TFBase; \
|
||||
};
|
||||
|
||||
// Custom TensorFlow types are defined separately.
|
||||
#define HANDLE_CUSTOM_TF_TYPE(tftype, enumerant, name)
|
||||
|
||||
// NOLINTNEXTLINE
|
||||
#include "tf_types.def"
|
||||
|
||||
namespace detail {
|
||||
// Storage type contains inferred subtypes for TypeWithSubtype.
|
||||
class TypeWithSubtypeStorage : public TypeStorage
|
||||
{
|
||||
public:
|
||||
using KeyTy = ArrayRef<TensorType>;
|
||||
|
||||
// NOLINTNEXTLINE
|
||||
static TypeWithSubtypeStorage* construct(TypeStorageAllocator& allocator,
|
||||
const KeyTy& key)
|
||||
{
|
||||
ArrayRef<TensorType> subtypes = allocator.copyInto(key);
|
||||
return new (allocator.allocate<TypeWithSubtypeStorage>())
|
||||
TypeWithSubtypeStorage(subtypes);
|
||||
}
|
||||
|
||||
explicit TypeWithSubtypeStorage(const KeyTy& key)
|
||||
: subtypes_(key)
|
||||
{
|
||||
}
|
||||
|
||||
bool operator==(const KeyTy& key) const
|
||||
{
|
||||
return key == subtypes_;
|
||||
}
|
||||
|
||||
static llvm::hash_code hashKey(const KeyTy& key)
|
||||
{
|
||||
return llvm::hash_combine_range(key.begin(), key.end());
|
||||
}
|
||||
|
||||
KeyTy subtypes_;
|
||||
};
|
||||
|
||||
// Common implementation of TensorFlow types with subtypes. These subtypes are
|
||||
// opaque and their interpretation depends on the actual underlying type.
|
||||
// The template argument indicates the concrete derived class per CRTP. Concrete
|
||||
// classes must implement the following:
|
||||
// - `static std::string getTypeName()` that returns the name of the type for
|
||||
// verification logging.
|
||||
template<typename Derived>
|
||||
class TypeWithSubtypeImpl
|
||||
: public Type::TypeBase<Derived, TensorFlowType, TypeWithSubtypeStorage>
|
||||
{
|
||||
public:
|
||||
using Base = Type::TypeBase<Derived, TensorFlowType, TypeWithSubtypeStorage>;
|
||||
using TFBase = TypeWithSubtypeImpl<Derived>;
|
||||
using Base::Base;
|
||||
|
||||
static Derived get(ArrayRef<TensorType> subtypes, MLIRContext* context)
|
||||
{
|
||||
return Base::get(context, subtypes);
|
||||
}
|
||||
|
||||
static Derived getChecked(ArrayRef<TensorType> subtypes, MLIRContext* context,
|
||||
Location loc)
|
||||
{
|
||||
return Base::getChecked(loc, subtypes);
|
||||
}
|
||||
static Derived getChecked(function_ref<InFlightDiagnostic()> emitError,
|
||||
MLIRContext* context,
|
||||
ArrayRef<TensorType> subtypes)
|
||||
{
|
||||
return Base::getChecked(emitError, context, subtypes);
|
||||
}
|
||||
|
||||
static Derived get(MLIRContext* context)
|
||||
{
|
||||
return get({}, context);
|
||||
}
|
||||
|
||||
static LogicalResult verify(function_ref<InFlightDiagnostic()> emitError,
|
||||
ArrayRef<TensorType> subtypes)
|
||||
{
|
||||
// Each of the subtypes should be a valid TensorFlow type.
|
||||
for (TensorType subtype : subtypes)
|
||||
{
|
||||
if (!IsValidTFTensorType(subtype))
|
||||
{
|
||||
return emitError() << "invalid " << Derived::getTypeName()
|
||||
<< " subtype: " << subtype;
|
||||
}
|
||||
}
|
||||
return success();
|
||||
}
|
||||
|
||||
ArrayRef<TensorType> getSubtypes()
|
||||
{
|
||||
return Base::getImpl()->subtypes_;
|
||||
}
|
||||
};
|
||||
} // namespace detail
|
||||
|
||||
// TensorFlowTypeWithSubtype class supports all the types with subtypes in
|
||||
// TensorFlow dialect.
|
||||
class TensorFlowTypeWithSubtype : public TensorFlowType
|
||||
{
|
||||
public:
|
||||
using TensorFlowType::TensorFlowType;
|
||||
|
||||
// Checks if a type is TensorFlow type with subtypes.
|
||||
static bool classof(Type type);
|
||||
|
||||
// Converts a TypeWithSubtype type to the same type but without its subtypes.
|
||||
Type RemoveSubtypes();
|
||||
|
||||
// Returns the subtypes.
|
||||
ArrayRef<TensorType> GetSubtypes();
|
||||
};
|
||||
|
||||
// Returns the corresponding TensorFlow type with subtypes but without its
|
||||
// subtypes.
|
||||
static inline Type GetDefaultTypeOf(TensorFlowTypeWithSubtype type)
|
||||
{
|
||||
return type.RemoveSubtypes();
|
||||
}
|
||||
|
||||
// TensorFlow resource type is used to support TensorFlow resource variables,
|
||||
// which represent shared, persistent state manipulated by a TensorFlow program.
|
||||
// ResourceType stores shape and datatype for subtypes unlike most other data
|
||||
// types that don't have any associated information.
|
||||
class ResourceType : public detail::TypeWithSubtypeImpl<ResourceType>
|
||||
{
|
||||
public:
|
||||
using TFBase::TFBase;
|
||||
static std::string getTypeName()
|
||||
{
|
||||
return "ResourceType";
|
||||
}
|
||||
};
|
||||
|
||||
// TensorFlow variant type is used to support arbitrary custom C++ data types.
|
||||
// VariantType stores inferred shape and datatype for subtypes unlike most other
|
||||
// data types that don't have any associated information. For example, variants
|
||||
// encoding TensorList type stores the common shape and dtype of the list
|
||||
// elements as the only subtype.
|
||||
class VariantType : public detail::TypeWithSubtypeImpl<VariantType>
|
||||
{
|
||||
public:
|
||||
using TFBase::TFBase;
|
||||
static std::string getTypeName()
|
||||
{
|
||||
return "VariantType";
|
||||
}
|
||||
};
|
||||
|
||||
// Given two types `a` and `b`, returns a refined type which is cast compatible
|
||||
// with both `a` and `b` and is equal to or more precise than both of them. It
|
||||
// returns empty Type if the input types are not cast compatible.
|
||||
// Provides option to ignore ref types on 'a'. This is useful for TF ops that
|
||||
// might allow operands to either be same as result type or be a ref type
|
||||
// corresponding to it.
|
||||
mlir::Type GetCastCompatibleType(mlir::Type a, mlir::Type b,
|
||||
bool may_ignore_ref_type_a);
|
||||
|
||||
// Returns whether two arrays of Type are broadcast compatible.
|
||||
bool BroadcastCompatible(TypeRange lhs, TypeRange rhs);
|
||||
|
||||
// Returns whether the two elemental types are compatible. Shapes are compatible
|
||||
// if:
|
||||
// - the types are statically equal
|
||||
// - could be dynamically equal
|
||||
// - considering dynamic shapes equal unless contradictory info known;
|
||||
// - element types are equivalent, modulo subtypes possible be less exact
|
||||
// (e.g., a resource type without subtype is considered compatible with
|
||||
// resource type with known subtype).
|
||||
// Provide option to ignore ref types on 'lhs'.
|
||||
bool HasCompatibleElementTypes(Type lhs, Type rhs,
|
||||
bool may_ignore_ref_type_lhs = false);
|
||||
|
||||
// Returns true if all TensorFlow types can be cast to one
|
||||
// another. In other words, a single run-time value is legal for both the types.
|
||||
// For example, tensor<*xf32>, tensor<?xf32> and tensor<3xf32> are cast
|
||||
// compatible.
|
||||
bool AreCastCompatible(TypeRange types);
|
||||
|
||||
// Returns true if corresponding elements of lhs and rhs AreCastCompatible and
|
||||
// lhs and rhs are the same length.
|
||||
bool ArraysAreCastCompatible(TypeRange lhs, TypeRange rhs);
|
||||
|
||||
// If `ty` is a tensor type and its element type has subtypes, then returns a
|
||||
// new type of same shape but dropped subtypes for the element type.
|
||||
// Otherwise, if `ty` has subtypes, then returns corresponding type with dropped
|
||||
// subtypes.
|
||||
// Otherwise, returns the original type `ty`.
|
||||
Type DropSubTypes(Type ty);
|
||||
|
||||
// If `ty` is a tensor type and has elements of a ref type, then returns a new
|
||||
// type of same shape but corresponding non-ref type as element type.
|
||||
// Otherwise, if `ty` is a ref type, then returns corresponding non-ref type.
|
||||
// Otherwise, returns the original type `ty`.
|
||||
Type DropRefType(Type ty);
|
||||
|
||||
// Convenience call for executing both `DropRefType` and `DropSubTypes`.
|
||||
Type DropRefAndSubTypes(Type ty);
|
||||
|
||||
} // end namespace TF
|
||||
} // end namespace mlir
|
||||
|
||||
#endif // TENSORFLOW_COMPILER_MLIR_TENSORFLOW_IR_TF_TYPES_H_
|
||||
2216
3rdparty/ncnn/tools/modelwriter.h
vendored
Normal file
2216
3rdparty/ncnn/tools/modelwriter.h
vendored
Normal file
File diff suppressed because it is too large
Load Diff
6
3rdparty/ncnn/tools/mxnet/CMakeLists.txt
vendored
Normal file
6
3rdparty/ncnn/tools/mxnet/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
|
||||
add_executable(mxnet2ncnn mxnet2ncnn.cpp)
|
||||
|
||||
# add all mxnet2ncnn tool to a virtual project group
|
||||
set_property(TARGET mxnet2ncnn PROPERTY FOLDER "tools/converter")
|
||||
ncnn_install_tool(mxnet2ncnn)
|
||||
2783
3rdparty/ncnn/tools/mxnet/mxnet2ncnn.cpp
vendored
Normal file
2783
3rdparty/ncnn/tools/mxnet/mxnet2ncnn.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
491
3rdparty/ncnn/tools/ncnn2mem.cpp
vendored
Normal file
491
3rdparty/ncnn/tools/ncnn2mem.cpp
vendored
Normal file
@@ -0,0 +1,491 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2017 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "layer.h"
|
||||
#include "layer_type.h"
|
||||
|
||||
#include <cstddef>
|
||||
#include <ctype.h>
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
static std::vector<std::string> layer_names;
|
||||
static std::vector<std::string> blob_names;
|
||||
|
||||
static int find_blob_index_by_name(const char* name)
|
||||
{
|
||||
for (std::size_t i = 0; i < blob_names.size(); i++)
|
||||
{
|
||||
if (blob_names[i] == name)
|
||||
{
|
||||
return static_cast<int>(i);
|
||||
}
|
||||
}
|
||||
|
||||
fprintf(stderr, "find_blob_index_by_name %s failed\n", name);
|
||||
return -1;
|
||||
}
|
||||
|
||||
static void sanitize_name(char* name)
|
||||
{
|
||||
for (std::size_t i = 0; i < strlen(name); i++)
|
||||
{
|
||||
if (!isalnum(name[i]))
|
||||
{
|
||||
name[i] = '_';
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
static std::string path_to_varname(const char* path)
|
||||
{
|
||||
const char* lastslash = strrchr(path, '/');
|
||||
const char* name = lastslash == NULL ? path : lastslash + 1;
|
||||
|
||||
std::string varname = name;
|
||||
sanitize_name((char*)varname.c_str());
|
||||
|
||||
return varname;
|
||||
}
|
||||
|
||||
static bool vstr_is_float(const char vstr[16])
|
||||
{
|
||||
// look ahead for determine isfloat
|
||||
for (int j = 0; j < 16; j++)
|
||||
{
|
||||
if (vstr[j] == '\0')
|
||||
break;
|
||||
|
||||
if (vstr[j] == '.' || tolower(vstr[j]) == 'e')
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
static float vstr_to_float(const char vstr[16])
|
||||
{
|
||||
double v = 0.0;
|
||||
|
||||
const char* p = vstr;
|
||||
|
||||
// sign
|
||||
bool sign = *p != '-';
|
||||
if (*p == '+' || *p == '-')
|
||||
{
|
||||
p++;
|
||||
}
|
||||
|
||||
// digits before decimal point or exponent
|
||||
unsigned int v1 = 0;
|
||||
while (isdigit(*p))
|
||||
{
|
||||
v1 = v1 * 10 + (*p - '0');
|
||||
p++;
|
||||
}
|
||||
|
||||
v = (double)v1;
|
||||
|
||||
// digits after decimal point
|
||||
if (*p == '.')
|
||||
{
|
||||
p++;
|
||||
|
||||
unsigned int pow10 = 1;
|
||||
unsigned int v2 = 0;
|
||||
|
||||
while (isdigit(*p))
|
||||
{
|
||||
v2 = v2 * 10 + (*p - '0');
|
||||
pow10 *= 10;
|
||||
p++;
|
||||
}
|
||||
|
||||
v += v2 / (double)pow10;
|
||||
}
|
||||
|
||||
// exponent
|
||||
if (*p == 'e' || *p == 'E')
|
||||
{
|
||||
p++;
|
||||
|
||||
// sign of exponent
|
||||
bool fact = *p != '-';
|
||||
if (*p == '+' || *p == '-')
|
||||
{
|
||||
p++;
|
||||
}
|
||||
|
||||
// digits of exponent
|
||||
unsigned int expon = 0;
|
||||
while (isdigit(*p))
|
||||
{
|
||||
expon = expon * 10 + (*p - '0');
|
||||
p++;
|
||||
}
|
||||
|
||||
double scale = 1.0;
|
||||
while (expon >= 8)
|
||||
{
|
||||
scale *= 1e8;
|
||||
expon -= 8;
|
||||
}
|
||||
while (expon > 0)
|
||||
{
|
||||
scale *= 10.0;
|
||||
expon -= 1;
|
||||
}
|
||||
|
||||
v = fact ? v * scale : v / scale;
|
||||
}
|
||||
|
||||
// fprintf(stderr, "v = %f\n", v);
|
||||
return sign ? (float)v : (float)-v;
|
||||
}
|
||||
|
||||
static int dump_param(const char* parampath, const char* parambinpath, const char* idcpppath)
|
||||
{
|
||||
FILE* fp = fopen(parampath, "rb");
|
||||
|
||||
if (!fp)
|
||||
{
|
||||
fprintf(stderr, "fopen %s failed\n", parampath);
|
||||
return -1;
|
||||
}
|
||||
|
||||
FILE* mp = fopen(parambinpath, "wb");
|
||||
FILE* ip = fopen(idcpppath, "wb");
|
||||
|
||||
std::string param_var = path_to_varname(parampath);
|
||||
|
||||
std::string include_guard_var = path_to_varname(idcpppath);
|
||||
|
||||
fprintf(ip, "#ifndef NCNN_INCLUDE_GUARD_%s\n", include_guard_var.c_str());
|
||||
fprintf(ip, "#define NCNN_INCLUDE_GUARD_%s\n", include_guard_var.c_str());
|
||||
fprintf(ip, "namespace %s_id {\n", param_var.c_str());
|
||||
|
||||
int nscan = 0;
|
||||
int magic = 0;
|
||||
nscan = fscanf(fp, "%d", &magic);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read magic failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
fwrite(&magic, sizeof(int), 1, mp);
|
||||
|
||||
int layer_count = 0;
|
||||
int blob_count = 0;
|
||||
nscan = fscanf(fp, "%d %d", &layer_count, &blob_count);
|
||||
if (nscan != 2)
|
||||
{
|
||||
fprintf(stderr, "read layer_count and blob_count failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
fwrite(&layer_count, sizeof(int), 1, mp);
|
||||
fwrite(&blob_count, sizeof(int), 1, mp);
|
||||
|
||||
layer_names.resize(layer_count);
|
||||
blob_names.resize(blob_count);
|
||||
|
||||
std::vector<std::string> custom_layer_index;
|
||||
|
||||
int blob_index = 0;
|
||||
for (int i = 0; i < layer_count; i++)
|
||||
{
|
||||
char layer_type[33];
|
||||
char layer_name[257];
|
||||
int bottom_count = 0;
|
||||
int top_count = 0;
|
||||
nscan = fscanf(fp, "%32s %256s %d %d", layer_type, layer_name, &bottom_count, &top_count);
|
||||
if (nscan != 4)
|
||||
{
|
||||
fprintf(stderr, "read layer params failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
sanitize_name(layer_name);
|
||||
|
||||
int typeindex = ncnn::layer_to_index(layer_type);
|
||||
if (typeindex == -1)
|
||||
{
|
||||
// lookup custom_layer_index
|
||||
for (size_t j = 0; j < custom_layer_index.size(); j++)
|
||||
{
|
||||
if (custom_layer_index[j] == layer_type)
|
||||
{
|
||||
typeindex = ncnn::LayerType::CustomBit | j;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (typeindex == -1)
|
||||
{
|
||||
// new custom layer type
|
||||
size_t j = custom_layer_index.size();
|
||||
custom_layer_index.push_back(layer_type);
|
||||
typeindex = ncnn::LayerType::CustomBit | j;
|
||||
}
|
||||
}
|
||||
fwrite(&typeindex, sizeof(int), 1, mp);
|
||||
|
||||
fwrite(&bottom_count, sizeof(int), 1, mp);
|
||||
fwrite(&top_count, sizeof(int), 1, mp);
|
||||
|
||||
fprintf(ip, "const int LAYER_%s = %d;\n", layer_name, i);
|
||||
|
||||
// layer->bottoms.resize(bottom_count);
|
||||
for (int j = 0; j < bottom_count; j++)
|
||||
{
|
||||
char bottom_name[257];
|
||||
nscan = fscanf(fp, "%256s", bottom_name);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read bottom_name failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
sanitize_name(bottom_name);
|
||||
|
||||
int bottom_blob_index = find_blob_index_by_name(bottom_name);
|
||||
|
||||
fwrite(&bottom_blob_index, sizeof(int), 1, mp);
|
||||
}
|
||||
|
||||
// layer->tops.resize(top_count);
|
||||
for (int j = 0; j < top_count; j++)
|
||||
{
|
||||
char blob_name[257];
|
||||
nscan = fscanf(fp, "%256s", blob_name);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read blob_name failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
sanitize_name(blob_name);
|
||||
|
||||
blob_names[blob_index] = std::string(blob_name);
|
||||
|
||||
fprintf(ip, "const int BLOB_%s = %d;\n", blob_name, blob_index);
|
||||
|
||||
fwrite(&blob_index, sizeof(int), 1, mp);
|
||||
|
||||
blob_index++;
|
||||
}
|
||||
|
||||
// dump layer specific params
|
||||
// parse each key=value pair
|
||||
int id = 0;
|
||||
while (fscanf(fp, "%d=", &id) == 1)
|
||||
{
|
||||
fwrite(&id, sizeof(int), 1, mp);
|
||||
|
||||
bool is_array = id <= -23300;
|
||||
|
||||
if (is_array)
|
||||
{
|
||||
int len = 0;
|
||||
nscan = fscanf(fp, "%d", &len);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read array length failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
fwrite(&len, sizeof(int), 1, mp);
|
||||
|
||||
for (int j = 0; j < len; j++)
|
||||
{
|
||||
char vstr[16];
|
||||
nscan = fscanf(fp, ",%15[^,\n ]", vstr);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read array element failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
bool is_float = vstr_is_float(vstr);
|
||||
|
||||
if (is_float)
|
||||
{
|
||||
float vf = vstr_to_float(vstr);
|
||||
fwrite(&vf, sizeof(float), 1, mp);
|
||||
}
|
||||
else
|
||||
{
|
||||
int v;
|
||||
sscanf(vstr, "%d", &v);
|
||||
fwrite(&v, sizeof(int), 1, mp);
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
char vstr[16];
|
||||
nscan = fscanf(fp, "%15s", vstr);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read value failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
bool is_float = vstr_is_float(vstr);
|
||||
|
||||
if (is_float)
|
||||
{
|
||||
float vf = vstr_to_float(vstr);
|
||||
fwrite(&vf, sizeof(float), 1, mp);
|
||||
}
|
||||
else
|
||||
{
|
||||
int v;
|
||||
sscanf(vstr, "%d", &v);
|
||||
fwrite(&v, sizeof(int), 1, mp);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
int EOP = -233;
|
||||
fwrite(&EOP, sizeof(int), 1, mp);
|
||||
|
||||
layer_names[i] = std::string(layer_name);
|
||||
}
|
||||
|
||||
// dump custom layer index
|
||||
for (size_t j = 0; j < custom_layer_index.size(); j++)
|
||||
{
|
||||
const std::string& layer_type = custom_layer_index[j];
|
||||
int typeindex = ncnn::LayerType::CustomBit | j;
|
||||
|
||||
fprintf(ip, "const int TYPEINDEX_%s = %d;\n", layer_type.c_str(), typeindex);
|
||||
|
||||
fprintf(stderr, "net.register_custom_layer(%s_id::TYPEINDEX_%s, %s_layer_creator);\n", param_var.c_str(), layer_type.c_str(), layer_type.c_str());
|
||||
}
|
||||
|
||||
fprintf(ip, "} // namespace %s_id\n", param_var.c_str());
|
||||
fprintf(ip, "#endif // NCNN_INCLUDE_GUARD_%s\n", include_guard_var.c_str());
|
||||
|
||||
fclose(fp);
|
||||
|
||||
fclose(mp);
|
||||
fclose(ip);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
static int write_memcpp(const char* parambinpath, const char* modelpath, const char* memcpppath)
|
||||
{
|
||||
FILE* cppfp = fopen(memcpppath, "wb");
|
||||
|
||||
// dump param
|
||||
std::string param_var = path_to_varname(parambinpath);
|
||||
|
||||
std::string include_guard_var = path_to_varname(memcpppath);
|
||||
|
||||
FILE* mp = fopen(parambinpath, "rb");
|
||||
|
||||
if (!mp)
|
||||
{
|
||||
fprintf(stderr, "fopen %s failed\n", parambinpath);
|
||||
return -1;
|
||||
}
|
||||
|
||||
fprintf(cppfp, "#ifndef NCNN_INCLUDE_GUARD_%s\n", include_guard_var.c_str());
|
||||
fprintf(cppfp, "#define NCNN_INCLUDE_GUARD_%s\n", include_guard_var.c_str());
|
||||
|
||||
fprintf(cppfp, "\n#ifdef _MSC_VER\n__declspec(align(4))\n#else\n__attribute__((aligned(4)))\n#endif\n");
|
||||
fprintf(cppfp, "static const unsigned char %s[] = {\n", param_var.c_str());
|
||||
|
||||
int i = 0;
|
||||
while (!feof(mp))
|
||||
{
|
||||
int c = fgetc(mp);
|
||||
if (c == EOF)
|
||||
break;
|
||||
fprintf(cppfp, "0x%02x,", c);
|
||||
|
||||
i++;
|
||||
if (i % 16 == 0)
|
||||
{
|
||||
fprintf(cppfp, "\n");
|
||||
}
|
||||
}
|
||||
|
||||
fprintf(cppfp, "};\n");
|
||||
|
||||
fclose(mp);
|
||||
|
||||
// dump model
|
||||
std::string model_var = path_to_varname(modelpath);
|
||||
|
||||
FILE* bp = fopen(modelpath, "rb");
|
||||
|
||||
if (!bp)
|
||||
{
|
||||
fprintf(stderr, "fopen %s failed\n", modelpath);
|
||||
return -1;
|
||||
}
|
||||
|
||||
fprintf(cppfp, "\n#ifdef _MSC_VER\n__declspec(align(4))\n#else\n__attribute__((aligned(4)))\n#endif\n");
|
||||
fprintf(cppfp, "static const unsigned char %s[] = {\n", model_var.c_str());
|
||||
|
||||
i = 0;
|
||||
while (!feof(bp))
|
||||
{
|
||||
int c = fgetc(bp);
|
||||
if (c == EOF)
|
||||
break;
|
||||
fprintf(cppfp, "0x%02x,", c);
|
||||
|
||||
i++;
|
||||
if (i % 16 == 0)
|
||||
{
|
||||
fprintf(cppfp, "\n");
|
||||
}
|
||||
}
|
||||
|
||||
fprintf(cppfp, "};\n");
|
||||
|
||||
fprintf(cppfp, "#endif // NCNN_INCLUDE_GUARD_%s\n", include_guard_var.c_str());
|
||||
|
||||
fclose(bp);
|
||||
|
||||
fclose(cppfp);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
if (argc != 5)
|
||||
{
|
||||
fprintf(stderr, "Usage: %s [ncnnproto] [ncnnbin] [idcpppath] [memcpppath]\n", argv[0]);
|
||||
return -1;
|
||||
}
|
||||
|
||||
const char* parampath = argv[1];
|
||||
const char* modelpath = argv[2];
|
||||
const char* idcpppath = argv[3];
|
||||
const char* memcpppath = argv[4];
|
||||
|
||||
std::string parambinpath = std::string(parampath) + ".bin";
|
||||
|
||||
dump_param(parampath, parambinpath.c_str(), idcpppath);
|
||||
|
||||
write_memcpp(parambinpath.c_str(), modelpath, memcpppath);
|
||||
|
||||
return 0;
|
||||
}
|
||||
196
3rdparty/ncnn/tools/ncnnmerge.cpp
vendored
Normal file
196
3rdparty/ncnn/tools/ncnnmerge.cpp
vendored
Normal file
@@ -0,0 +1,196 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <string>
|
||||
|
||||
static int copy_param(const char* parampath, FILE* outparamfp, int* total_layer_count, int* total_blob_count)
|
||||
{
|
||||
// resolve model namespace from XYZ.param
|
||||
const char* lastslash = strrchr(parampath, '/');
|
||||
const char* name = lastslash == NULL ? parampath : lastslash + 1;
|
||||
const char* dot = strrchr(name, '.');
|
||||
std::string ns = dot ? std::string(name).substr(0, dot - name) : std::string(name);
|
||||
|
||||
FILE* fp = fopen(parampath, "rb");
|
||||
|
||||
if (!fp)
|
||||
{
|
||||
fprintf(stderr, "fopen %s failed\n", parampath);
|
||||
return -1;
|
||||
}
|
||||
|
||||
int nscan = 0;
|
||||
int magic = 0;
|
||||
nscan = fscanf(fp, "%d", &magic);
|
||||
if (nscan != 1 || magic != 7767517)
|
||||
{
|
||||
fprintf(stderr, "read magic failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
int layer_count = 0;
|
||||
int blob_count = 0;
|
||||
nscan = fscanf(fp, "%d %d", &layer_count, &blob_count);
|
||||
if (nscan != 2)
|
||||
{
|
||||
fprintf(stderr, "read layer_count and blob_count failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
*total_layer_count += layer_count;
|
||||
*total_blob_count += blob_count;
|
||||
|
||||
char line[1024];
|
||||
for (int i = 0; i < layer_count; i++)
|
||||
{
|
||||
char layer_type[33];
|
||||
char layer_name[257];
|
||||
int bottom_count = 0;
|
||||
int top_count = 0;
|
||||
nscan = fscanf(fp, "%32s %256s %d %d", layer_type, layer_name, &bottom_count, &top_count);
|
||||
if (nscan != 4)
|
||||
{
|
||||
fprintf(stderr, "read layer params failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
fprintf(outparamfp, "%-24s %s/%-24s %d %d", layer_type, ns.c_str(), layer_name, bottom_count, top_count);
|
||||
|
||||
for (int j = 0; j < bottom_count; j++)
|
||||
{
|
||||
char bottom_name[257];
|
||||
nscan = fscanf(fp, "%256s", bottom_name);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read bottom_name failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
fprintf(outparamfp, " %s/%s", ns.c_str(), bottom_name);
|
||||
}
|
||||
|
||||
for (int j = 0; j < top_count; j++)
|
||||
{
|
||||
char top_name[257];
|
||||
nscan = fscanf(fp, "%256s", top_name);
|
||||
if (nscan != 1)
|
||||
{
|
||||
fprintf(stderr, "read top_name failed %d\n", nscan);
|
||||
return -1;
|
||||
}
|
||||
|
||||
fprintf(outparamfp, " %s/%s", ns.c_str(), top_name);
|
||||
}
|
||||
|
||||
// copy param dict string
|
||||
char* s = fgets(line, 1024, fp);
|
||||
if (!s)
|
||||
{
|
||||
fprintf(stderr, "read line %s failed\n", parampath);
|
||||
break;
|
||||
}
|
||||
|
||||
fputs(line, outparamfp);
|
||||
}
|
||||
|
||||
fclose(fp);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
static int copy_bin(const char* binpath, FILE* outbinfp)
|
||||
{
|
||||
FILE* fp = fopen(binpath, "rb");
|
||||
|
||||
if (!fp)
|
||||
{
|
||||
fprintf(stderr, "fopen %s failed\n", binpath);
|
||||
return -1;
|
||||
}
|
||||
|
||||
fseek(fp, 0, SEEK_END);
|
||||
int len = (int)ftell(fp);
|
||||
rewind(fp);
|
||||
|
||||
char buffer[4096];
|
||||
int i = 0;
|
||||
for (; i + 4095 < len;)
|
||||
{
|
||||
size_t nread = fread(buffer, 1, 4096, fp);
|
||||
size_t nwrite = fwrite(buffer, 1, nread, outbinfp);
|
||||
i += (int)nwrite;
|
||||
}
|
||||
{
|
||||
size_t nread = fread(buffer, 1, len - i, fp);
|
||||
size_t nwrite = fwrite(buffer, 1, nread, outbinfp);
|
||||
i += (int)nwrite;
|
||||
}
|
||||
|
||||
if (i != len)
|
||||
{
|
||||
fprintf(stderr, "copy %s incomplete\n", binpath);
|
||||
}
|
||||
|
||||
fclose(fp);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
if (argc < 7 || (argc - 1) % 2 != 0)
|
||||
{
|
||||
fprintf(stderr, "Usage: %s [param1] [bin1] [param2] [bin2] ... [outparam] [outbin]\n", argv[0]);
|
||||
return -1;
|
||||
}
|
||||
|
||||
const char* outparampath = argv[argc - 2];
|
||||
const char* outbinpath = argv[argc - 1];
|
||||
|
||||
FILE* outparamfp = fopen(outparampath, "wb");
|
||||
FILE* outbinfp = fopen(outbinpath, "wb");
|
||||
|
||||
// magic
|
||||
fprintf(outparamfp, "7767517\n");
|
||||
|
||||
// layer count and blob count placeholder
|
||||
// 99999 is large enough I think --- nihui
|
||||
fprintf(outparamfp, " \n");
|
||||
|
||||
int total_layer_count = 0;
|
||||
int total_blob_count = 0;
|
||||
|
||||
const int model_count = (argc - 3) / 2;
|
||||
|
||||
for (int i = 0; i < model_count; i++)
|
||||
{
|
||||
const char* parampath = argv[i * 2 + 1];
|
||||
const char* binpath = argv[i * 2 + 2];
|
||||
|
||||
copy_param(parampath, outparamfp, &total_layer_count, &total_blob_count);
|
||||
copy_bin(binpath, outbinfp);
|
||||
}
|
||||
|
||||
// the real layer count and blob count
|
||||
rewind(outparamfp);
|
||||
fprintf(outparamfp, "7767517\n");
|
||||
fprintf(outparamfp, "%d %d", total_layer_count, total_blob_count);
|
||||
|
||||
fclose(outparamfp);
|
||||
fclose(outbinfp);
|
||||
|
||||
return 0;
|
||||
}
|
||||
2856
3rdparty/ncnn/tools/ncnnoptimize.cpp
vendored
Normal file
2856
3rdparty/ncnn/tools/ncnnoptimize.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
18
3rdparty/ncnn/tools/onnx/CMakeLists.txt
vendored
Normal file
18
3rdparty/ncnn/tools/onnx/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,18 @@
|
||||
|
||||
find_package(Protobuf)
|
||||
|
||||
if(PROTOBUF_FOUND)
|
||||
protobuf_generate_cpp(ONNX_PROTO_SRCS ONNX_PROTO_HDRS onnx.proto)
|
||||
add_executable(onnx2ncnn onnx2ncnn.cpp ${ONNX_PROTO_SRCS} ${ONNX_PROTO_HDRS})
|
||||
target_include_directories(onnx2ncnn
|
||||
PRIVATE
|
||||
${PROTOBUF_INCLUDE_DIR}
|
||||
${CMAKE_CURRENT_BINARY_DIR})
|
||||
target_link_libraries(onnx2ncnn PRIVATE ${PROTOBUF_LIBRARIES})
|
||||
|
||||
# add all onnx2ncnn tool to a virtual project group
|
||||
set_property(TARGET onnx2ncnn PROPERTY FOLDER "tools/converter")
|
||||
ncnn_install_tool(onnx2ncnn)
|
||||
else()
|
||||
message(WARNING "Protobuf not found, onnx model convert tool won't be built")
|
||||
endif()
|
||||
505
3rdparty/ncnn/tools/onnx/onnx.proto
vendored
Normal file
505
3rdparty/ncnn/tools/onnx/onnx.proto
vendored
Normal file
@@ -0,0 +1,505 @@
|
||||
//
|
||||
// WARNING: This file is automatically generated! Please edit onnx.in.proto.
|
||||
//
|
||||
|
||||
|
||||
// Copyright (c) ONNX Project Contributors.
|
||||
// Licensed under the MIT license.
|
||||
|
||||
syntax = "proto2";
|
||||
|
||||
package onnx;
|
||||
|
||||
// Overview
|
||||
//
|
||||
// ONNX is an open specification that is comprised of the following components:
|
||||
//
|
||||
// 1) A definition of an extensible computation graph model.
|
||||
// 2) Definitions of standard data types.
|
||||
// 3) Definitions of built-in operators.
|
||||
//
|
||||
// This document describes the syntax of models and their computation graphs,
|
||||
// as well as the standard data types. Together, they are referred to as the ONNX
|
||||
// Intermediate Representation, or 'IR' for short.
|
||||
//
|
||||
// The normative semantic specification of the ONNX IR is found in docs/IR.md.
|
||||
// Definitions of the built-in neural network operators may be found in docs/Operators.md.
|
||||
|
||||
// Notes
|
||||
//
|
||||
// Release
|
||||
//
|
||||
// We are still in the very early stage of defining ONNX. The current
|
||||
// version of ONNX is a starting point. While we are actively working
|
||||
// towards a complete spec, we would like to get the community involved
|
||||
// by sharing our working version of ONNX.
|
||||
//
|
||||
// Protobuf compatibility
|
||||
//
|
||||
// To simplify framework compatibility, ONNX is defined using the subset of protobuf
|
||||
// that is compatible with both protobuf v2 and v3. This means that we do not use any
|
||||
// protobuf features that are only available in one of the two versions.
|
||||
//
|
||||
// Here are the most notable contortions we have to carry out to work around
|
||||
// these limitations:
|
||||
//
|
||||
// - No 'map' (added protobuf 3.0). We instead represent mappings as lists
|
||||
// of key-value pairs, where order does not matter and duplicates
|
||||
// are not allowed.
|
||||
|
||||
|
||||
// Versioning
|
||||
//
|
||||
// ONNX versioning is specified in docs/IR.md and elaborated on in docs/Versioning.md
|
||||
//
|
||||
// To be compatible with both proto2 and proto3, we will use a version number
|
||||
// that is not defined by the default value but an explicit enum number.
|
||||
enum Version {
|
||||
// proto3 requires the first enum value to be zero.
|
||||
// We add this just to appease the compiler.
|
||||
_START_VERSION = 0;
|
||||
// The version field is always serialized and we will use it to store the
|
||||
// version that the graph is generated from. This helps us set up version
|
||||
// control.
|
||||
// For the IR, we are using simple numbers starting with with 0x00000001,
|
||||
// which was the version we published on Oct 10, 2017.
|
||||
IR_VERSION_2017_10_10 = 0x0000000000000001;
|
||||
|
||||
// IR_VERSION 2 published on Oct 30, 2017
|
||||
// - Added type discriminator to AttributeProto to support proto3 users
|
||||
IR_VERSION_2017_10_30 = 0x0000000000000002;
|
||||
|
||||
// IR VERSION 3 published on Nov 3, 2017
|
||||
// - For operator versioning:
|
||||
// - Added new message OperatorSetIdProto
|
||||
// - Added opset_import in ModelProto
|
||||
// - For vendor extensions, added domain in NodeProto
|
||||
IR_VERSION_2017_11_3 = 0x0000000000000003;
|
||||
|
||||
// IR VERSION 4 published on Jan 22, 2019
|
||||
// - Relax constraint that initializers should be a subset of graph inputs
|
||||
// - Add type BFLOAT16
|
||||
IR_VERSION_2019_1_22 = 0x0000000000000004;
|
||||
|
||||
// IR VERSION 5 published on March 18, 2019
|
||||
// - Add message TensorAnnotation.
|
||||
// - Add quantization annotation in GraphProto to map tensor with its scale and zero point quantization parameters.
|
||||
IR_VERSION = 0x0000000000000005;
|
||||
}
|
||||
|
||||
// Attributes
|
||||
//
|
||||
// A named attribute containing either singular float, integer, string, graph,
|
||||
// and tensor values, or repeated float, integer, string, graph, and tensor values.
|
||||
// An AttributeProto MUST contain the name field, and *only one* of the
|
||||
// following content fields, effectively enforcing a C/C++ union equivalent.
|
||||
message AttributeProto {
|
||||
|
||||
// Note: this enum is structurally identical to the OpSchema::AttrType
|
||||
// enum defined in schema.h. If you rev one, you likely need to rev the other.
|
||||
enum AttributeType {
|
||||
UNDEFINED = 0;
|
||||
FLOAT = 1;
|
||||
INT = 2;
|
||||
STRING = 3;
|
||||
TENSOR = 4;
|
||||
GRAPH = 5;
|
||||
|
||||
FLOATS = 6;
|
||||
INTS = 7;
|
||||
STRINGS = 8;
|
||||
TENSORS = 9;
|
||||
GRAPHS = 10;
|
||||
}
|
||||
|
||||
// The name field MUST be present for this version of the IR.
|
||||
optional string name = 1; // namespace Attribute
|
||||
|
||||
// if ref_attr_name is not empty, ref_attr_name is the attribute name in parent function.
|
||||
// In this case, this AttributeProto does not contain data, and it's a reference of attribute
|
||||
// in parent scope.
|
||||
// NOTE: This should ONLY be used in function (sub-graph). It's invalid to be used in main graph.
|
||||
optional string ref_attr_name = 21;
|
||||
|
||||
// A human-readable documentation for this attribute. Markdown is allowed.
|
||||
optional string doc_string = 13;
|
||||
|
||||
// The type field MUST be present for this version of the IR.
|
||||
// For 0.0.1 versions of the IR, this field was not defined, and
|
||||
// implementations needed to use has_field hueristics to determine
|
||||
// which value field was in use. For IR_VERSION 0.0.2 or later, this
|
||||
// field MUST be set and match the f|i|s|t|... field in use. This
|
||||
// change was made to accommodate proto3 implementations.
|
||||
optional AttributeType type = 20; // discriminator that indicates which field below is in use
|
||||
|
||||
// Exactly ONE of the following fields must be present for this version of the IR
|
||||
optional float f = 2; // float
|
||||
optional int64 i = 3; // int
|
||||
optional bytes s = 4; // UTF-8 string
|
||||
optional TensorProto t = 5; // tensor value
|
||||
optional GraphProto g = 6; // graph
|
||||
// Do not use field below, it's deprecated.
|
||||
// optional ValueProto v = 12; // value - subsumes everything but graph
|
||||
|
||||
repeated float floats = 7; // list of floats
|
||||
repeated int64 ints = 8; // list of ints
|
||||
repeated bytes strings = 9; // list of UTF-8 strings
|
||||
repeated TensorProto tensors = 10; // list of tensors
|
||||
repeated GraphProto graphs = 11; // list of graph
|
||||
}
|
||||
|
||||
// Defines information on value, including the name, the type, and
|
||||
// the shape of the value.
|
||||
message ValueInfoProto {
|
||||
// This field MUST be present in this version of the IR.
|
||||
optional string name = 1; // namespace Value
|
||||
// This field MUST be present in this version of the IR.
|
||||
optional TypeProto type = 2;
|
||||
// A human-readable documentation for this value. Markdown is allowed.
|
||||
optional string doc_string = 3;
|
||||
}
|
||||
|
||||
// Nodes
|
||||
//
|
||||
// Computation graphs are made up of a DAG of nodes, which represent what is
|
||||
// commonly called a "layer" or "pipeline stage" in machine learning frameworks.
|
||||
//
|
||||
// For example, it can be a node of type "Conv" that takes in an image, a filter
|
||||
// tensor and a bias tensor, and produces the convolved output.
|
||||
message NodeProto {
|
||||
repeated string input = 1; // namespace Value
|
||||
repeated string output = 2; // namespace Value
|
||||
|
||||
// An optional identifier for this node in a graph.
|
||||
// This field MAY be absent in ths version of the IR.
|
||||
optional string name = 3; // namespace Node
|
||||
|
||||
// The symbolic identifier of the Operator to execute.
|
||||
optional string op_type = 4; // namespace Operator
|
||||
// The domain of the OperatorSet that specifies the operator named by op_type.
|
||||
optional string domain = 7; // namespace Domain
|
||||
|
||||
// Additional named attributes.
|
||||
repeated AttributeProto attribute = 5;
|
||||
|
||||
// A human-readable documentation for this node. Markdown is allowed.
|
||||
optional string doc_string = 6;
|
||||
}
|
||||
|
||||
// Models
|
||||
//
|
||||
// ModelProto is a top-level file/container format for bundling a ML model and
|
||||
// associating its computation graph with metadata.
|
||||
//
|
||||
// The semantics of the model are described by the associated GraphProto.
|
||||
message ModelProto {
|
||||
// The version of the IR this model targets. See Version enum above.
|
||||
// This field MUST be present.
|
||||
optional int64 ir_version = 1;
|
||||
|
||||
// The OperatorSets this model relies on.
|
||||
// All ModelProtos MUST have at least one entry that
|
||||
// specifies which version of the ONNX OperatorSet is
|
||||
// being imported.
|
||||
//
|
||||
// All nodes in the ModelProto's graph will bind against the operator
|
||||
// with the same-domain/same-op_type operator with the HIGHEST version
|
||||
// in the referenced operator sets.
|
||||
repeated OperatorSetIdProto opset_import = 8;
|
||||
|
||||
// The name of the framework or tool used to generate this model.
|
||||
// This field SHOULD be present to indicate which implementation/tool/framework
|
||||
// emitted the model.
|
||||
optional string producer_name = 2;
|
||||
|
||||
// The version of the framework or tool used to generate this model.
|
||||
// This field SHOULD be present to indicate which implementation/tool/framework
|
||||
// emitted the model.
|
||||
optional string producer_version = 3;
|
||||
|
||||
// Domain name of the model.
|
||||
// We use reverse domain names as name space indicators. For example:
|
||||
// `com.facebook.fair` or `com.microsoft.cognitiveservices`
|
||||
//
|
||||
// Together with `model_version` and GraphProto.name, this forms the unique identity of
|
||||
// the graph.
|
||||
optional string domain = 4;
|
||||
|
||||
// The version of the graph encoded. See Version enum below.
|
||||
optional int64 model_version = 5;
|
||||
|
||||
// A human-readable documentation for this model. Markdown is allowed.
|
||||
optional string doc_string = 6;
|
||||
|
||||
// The parameterized graph that is evaluated to execute the model.
|
||||
optional GraphProto graph = 7;
|
||||
|
||||
// Named metadata values; keys should be distinct.
|
||||
repeated StringStringEntryProto metadata_props = 14;
|
||||
};
|
||||
|
||||
// StringStringEntryProto follows the pattern for cross-proto-version maps.
|
||||
// See https://developers.google.com/protocol-buffers/docs/proto3#maps
|
||||
message StringStringEntryProto {
|
||||
optional string key = 1;
|
||||
optional string value= 2;
|
||||
};
|
||||
|
||||
message TensorAnnotation {
|
||||
optional string tensor_name = 1;
|
||||
// <key, value> pairs to annotate tensor specified by <tensor_name> above.
|
||||
// The keys used in the mapping below must be pre-defined in ONNX spec.
|
||||
// For example, for 8-bit linear quantization case, 'SCALE_TENSOR', 'ZERO_POINT_TENSOR' will be pre-defined as
|
||||
// quantization parameter keys.
|
||||
repeated StringStringEntryProto quant_parameter_tensor_names = 2;
|
||||
}
|
||||
|
||||
|
||||
|
||||
// Graphs
|
||||
//
|
||||
// A graph defines the computational logic of a model and is comprised of a parameterized
|
||||
// list of nodes that form a directed acyclic graph based on their inputs and outputs.
|
||||
// This is the equivalent of the "network" or "graph" in many deep learning
|
||||
// frameworks.
|
||||
message GraphProto {
|
||||
// The nodes in the graph, sorted topologically.
|
||||
repeated NodeProto node = 1;
|
||||
|
||||
// The name of the graph.
|
||||
optional string name = 2; // namespace Graph
|
||||
|
||||
// A list of named tensor values, used to specify constant inputs of the graph.
|
||||
// Each TensorProto entry must have a distinct name (within the list) that
|
||||
// MAY also appear in the input list.
|
||||
repeated TensorProto initializer = 5;
|
||||
|
||||
// A human-readable documentation for this graph. Markdown is allowed.
|
||||
optional string doc_string = 10;
|
||||
|
||||
// The inputs and outputs of the graph.
|
||||
repeated ValueInfoProto input = 11;
|
||||
repeated ValueInfoProto output = 12;
|
||||
|
||||
// Information for the values in the graph. The ValueInfoProto.name's
|
||||
// must be distinct. It is optional for a value to appear in value_info list.
|
||||
repeated ValueInfoProto value_info = 13;
|
||||
|
||||
// This field carries information to indicate the mapping among a tensor and its
|
||||
// quantization parameter tensors. For example:
|
||||
// For tensor 'a', it may have {'SCALE_TENSOR', 'a_scale'} and {'ZERO_POINT_TENSOR', 'a_zero_point'} annotated,
|
||||
// which means, tensor 'a_scale' and tensor 'a_zero_point' are scale and zero point of tensor 'a' in the model.
|
||||
repeated TensorAnnotation quantization_annotation = 14;
|
||||
|
||||
// DO NOT USE the following fields, they were deprecated from earlier versions.
|
||||
// repeated string input = 3;
|
||||
// repeated string output = 4;
|
||||
// optional int64 ir_version = 6;
|
||||
// optional int64 producer_version = 7;
|
||||
// optional string producer_tag = 8;
|
||||
// optional string domain = 9;
|
||||
}
|
||||
|
||||
// Tensors
|
||||
//
|
||||
// A serialized tensor value.
|
||||
message TensorProto {
|
||||
enum DataType {
|
||||
UNDEFINED = 0;
|
||||
// Basic types.
|
||||
FLOAT = 1; // float
|
||||
UINT8 = 2; // uint8_t
|
||||
INT8 = 3; // int8_t
|
||||
UINT16 = 4; // uint16_t
|
||||
INT16 = 5; // int16_t
|
||||
INT32 = 6; // int32_t
|
||||
INT64 = 7; // int64_t
|
||||
STRING = 8; // string
|
||||
BOOL = 9; // bool
|
||||
|
||||
// IEEE754 half-precision floating-point format (16 bits wide).
|
||||
// This format has 1 sign bit, 5 exponent bits, and 10 mantissa bits.
|
||||
FLOAT16 = 10;
|
||||
|
||||
DOUBLE = 11;
|
||||
UINT32 = 12;
|
||||
UINT64 = 13;
|
||||
COMPLEX64 = 14; // complex with float32 real and imaginary components
|
||||
COMPLEX128 = 15; // complex with float64 real and imaginary components
|
||||
|
||||
// Non-IEEE floating-point format based on IEEE754 single-precision
|
||||
// floating-point number truncated to 16 bits.
|
||||
// This format has 1 sign bit, 8 exponent bits, and 7 mantissa bits.
|
||||
BFLOAT16 = 16;
|
||||
|
||||
// Future extensions go here.
|
||||
}
|
||||
|
||||
// The shape of the tensor.
|
||||
repeated int64 dims = 1;
|
||||
|
||||
// The data type of the tensor.
|
||||
// This field MUST have a valid TensorProto.DataType value
|
||||
optional int32 data_type = 2;
|
||||
|
||||
// For very large tensors, we may want to store them in chunks, in which
|
||||
// case the following fields will specify the segment that is stored in
|
||||
// the current TensorProto.
|
||||
message Segment {
|
||||
optional int64 begin = 1;
|
||||
optional int64 end = 2;
|
||||
}
|
||||
optional Segment segment = 3;
|
||||
|
||||
// Tensor content must be organized in row-major order.
|
||||
//
|
||||
// Depending on the data_type field, exactly one of the fields below with
|
||||
// name ending in _data is used to store the elements of the tensor.
|
||||
|
||||
// For float and complex64 values
|
||||
// Complex64 tensors are encoded as a single array of floats,
|
||||
// with the real components appearing in odd numbered positions,
|
||||
// and the corresponding imaginary component apparing in the
|
||||
// subsequent even numbered position. (e.g., [1.0 + 2.0i, 3.0 + 4.0i]
|
||||
// is encoded as [1.0, 2.0 ,3.0 ,4.0]
|
||||
// When this field is present, the data_type field MUST be FLOAT or COMPLEX64.
|
||||
repeated float float_data = 4 [packed = true];
|
||||
|
||||
// For int32, uint8, int8, uint16, int16, bool, and float16 values
|
||||
// float16 values must be bit-wise converted to an uint16_t prior
|
||||
// to writing to the buffer.
|
||||
// When this field is present, the data_type field MUST be
|
||||
// INT32, INT16, INT8, UINT16, UINT8, BOOL, or FLOAT16
|
||||
repeated int32 int32_data = 5 [packed = true];
|
||||
|
||||
// For strings.
|
||||
// Each element of string_data is a UTF-8 encoded Unicode
|
||||
// string. No trailing null, no leading BOM. The protobuf "string"
|
||||
// scalar type is not used to match ML community conventions.
|
||||
// When this field is present, the data_type field MUST be STRING
|
||||
repeated bytes string_data = 6;
|
||||
|
||||
// For int64.
|
||||
// When this field is present, the data_type field MUST be INT64
|
||||
repeated int64 int64_data = 7 [packed = true];
|
||||
|
||||
// Optionally, a name for the tensor.
|
||||
optional string name = 8; // namespace Value
|
||||
|
||||
// A human-readable documentation for this tensor. Markdown is allowed.
|
||||
optional string doc_string = 12;
|
||||
|
||||
// Serializations can either use one of the fields above, or use this
|
||||
// raw bytes field. The only exception is the string case, where one is
|
||||
// required to store the content in the repeated bytes string_data field.
|
||||
//
|
||||
// When this raw_data field is used to store tensor value, elements MUST
|
||||
// be stored in as fixed-width, little-endian order.
|
||||
// Floating-point data types MUST be stored in IEEE 754 format.
|
||||
// Complex64 elements must be written as two consecutive FLOAT values, real component first.
|
||||
// Complex128 elements must be written as two consecutive DOUBLE values, real component first.
|
||||
// Boolean type MUST be written one byte per tensor element (00000001 for true, 00000000 for false).
|
||||
//
|
||||
// Note: the advantage of specific field rather than the raw_data field is
|
||||
// that in some cases (e.g. int data), protobuf does a better packing via
|
||||
// variable length storage, and may lead to smaller binary footprint.
|
||||
// When this field is present, the data_type field MUST NOT be STRING or UNDEFINED
|
||||
optional bytes raw_data = 9;
|
||||
|
||||
// Data can be stored inside the protobuf file using type-specific fields or raw_data.
|
||||
// Alternatively, raw bytes data can be stored in an external file, using the external_data field.
|
||||
// external_data stores key-value pairs describing data location. Recognized keys are:
|
||||
// - "location" (required) - POSIX filesystem path relative to the directory where the ONNX
|
||||
// protobuf model was stored
|
||||
// - "offset" (optional) - position of byte at which stored data begins. Integer stored as string.
|
||||
// Offset values SHOULD be multiples 4096 (page size) to enable mmap support.
|
||||
// - "length" (optional) - number of bytes containing data. Integer stored as string.
|
||||
// - "checksum" (optional) - SHA1 digest of file specified in under 'location' key.
|
||||
repeated StringStringEntryProto external_data = 13;
|
||||
|
||||
// Location of the data for this tensor. MUST be one of:
|
||||
// - DEFAULT - data stored inside the protobuf message. Data is stored in raw_data (if set) otherwise in type-specified field.
|
||||
// - EXTERNAL - data stored in an external location as described by external_data field.
|
||||
enum DataLocation {
|
||||
DEFAULT = 0;
|
||||
EXTERNAL = 1;
|
||||
}
|
||||
|
||||
// If value not set, data is stored in raw_data (if set) otherwise in type-specified field.
|
||||
optional DataLocation data_location = 14;
|
||||
|
||||
// For double
|
||||
// Complex128 tensors are encoded as a single array of doubles,
|
||||
// with the real components appearing in odd numbered positions,
|
||||
// and the corresponding imaginary component apparing in the
|
||||
// subsequent even numbered position. (e.g., [1.0 + 2.0i, 3.0 + 4.0i]
|
||||
// is encoded as [1.0, 2.0 ,3.0 ,4.0]
|
||||
// When this field is present, the data_type field MUST be DOUBLE or COMPLEX128
|
||||
repeated double double_data = 10 [packed = true];
|
||||
|
||||
// For uint64 and uint32 values
|
||||
// When this field is present, the data_type field MUST be
|
||||
// UINT32 or UINT64
|
||||
repeated uint64 uint64_data = 11 [packed = true];
|
||||
}
|
||||
|
||||
// Defines a tensor shape. A dimension can be either an integer value
|
||||
// or a symbolic variable. A symbolic variable represents an unknown
|
||||
// dimension.
|
||||
message TensorShapeProto {
|
||||
message Dimension {
|
||||
oneof value {
|
||||
int64 dim_value = 1;
|
||||
string dim_param = 2; // namespace Shape
|
||||
};
|
||||
// Standard denotation can optionally be used to denote tensor
|
||||
// dimensions with standard semantic descriptions to ensure
|
||||
// that operations are applied to the correct axis of a tensor.
|
||||
// Refer to https://github.com/onnx/onnx/blob/master/docs/DimensionDenotation.md#denotation-definition
|
||||
// for pre-defined dimension denotations.
|
||||
optional string denotation = 3;
|
||||
};
|
||||
repeated Dimension dim = 1;
|
||||
}
|
||||
|
||||
// Types
|
||||
//
|
||||
// The standard ONNX data types.
|
||||
message TypeProto {
|
||||
|
||||
message Tensor {
|
||||
// This field MUST NOT have the value of UNDEFINED
|
||||
// This field MUST have a valid TensorProto.DataType value
|
||||
// This field MUST be present for this version of the IR.
|
||||
optional int32 elem_type = 1;
|
||||
optional TensorShapeProto shape = 2;
|
||||
}
|
||||
|
||||
|
||||
oneof value {
|
||||
// The type of a tensor.
|
||||
Tensor tensor_type = 1;
|
||||
|
||||
}
|
||||
|
||||
// An optional denotation can be used to denote the whole
|
||||
// type with a standard semantic description as to what is
|
||||
// stored inside. Refer to https://github.com/onnx/onnx/blob/master/docs/TypeDenotation.md#type-denotation-definition
|
||||
// for pre-defined type denotations.
|
||||
optional string denotation = 6;
|
||||
}
|
||||
|
||||
// Operator Sets
|
||||
//
|
||||
// OperatorSets are uniquely identified by a (domain, opset_version) pair.
|
||||
message OperatorSetIdProto {
|
||||
// The domain of the operator set being identified.
|
||||
// The empty string ("") or absence of this field implies the operator
|
||||
// set that is defined as part of the ONNX specification.
|
||||
// This field MUST be present in this version of the IR when referring to any other operator set.
|
||||
optional string domain = 1;
|
||||
|
||||
// The version of the operator set being identified.
|
||||
// This field MUST be present in this version of the IR.
|
||||
optional int64 version = 2;
|
||||
}
|
||||
5996
3rdparty/ncnn/tools/onnx/onnx2ncnn.cpp
vendored
Normal file
5996
3rdparty/ncnn/tools/onnx/onnx2ncnn.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
37
3rdparty/ncnn/tools/plugin/ImageWatchNCNN.natvis
vendored
Normal file
37
3rdparty/ncnn/tools/plugin/ImageWatchNCNN.natvis
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
|
||||
<UIVisualizer ServiceId="{A452AFEA-3DF6-46BB-9177-C0B08F318025}" Id="1" MenuName="Add to Image Watch"/>
|
||||
|
||||
<!-- Tencent NCNN ncnn::Mat support -->
|
||||
|
||||
<Type Name="ncnn::Mat">
|
||||
<UIVisualizer ServiceId="{A452AFEA-3DF6-46BB-9177-C0B08F318025}" Id="1" />
|
||||
</Type>
|
||||
|
||||
<Type Name="ncnn::Mat">
|
||||
<DisplayString Condition="elemsize==4">{{FLOAT32, {c} x {w} x {h}}}</DisplayString>
|
||||
<DisplayString Condition="elemsize==2">{{FLOAT16, {c} x {w} x {h}}}</DisplayString>
|
||||
<DisplayString Condition="elemsize==1">{{INT8, {c} x {w} x {h}}}</DisplayString>
|
||||
<Expand>
|
||||
<Synthetic Name="[type]" Condition="elemsize==4">
|
||||
<DisplayString>FLOAT32</DisplayString>
|
||||
</Synthetic>
|
||||
<Synthetic Name="[type]" Condition="elemsize==2">
|
||||
<DisplayString>FLOAT16</DisplayString>
|
||||
</Synthetic>
|
||||
<Synthetic Name="[type]" Condition="elemsize==1">
|
||||
<DisplayString>INT8</DisplayString>
|
||||
</Synthetic>
|
||||
<Item Name="[channels]">c</Item>
|
||||
<Item Name="[width]">w</Item>
|
||||
<Item Name="[height]">h</Item>
|
||||
<Item Name="[planes]">c</Item>
|
||||
<Item Name="[data]" Condition="elemsize==4">((float*)(data))</Item>
|
||||
<Item Name="[data]" Condition="elemsize==2">data</Item>
|
||||
<Item Name="[data]" Condition="elemsize==1">data</Item>
|
||||
<Item Name="[stride]" Condition="elemsize==1">w</Item>
|
||||
<Item Name="[stride]" Condition="elemsize==2">w*2</Item>
|
||||
<Item Name="[stride]" Condition="elemsize==4">w*4</Item>
|
||||
</Expand>
|
||||
</Type>
|
||||
</AutoVisualizer>
|
||||
30
3rdparty/ncnn/tools/plugin/ImageWatchNNIE.natvis
vendored
Normal file
30
3rdparty/ncnn/tools/plugin/ImageWatchNNIE.natvis
vendored
Normal file
@@ -0,0 +1,30 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
|
||||
<UIVisualizer ServiceId="{A452AFEA-3DF6-46BB-9177-C0B08F318025}" Id="1" MenuName="Add to Image Watch"/>
|
||||
|
||||
<!-- Tencent NCNN ncnn::Mat support -->
|
||||
|
||||
<Type Name="hiSVP_BLOB_S">
|
||||
<UIVisualizer ServiceId="{A452AFEA-3DF6-46BB-9177-C0B08F318025}" Id="1" />
|
||||
</Type>
|
||||
|
||||
<Type Name="hiSVP_BLOB_S">
|
||||
<DisplayString Condition="enType==0">{{INT32, {unShape.stWhc.u32Chn} x {unShape.stWhc.u32Width} x {unShape.stWhc.u32Height}}}</DisplayString>
|
||||
<DisplayString Condition="enType==1">{{UINT8, {unShape.stWhc.u32Chn} x {unShape.stWhc.u32Width} x {unShape.stWhc.u32Height}}}</DisplayString>
|
||||
<Expand>
|
||||
<Synthetic Name="[type]" Condition="enType==0">
|
||||
<DisplayString>INT32</DisplayString>
|
||||
</Synthetic>
|
||||
<Synthetic Name="[type]" Condition="enType==1">
|
||||
<DisplayString>UINT8</DisplayString>
|
||||
</Synthetic>
|
||||
<Item Name="[channels]">unShape.stWhc.u32Chn</Item>
|
||||
<Item Name="[width]">unShape.stWhc.u32Width</Item>
|
||||
<Item Name="[height]">unShape.stWhc.u32Height</Item>
|
||||
<Item Name="[planes]">unShape.stWhc.u32Chn</Item>
|
||||
<Item Name="[data]">u64VirAddr</Item>
|
||||
<Item Name="[stride]" Condition="enType==0">u32Stride</Item>
|
||||
<Item Name="[stride]" Condition="enType==1">u32Stride</Item>
|
||||
</Expand>
|
||||
</Type>
|
||||
</AutoVisualizer>
|
||||
15
3rdparty/ncnn/tools/plugin/README.md
vendored
Normal file
15
3rdparty/ncnn/tools/plugin/README.md
vendored
Normal file
@@ -0,0 +1,15 @@
|
||||
## NCNN Image Watch Plugin for Visual Studio
|
||||
Image Watch plugin is a good tool for better understanding insight of images. This tiny work offer a ".natvis" file which could add ncnn::Mat class support for Image Watch, and users could debug ncnn::Mat image just like debuging cv::Mat via Image Watch.
|
||||
|
||||
To use this plugin, please move this "ImageWatchNCNN.natvis" file to "C:/user/${your user name}/Documents/Visual Studio ${VS_Version}/Visualizers" folder. If not exist this folder, create it(such as: "C:\Users\nihui\Documents\Visual Studio 2017\Visualizers").
|
||||
|
||||

|
||||
|
||||
See [Image Watch Help](https://imagewatch.azurewebsites.net/ImageWatchHelp/ImageWatchHelp.htm) page for more advanced using tips of Image Watch(For example, get single channel from channels, such as getting confidence heatmap from forward result list {confidence, x1, y1, x2, y2}).
|
||||
|
||||
## NNIE Image Watch Plugin for Visual Studio
|
||||
This image plugin will be a part of NNIE Plugin for NCNN(NPN). NPN will be a WIP, it should be completed by the end of Septembe.
|
||||
|
||||
The plugin support SVP_BLOB_TYPE_S32 and SVP_BLOB_TYPE_U8 for now.
|
||||
|
||||

|
||||
BIN
3rdparty/ncnn/tools/plugin/ncnn_snapshot.png
vendored
Normal file
BIN
3rdparty/ncnn/tools/plugin/ncnn_snapshot.png
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 310 KiB |
BIN
3rdparty/ncnn/tools/plugin/nnie_snapshot.png
vendored
Normal file
BIN
3rdparty/ncnn/tools/plugin/nnie_snapshot.png
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 58 KiB |
70
3rdparty/ncnn/tools/pnnx/CMakeLists.txt
vendored
Normal file
70
3rdparty/ncnn/tools/pnnx/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,70 @@
|
||||
|
||||
if(NOT CMAKE_VERSION VERSION_LESS "3.15")
|
||||
# enable CMAKE_MSVC_RUNTIME_LIBRARY
|
||||
cmake_policy(SET CMP0091 NEW)
|
||||
endif()
|
||||
|
||||
project(pnnx)
|
||||
cmake_minimum_required(VERSION 3.12)
|
||||
|
||||
if(POLICY CMP0074)
|
||||
cmake_policy(SET CMP0074 NEW)
|
||||
endif()
|
||||
|
||||
if(MSVC AND NOT CMAKE_VERSION VERSION_LESS "3.15")
|
||||
option(PNNX_BUILD_WITH_STATIC_CRT "Enables use of statically linked CRT for statically linked pnnx" OFF)
|
||||
if(PNNX_BUILD_WITH_STATIC_CRT)
|
||||
# cmake before version 3.15 not work
|
||||
set(CMAKE_MSVC_RUNTIME_LIBRARY "MultiThreaded$<$<CONFIG:Debug>:Debug>")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
list(APPEND CMAKE_MODULE_PATH "${CMAKE_CURRENT_SOURCE_DIR}/cmake")
|
||||
include(PNNXPyTorch)
|
||||
|
||||
# c++14 is required for using torch headers
|
||||
set(CMAKE_CXX_STANDARD 14)
|
||||
|
||||
#set(CMAKE_BUILD_TYPE debug)
|
||||
#set(CMAKE_BUILD_TYPE relwithdebinfo)
|
||||
#set(CMAKE_BUILD_TYPE release)
|
||||
|
||||
option(PNNX_COVERAGE "build for coverage" OFF)
|
||||
|
||||
#set(Torch_INSTALL_DIR "/home/nihui/.local/lib/python3.9/site-packages/torch" CACHE STRING "")
|
||||
#set(Torch_INSTALL_DIR "/home/nihui/osd/pnnx/pytorch-v1.10.0/build/install" CACHE STRING "")
|
||||
#set(Torch_INSTALL_DIR "/home/nihui/osd/pnnx/libtorch" CACHE STRING "")
|
||||
set(TorchVision_INSTALL_DIR "/home/nihui/osd/vision/build/install" CACHE STRING "")
|
||||
|
||||
#set(Torch_DIR "${Torch_INSTALL_DIR}/share/cmake/Torch")
|
||||
set(TorchVision_DIR "${TorchVision_INSTALL_DIR}/share/cmake/TorchVision")
|
||||
|
||||
find_package(Python3 COMPONENTS Interpreter Development)
|
||||
|
||||
PNNXProbeForPyTorchInstall()
|
||||
find_package(Torch REQUIRED)
|
||||
|
||||
find_package(TorchVision QUIET)
|
||||
|
||||
message(STATUS "Torch_VERSION = ${Torch_VERSION}")
|
||||
message(STATUS "Torch_VERSION_MAJOR = ${Torch_VERSION_MAJOR}")
|
||||
message(STATUS "Torch_VERSION_MINOR = ${Torch_VERSION_MINOR}")
|
||||
message(STATUS "Torch_VERSION_PATCH = ${Torch_VERSION_PATCH}")
|
||||
|
||||
if(Torch_VERSION VERSION_LESS "1.8")
|
||||
message(FATAL_ERROR "pnnx only supports PyTorch >= 1.8")
|
||||
endif()
|
||||
|
||||
if(TorchVision_FOUND)
|
||||
message(STATUS "Building with TorchVision")
|
||||
add_definitions(-DPNNX_TORCHVISION)
|
||||
else()
|
||||
message(WARNING "Building without TorchVision")
|
||||
endif()
|
||||
|
||||
include_directories(${TORCH_INCLUDE_DIRS})
|
||||
|
||||
add_subdirectory(src)
|
||||
|
||||
enable_testing()
|
||||
add_subdirectory(tests)
|
||||
658
3rdparty/ncnn/tools/pnnx/README.md
vendored
Normal file
658
3rdparty/ncnn/tools/pnnx/README.md
vendored
Normal file
@@ -0,0 +1,658 @@
|
||||
# PNNX
|
||||
PyTorch Neural Network eXchange(PNNX) is an open standard for PyTorch model interoperability. PNNX provides an open model format for PyTorch. It defines computation graph as well as high level operators strictly matches PyTorch.
|
||||
|
||||
# Rationale
|
||||
PyTorch is currently one of the most popular machine learning frameworks. We need to deploy the trained AI model to various hardware and environments more conveniently and easily.
|
||||
|
||||
Before PNNX, we had the following methods:
|
||||
|
||||
1. export to ONNX, and deploy with ONNX-runtime
|
||||
2. export to ONNX, and convert onnx to inference-framework specific format, and deploy with TensorRT/OpenVINO/ncnn/etc.
|
||||
3. export to TorchScript, and deploy with libtorch
|
||||
|
||||
As far as we know, ONNX has the ability to express the PyTorch model and it is an open standard. People usually use ONNX as an intermediate representation between PyTorch and the inference platform. However, ONNX still has the following fatal problems, which makes the birth of PNNX necessary:
|
||||
|
||||
1. ONNX does not have a human-readable and editable file representation, making it difficult for users to easily modify the computation graph or add custom operators.
|
||||
2. The operator definition of ONNX is not completely in accordance with PyTorch. When exporting some PyTorch operators, glue operators are often added passively by ONNX, which makes the computation graph inconsistent with PyTorch and may impact the inference efficiency.
|
||||
3. There are a large number of additional parameters designed to be compatible with various ML frameworks in the operator definition in ONNX. These parameters increase the burden of inference implementation on hardware and software.
|
||||
|
||||
PNNX tries to define a set of operators and a simple and easy-to-use format that are completely contrasted with the python api of PyTorch, so that the conversion and interoperability of PyTorch models are more convenient.
|
||||
|
||||
# Features
|
||||
|
||||
1. [Human readable and editable format](#the-pnnxparam-format)
|
||||
2. [Plain model binary in storage zip](#the-pnnxbin-format)
|
||||
3. [One-to-one mapping of PNNX operators and PyTorch python api](#pnnx-operator)
|
||||
4. [Preserve math expression as one operator](#pnnx-expression-operator)
|
||||
5. [Preserve torch function as one operator](#pnnx-torch-function-operator)
|
||||
6. [Preserve miscellaneous module as one operator](#pnnx-module-operator)
|
||||
7. [Inference via exported PyTorch python code](#pnnx-python-inference)
|
||||
8. [Tensor shape propagation](#pnnx-shape-propagation)
|
||||
9. [Model optimization](#pnnx-model-optimization)
|
||||
10. [Custom operator support](#pnnx-custom-operator)
|
||||
|
||||
# Build TorchScript to PNNX converter
|
||||
|
||||
1. Install PyTorch and TorchVision c++ library
|
||||
2. Build PNNX with cmake
|
||||
|
||||
# Usage
|
||||
|
||||
1. Export your model to TorchScript
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torchvision.models as models
|
||||
|
||||
net = models.resnet18(pretrained=True)
|
||||
net = net.eval()
|
||||
|
||||
x = torch.rand(1, 3, 224, 224)
|
||||
|
||||
mod = torch.jit.trace(net, x)
|
||||
torch.jit.save(mod, "resnet18.pt")
|
||||
```
|
||||
|
||||
2. Convert TorchScript to PNNX
|
||||
|
||||
```shell
|
||||
pnnx resnet18.pt inputshape=[1,3,224,224]
|
||||
```
|
||||
|
||||
Normally, you will get six files
|
||||
|
||||
```resnet18.pnnx.param``` PNNX graph definition
|
||||
|
||||
```resnet18.pnnx.bin``` PNNX model weight
|
||||
|
||||
```resnet18_pnnx.py``` PyTorch script for inference, the python code for model construction and weight initialization
|
||||
|
||||
```resnet18.ncnn.param``` ncnn graph definition
|
||||
|
||||
```resnet18.ncnn.bin``` ncnn model weight
|
||||
|
||||
```resnet18_ncnn.py``` pyncnn script for inference
|
||||
|
||||
3. Visualize PNNX with Netron
|
||||
|
||||
Open https://netron.app/ in browser, and drag resnet18.pnnx.param into it.
|
||||
|
||||
4. PNNX command line options
|
||||
|
||||
```
|
||||
Usage: pnnx [model.pt] [(key=value)...]
|
||||
pnnxparam=model.pnnx.param
|
||||
pnnxbin=model.pnnx.bin
|
||||
pnnxpy=model_pnnx.py
|
||||
ncnnparam=model.ncnn.param
|
||||
ncnnbin=model.ncnn.bin
|
||||
ncnnpy=model_ncnn.py
|
||||
optlevel=2
|
||||
device=cpu/gpu
|
||||
inputshape=[1,3,224,224],...
|
||||
inputshape2=[1,3,320,320],...
|
||||
customop=/home/nihui/.cache/torch_extensions/fused/fused.so,...
|
||||
moduleop=models.common.Focus,models.yolo.Detect,...
|
||||
Sample usage: pnnx mobilenet_v2.pt inputshape=[1,3,224,224]
|
||||
pnnx yolov5s.pt inputshape=[1,3,640,640] inputshape2=[1,3,320,320] device=gpu moduleop=models.common.Focus,models.yolo.Detect
|
||||
```
|
||||
|
||||
Parameters:
|
||||
|
||||
`pnnxparam` (default="*.pnnx.param", * is the model name): PNNX graph definition file
|
||||
|
||||
`pnnxbin` (default="*.pnnx.bin"): PNNX model weight
|
||||
|
||||
`pnnxpy` (default="*_pnnx.py"): PyTorch script for inference, including model construction and weight initialization code
|
||||
|
||||
`ncnnparam` (default="*.ncnn.param"): ncnn graph definition
|
||||
|
||||
`ncnnbin` (default="*.ncnn.bin"): ncnn model weight
|
||||
|
||||
`ncnnpy` (default="*_ncnn.py"): pyncnn script for inference
|
||||
|
||||
`optlevel` (default=2): graph optimization level
|
||||
|
||||
| Option | Optimization level |
|
||||
|--------|---------------------------------|
|
||||
| 0 | do not apply optimization |
|
||||
| 1 | optimization for inference |
|
||||
| 2 | optimization more for inference |
|
||||
|
||||
`device` (default="cpu"): device type for the input in TorchScript model, cpu or gpu
|
||||
|
||||
`inputshape` (Optional): shapes of model inputs. It is used to resolve tensor shapes in model graph. for example, `[1,3,224,224]` for the model with only 1 input, `[1,3,224,224],[1,3,224,224]` for the model that have 2 inputs.
|
||||
|
||||
`inputshape2` (Optional): shapes of alternative model inputs, the format is identical to `inputshape`. Usually, it is used with `inputshape` to resolve dynamic shape (-1) in model graph.
|
||||
|
||||
`customop` (Optional): list of Torch extensions (dynamic library) for custom operators, separated by ",". For example, `/home/nihui/.cache/torch_extensions/fused/fused.so,...`
|
||||
|
||||
`moduleop` (Optional): list of modules to keep as one big operator, separated by ",". for example, `models.common.Focus,models.yolo.Detect`
|
||||
|
||||
# The pnnx.param format
|
||||
|
||||
### example
|
||||
```
|
||||
7767517
|
||||
4 3
|
||||
pnnx.Input input 0 1 0
|
||||
nn.Conv2d conv_0 1 1 0 1 bias=1 dilation=(1,1) groups=1 in_channels=12 kernel_size=(3,3) out_channels=16 padding=(0,0) stride=(1,1) @bias=(16)f32 @weight=(16,12,3,3)f32
|
||||
nn.Conv2d conv_1 1 1 1 2 bias=1 dilation=(1,1) groups=1 in_channels=16 kernel_size=(2,2) out_channels=20 padding=(2,2) stride=(2,2) @bias=(20)f32 @weight=(20,16,2,2)f32
|
||||
pnnx.Output output 1 0 2
|
||||
```
|
||||
### overview
|
||||
```
|
||||
[magic]
|
||||
```
|
||||
* magic number : 7767517
|
||||
```
|
||||
[operator count] [operand count]
|
||||
```
|
||||
* operator count : count of the operator line follows
|
||||
* operand count : count of all operands
|
||||
### operator line
|
||||
```
|
||||
[type] [name] [input count] [output count] [input operands] [output operands] [operator params]
|
||||
```
|
||||
* type : type name, such as Conv2d ReLU etc
|
||||
* name : name of this operator
|
||||
* input count : count of the operands this operator needs as input
|
||||
* output count : count of the operands this operator produces as output
|
||||
* input operands : name list of all the input blob names, separated by space
|
||||
* output operands : name list of all the output blob names, separated by space
|
||||
* operator params : key=value pair list, separated by space, operator weights are prefixed by ```@``` symbol, tensor shapes are prefixed by ```#``` symbol, input parameter keys are prefixed by ```$```
|
||||
|
||||
# The pnnx.bin format
|
||||
|
||||
pnnx.bin file is a zip file with store-only mode(no compression)
|
||||
|
||||
weight binary file has its name composed by operator name and weight name
|
||||
|
||||
For example, ```nn.Conv2d conv_0 1 1 0 1 bias=1 dilation=(1,1) groups=1 in_channels=12 kernel_size=(3,3) out_channels=16 padding=(0,0) stride=(1,1) @bias=(16) @weight=(16,12,3,3)``` would pull conv_0.weight and conv_0.bias into pnnx.bin zip archive.
|
||||
|
||||
weight binaries can be listed or modified with any archive application eg. 7zip
|
||||
|
||||
|
||||
|
||||
# PNNX operator
|
||||
PNNX always preserve operators from what PyTorch python api provides.
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
self.attention = nn.MultiheadAttention(embed_dim=256, num_heads=32)
|
||||
|
||||
def forward(self, x):
|
||||
x, _ = self.attention(x, x, x)
|
||||
return x
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|
|
||||
|----|---|---|
|
||||
||||
|
||||
|
||||
# PNNX expression operator
|
||||
PNNX trys to preserve expression from what PyTorch python code writes.
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
def foo(x, y):
|
||||
return torch.sqrt((2 * x + y) / 12)
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|
|
||||
|---|---|---|
|
||||
||||
|
||||
|
||||
# PNNX torch function operator
|
||||
PNNX trys to preserve torch functions and Tensor member functions as one operator from what PyTorch python api provides.
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
def forward(self, x):
|
||||
x = F.normalize(x, eps=1e-3)
|
||||
return x
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|
|
||||
|---|---|---|
|
||||
||||
|
||||
|
||||
|
||||
# PNNX module operator
|
||||
Users could ask PNNX to keep module as one big operator when it has complex logic.
|
||||
|
||||
The process is optional and could be enabled via moduleop command line option.
|
||||
|
||||
After pass_level0, all modules will be presented in terminal output, then you can pick the intersting ones as module operators.
|
||||
```
|
||||
############# pass_level0
|
||||
inline module = models.common.Bottleneck
|
||||
inline module = models.common.C3
|
||||
inline module = models.common.Concat
|
||||
inline module = models.common.Conv
|
||||
inline module = models.common.Focus
|
||||
inline module = models.common.SPP
|
||||
inline module = models.yolo.Detect
|
||||
inline module = utils.activations.SiLU
|
||||
```
|
||||
|
||||
```bash
|
||||
pnnx yolov5s.pt inputshape=[1,3,640,640] moduleop=models.common.Focus,models.yolo.Detect
|
||||
```
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
class Focus(nn.Module):
|
||||
# Focus wh information into c-space
|
||||
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
||||
super().__init__()
|
||||
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
|
||||
|
||||
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
|
||||
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|PNNX with module operator|
|
||||
|---|---|---|---|
|
||||
|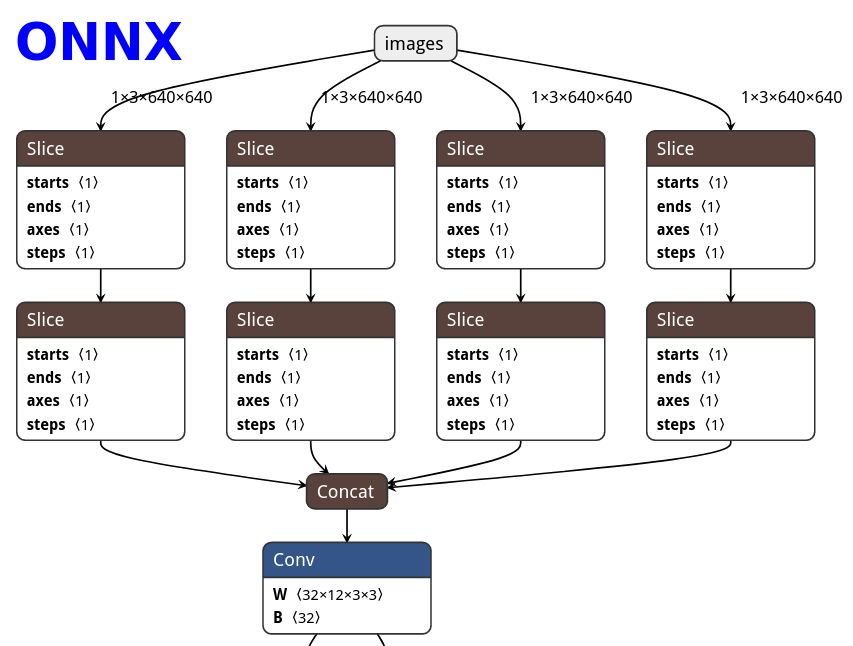|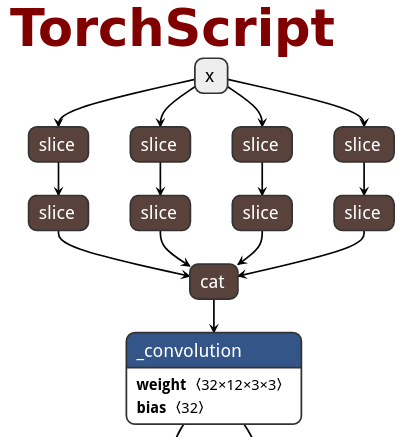|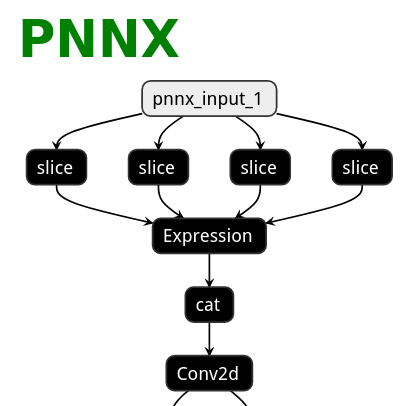|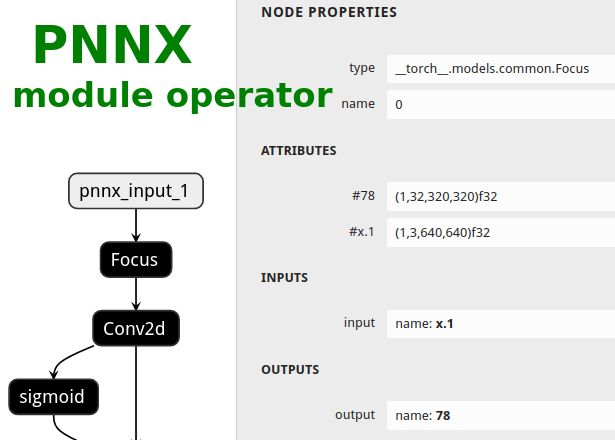|
|
||||
|
||||
|
||||
# PNNX python inference
|
||||
|
||||
A python script will be generated by default when converting torchscript to pnnx.
|
||||
|
||||
This script is the python code representation of PNNX and can be used for model inference.
|
||||
|
||||
There are some utility functions for loading weight binary from pnnx.bin.
|
||||
|
||||
You can even export the model torchscript AGAIN from this generated code!
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
self.linear_0 = nn.Linear(in_features=128, out_features=256, bias=True)
|
||||
self.linear_1 = nn.Linear(in_features=256, out_features=4, bias=True)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.linear_0(x)
|
||||
x = F.leaky_relu(x, 0.15)
|
||||
x = self.linear_1(x)
|
||||
return x
|
||||
```
|
||||
|
||||
```python
|
||||
import os
|
||||
import numpy as np
|
||||
import tempfile, zipfile
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
self.linear_0 = nn.Linear(bias=True, in_features=128, out_features=256)
|
||||
self.linear_1 = nn.Linear(bias=True, in_features=256, out_features=4)
|
||||
|
||||
archive = zipfile.ZipFile('../../function.pnnx.bin', 'r')
|
||||
self.linear_0.bias = self.load_pnnx_bin_as_parameter(archive, 'linear_0.bias', (256), 'float32')
|
||||
self.linear_0.weight = self.load_pnnx_bin_as_parameter(archive, 'linear_0.weight', (256,128), 'float32')
|
||||
self.linear_1.bias = self.load_pnnx_bin_as_parameter(archive, 'linear_1.bias', (4), 'float32')
|
||||
self.linear_1.weight = self.load_pnnx_bin_as_parameter(archive, 'linear_1.weight', (4,256), 'float32')
|
||||
archive.close()
|
||||
|
||||
def load_pnnx_bin_as_parameter(self, archive, key, shape, dtype):
|
||||
return nn.Parameter(self.load_pnnx_bin_as_tensor(archive, key, shape, dtype))
|
||||
|
||||
def load_pnnx_bin_as_tensor(self, archive, key, shape, dtype):
|
||||
_, tmppath = tempfile.mkstemp()
|
||||
tmpf = open(tmppath, 'wb')
|
||||
with archive.open(key) as keyfile:
|
||||
tmpf.write(keyfile.read())
|
||||
tmpf.close()
|
||||
m = np.memmap(tmppath, dtype=dtype, mode='r', shape=shape).copy()
|
||||
os.remove(tmppath)
|
||||
return torch.from_numpy(m)
|
||||
|
||||
def forward(self, v_x_1):
|
||||
v_7 = self.linear_0(v_x_1)
|
||||
v_input_1 = F.leaky_relu(input=v_7, negative_slope=0.150000)
|
||||
v_12 = self.linear_1(v_input_1)
|
||||
return v_12
|
||||
```
|
||||
|
||||
# PNNX shape propagation
|
||||
Users could ask PNNX to resolve all tensor shapes in model graph and constify some common expressions involved when tensor shapes are known.
|
||||
|
||||
The process is optional and could be enabled via inputshape command line option.
|
||||
|
||||
```bash
|
||||
pnnx shufflenet_v2_x1_0.pt inputshape=[1,3,224,224]
|
||||
```
|
||||
|
||||
```python
|
||||
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
|
||||
batchsize, num_channels, height, width = x.size()
|
||||
channels_per_group = num_channels // groups
|
||||
|
||||
# reshape
|
||||
x = x.view(batchsize, groups, channels_per_group, height, width)
|
||||
|
||||
x = torch.transpose(x, 1, 2).contiguous()
|
||||
|
||||
# flatten
|
||||
x = x.view(batchsize, -1, height, width)
|
||||
|
||||
return x
|
||||
```
|
||||
|
||||
|without shape propagation|with shape propagation|
|
||||
|---|---|
|
||||
|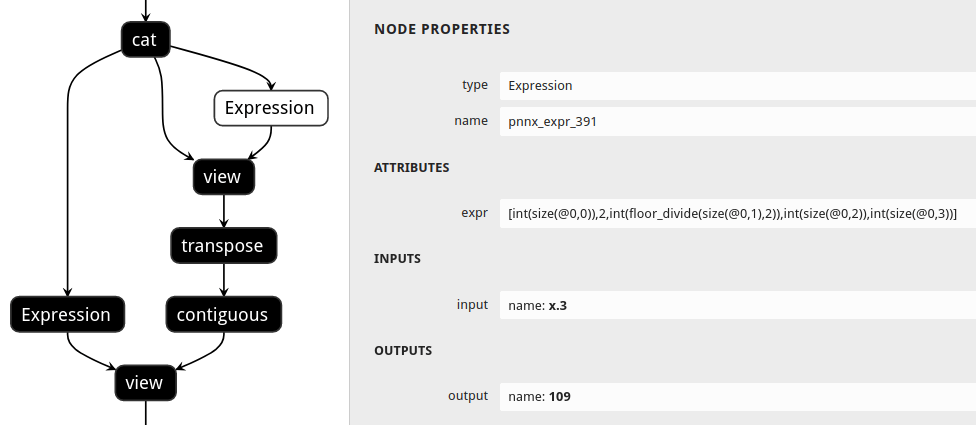|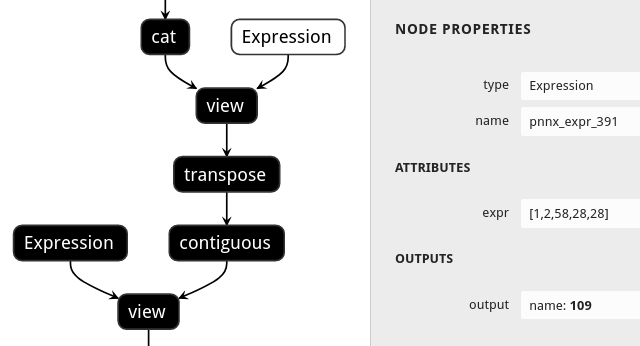|
|
||||
|
||||
|
||||
# PNNX model optimization
|
||||
|
||||
|ONNX|TorchScript|PNNX without optimization|PNNX with optimization|
|
||||
|---|---|---|---|
|
||||
|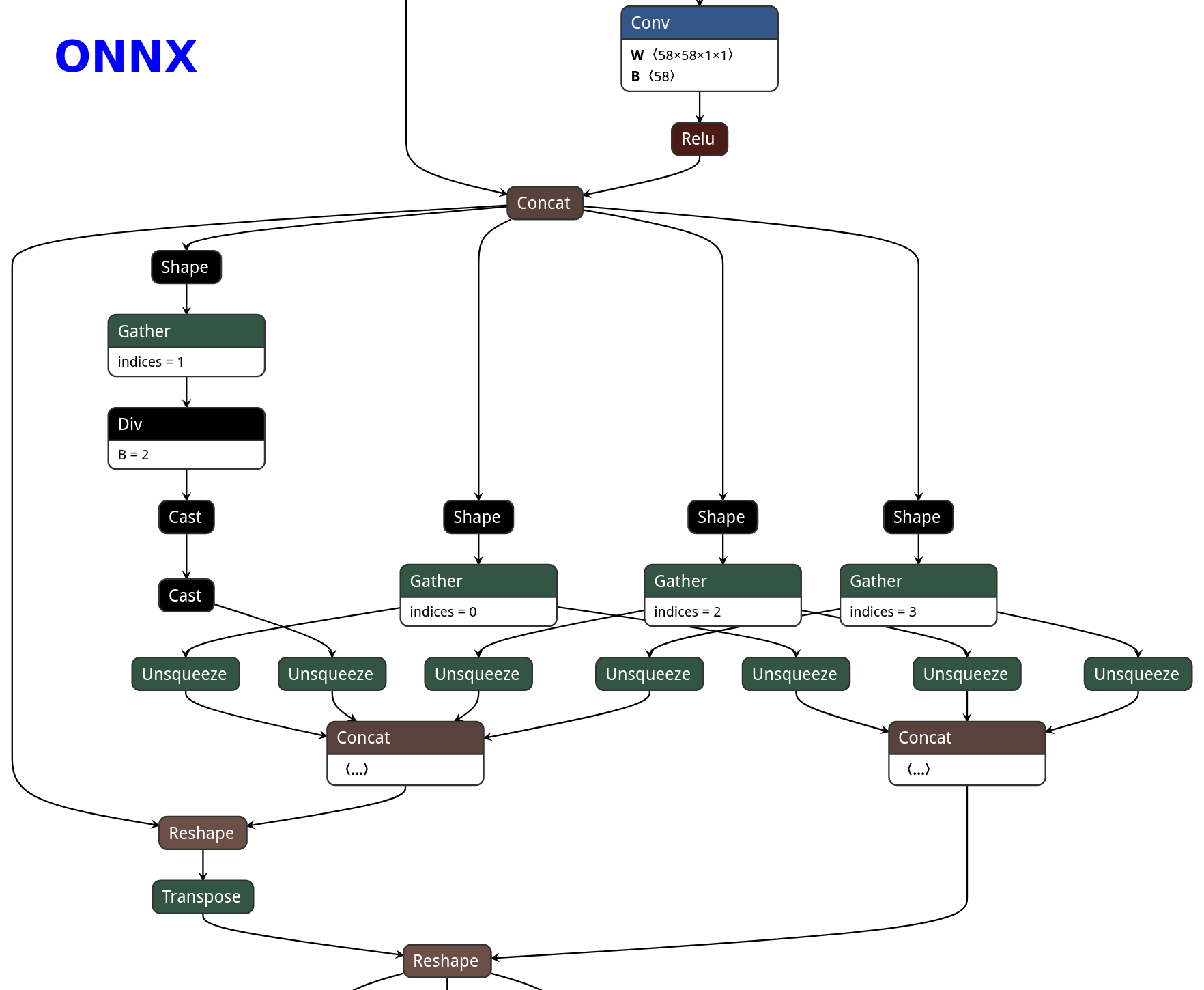|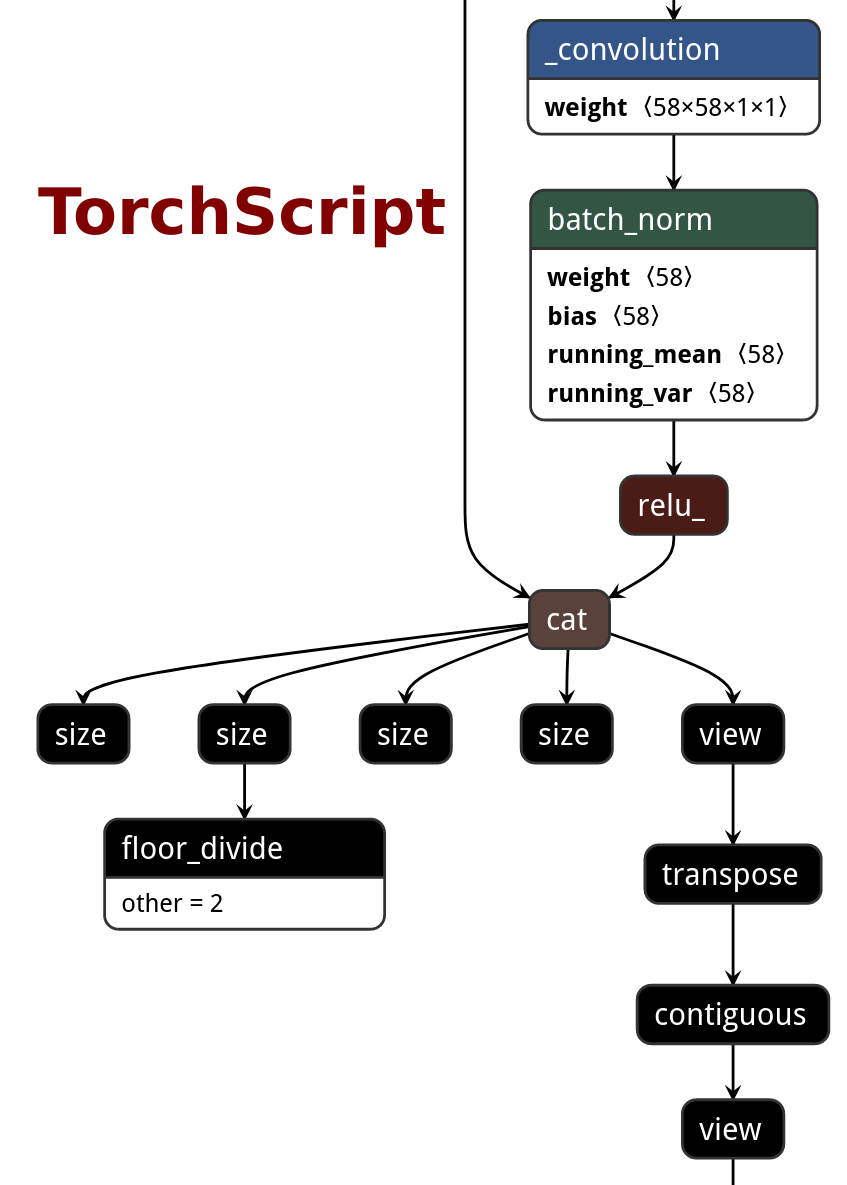|||
|
||||
|
||||
|
||||
# PNNX custom operator
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
import torch
|
||||
from torch.autograd import Function
|
||||
from torch.utils.cpp_extension import load, _import_module_from_library
|
||||
|
||||
module_path = os.path.dirname(__file__)
|
||||
upfirdn2d_op = load(
|
||||
'upfirdn2d',
|
||||
sources=[
|
||||
os.path.join(module_path, 'upfirdn2d.cpp'),
|
||||
os.path.join(module_path, 'upfirdn2d_kernel.cu'),
|
||||
],
|
||||
is_python_module=False
|
||||
)
|
||||
|
||||
def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
|
||||
pad_x0 = pad[0]
|
||||
pad_x1 = pad[1]
|
||||
pad_y0 = pad[0]
|
||||
pad_y1 = pad[1]
|
||||
|
||||
kernel_h, kernel_w = kernel.shape
|
||||
batch, channel, in_h, in_w = input.shape
|
||||
|
||||
input = input.reshape(-1, in_h, in_w, 1)
|
||||
|
||||
out_h = (in_h * up + pad_y0 + pad_y1 - kernel_h) // down + 1
|
||||
out_w = (in_w * up + pad_x0 + pad_x1 - kernel_w) // down + 1
|
||||
|
||||
out = torch.ops.upfirdn2d_op.upfirdn2d(input, kernel, up, up, down, down, pad_x0, pad_x1, pad_y0, pad_y1)
|
||||
|
||||
out = out.view(-1, channel, out_h, out_w)
|
||||
|
||||
return out
|
||||
```
|
||||
|
||||
```cpp
|
||||
#include <torch/extension.h>
|
||||
|
||||
torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
|
||||
int64_t up_x, int64_t up_y, int64_t down_x, int64_t down_y,
|
||||
int64_t pad_x0, int64_t pad_x1, int64_t pad_y0, int64_t pad_y1) {
|
||||
// operator body
|
||||
}
|
||||
|
||||
TORCH_LIBRARY(upfirdn2d_op, m) {
|
||||
m.def("upfirdn2d", upfirdn2d);
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://raw.githubusercontent.com/nihui/ncnn-assets/master/pnnx/customop.pnnx.png" width="400" />
|
||||
|
||||
# Supported PyTorch operator status
|
||||
|
||||
| torch.nn | Is Supported | Export to ncnn |
|
||||
|---------------------------|----|---|
|
||||
|nn.AdaptiveAvgPool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveAvgPool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveAvgPool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveMaxPool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveMaxPool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveMaxPool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AlphaDropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AvgPool1d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.AvgPool2d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.AvgPool3d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.BatchNorm1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.BatchNorm2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.BatchNorm3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Bilinear | |
|
||||
|nn.CELU | :heavy_check_mark: |
|
||||
|nn.ChannelShuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConstantPad1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConstantPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConstantPad3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Conv1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Conv2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Conv3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConvTranspose1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConvTranspose2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConvTranspose3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.CosineSimilarity | |
|
||||
|nn.Dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Dropout2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Dropout3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ELU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Embedding | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.EmbeddingBag | |
|
||||
|nn.Flatten | :heavy_check_mark: |
|
||||
|nn.Fold | |
|
||||
|nn.FractionalMaxPool2d | |
|
||||
|nn.FractionalMaxPool3d | |
|
||||
|nn.GELU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.GroupNorm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.GRU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.GRUCell | |
|
||||
|nn.Hardshrink | :heavy_check_mark: |
|
||||
|nn.Hardsigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Hardswish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Hardtanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Identity | |
|
||||
|nn.InstanceNorm1d | :heavy_check_mark: |
|
||||
|nn.InstanceNorm2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.InstanceNorm3d | :heavy_check_mark: |
|
||||
|nn.LayerNorm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LazyBatchNorm1d | |
|
||||
|nn.LazyBatchNorm2d | |
|
||||
|nn.LazyBatchNorm3d | |
|
||||
|nn.LazyConv1d | |
|
||||
|nn.LazyConv2d | |
|
||||
|nn.LazyConv3d | |
|
||||
|nn.LazyConvTranspose1d | |
|
||||
|nn.LazyConvTranspose2d | |
|
||||
|nn.LazyConvTranspose3d | |
|
||||
|nn.LazyLinear | |
|
||||
|nn.LeakyReLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Linear | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LocalResponseNorm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LogSigmoid | :heavy_check_mark: |
|
||||
|nn.LogSoftmax | :heavy_check_mark: |
|
||||
|nn.LPPool1d | :heavy_check_mark: |
|
||||
|nn.LPPool2d | :heavy_check_mark: |
|
||||
|nn.LSTM | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LSTMCell | |
|
||||
|nn.MaxPool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MaxPool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MaxPool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MaxUnpool1d | |
|
||||
|nn.MaxUnpool2d | |
|
||||
|nn.MaxUnpool3d | |
|
||||
|nn.Mish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MultiheadAttention | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.PairwiseDistance | |
|
||||
|nn.PixelShuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.PixelUnshuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.PReLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReflectionPad1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReflectionPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReLU6 | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReplicationPad1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReplicationPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReplicationPad3d | :heavy_check_mark: |
|
||||
|nn.RNN | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.RNNBase | |
|
||||
|nn.RNNCell | |
|
||||
|nn.RReLU | :heavy_check_mark: |
|
||||
|nn.SELU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Sigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.SiLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Softmax | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Softmax2d | |
|
||||
|nn.Softmin | :heavy_check_mark: |
|
||||
|nn.Softplus | :heavy_check_mark: |
|
||||
|nn.Softshrink | :heavy_check_mark: |
|
||||
|nn.Softsign | :heavy_check_mark: |
|
||||
|nn.SyncBatchNorm | |
|
||||
|nn.Tanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Tanhshrink | :heavy_check_mark: |
|
||||
|nn.Threshold | :heavy_check_mark: |
|
||||
|nn.Transformer | |
|
||||
|nn.TransformerDecoder | |
|
||||
|nn.TransformerDecoderLayer | |
|
||||
|nn.TransformerEncoder | |
|
||||
|nn.TransformerEncoderLayer | |
|
||||
|nn.Unflatten | |
|
||||
|nn.Unfold | |
|
||||
|nn.Upsample | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.UpsamplingBilinear2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.UpsamplingNearest2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ZeroPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|
||||
|
||||
| torch.nn.functional | Is Supported | Export to ncnn |
|
||||
|---------------------------|----|----|
|
||||
|F.adaptive_avg_pool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_avg_pool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_avg_pool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_max_pool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_max_pool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_max_pool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.affine_grid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.alpha_dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.avg_pool1d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.avg_pool2d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.avg_pool3d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.batch_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.bilinear | |
|
||||
|F.celu | :heavy_check_mark: |
|
||||
|F.conv1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv_transpose1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv_transpose2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv_transpose3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.cosine_similarity | |
|
||||
|F.dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.dropout2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.dropout3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.elu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.elu_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.embedding | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.embedding_bag | |
|
||||
|F.feature_alpha_dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.fold | |
|
||||
|F.fractional_max_pool2d | |
|
||||
|F.fractional_max_pool3d | |
|
||||
|F.gelu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.glu | |
|
||||
|F.grid_sample | :heavy_check_mark: |
|
||||
|F.group_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.gumbel_softmax | |
|
||||
|F.hardshrink | :heavy_check_mark: |
|
||||
|F.hardsigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.hardswish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.hardtanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.hardtanh_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.instance_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.interpolate | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.layer_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.leaky_relu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.leaky_relu_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.linear | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.local_response_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.logsigmoid | :heavy_check_mark: |
|
||||
|F.log_softmax | :heavy_check_mark: |
|
||||
|F.lp_pool1d | :heavy_check_mark: |
|
||||
|F.lp_pool2d | :heavy_check_mark: |
|
||||
|F.max_pool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.max_pool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.max_pool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.max_unpool1d | |
|
||||
|F.max_unpool2d | |
|
||||
|F.max_unpool3d | |
|
||||
|F.mish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.normalize | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.one_hot | |
|
||||
|F.pad | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.pairwise_distance | |
|
||||
|F.pdist | |
|
||||
|F.pixel_shuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.pixel_unshuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.prelu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.relu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.relu_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.relu6 | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.rrelu | :heavy_check_mark: |
|
||||
|F.rrelu_ | :heavy_check_mark: |
|
||||
|F.selu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.sigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.silu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.softmax | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.softmin | :heavy_check_mark: |
|
||||
|F.softplus | :heavy_check_mark: |
|
||||
|F.softshrink | :heavy_check_mark: |
|
||||
|F.softsign | :heavy_check_mark: |
|
||||
|F.tanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.tanhshrink | :heavy_check_mark: |
|
||||
|F.threshold | :heavy_check_mark: |
|
||||
|F.threshold_ | :heavy_check_mark: |
|
||||
|F.unfold | |
|
||||
|F.upsample | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.upsample_bilinear | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.upsample_nearest | :heavy_check_mark: | :heavy_check_mark: |
|
||||
32
3rdparty/ncnn/tools/pnnx/cmake/PNNXPyTorch.cmake
vendored
Normal file
32
3rdparty/ncnn/tools/pnnx/cmake/PNNXPyTorch.cmake
vendored
Normal file
@@ -0,0 +1,32 @@
|
||||
# reference to https://github.com/llvm/torch-mlir/blob/main/python/torch_mlir/dialects/torch/importer/jit_ir/cmake/modules/TorchMLIRPyTorch.cmake
|
||||
|
||||
# PNNXProbeForPyTorchInstall
|
||||
# Attempts to find a Torch installation and set the Torch_ROOT variable
|
||||
# based on introspecting the python environment. This allows a subsequent
|
||||
# call to find_package(Torch) to work.
|
||||
function(PNNXProbeForPyTorchInstall)
|
||||
if(Torch_ROOT)
|
||||
message(STATUS "Using cached Torch root = ${Torch_ROOT}")
|
||||
elseif(Torch_INSTALL_DIR)
|
||||
message(STATUS "Using cached Torch install dir = ${Torch_INSTALL_DIR}")
|
||||
set(Torch_DIR "${Torch_INSTALL_DIR}/share/cmake/Torch" CACHE STRING "Torch dir" FORCE)
|
||||
else()
|
||||
#find_package (Python3 COMPONENTS Interpreter Development)
|
||||
find_package (Python3)
|
||||
message(STATUS "Checking for PyTorch using ${Python3_EXECUTABLE} ...")
|
||||
execute_process(
|
||||
COMMAND "${Python3_EXECUTABLE}"
|
||||
-c "import os;import torch;print(torch.utils.cmake_prefix_path, end='')"
|
||||
WORKING_DIRECTORY ${CMAKE_CURRENT_SOURCE_DIR}
|
||||
RESULT_VARIABLE PYTORCH_STATUS
|
||||
OUTPUT_VARIABLE PYTORCH_PACKAGE_DIR)
|
||||
if(NOT PYTORCH_STATUS EQUAL "0")
|
||||
message(STATUS "Unable to 'import torch' with ${Python3_EXECUTABLE} (fallback to explicit config)")
|
||||
return()
|
||||
endif()
|
||||
message(STATUS "Found PyTorch installation at ${PYTORCH_PACKAGE_DIR}")
|
||||
|
||||
set(Torch_ROOT "${PYTORCH_PACKAGE_DIR}" CACHE STRING
|
||||
"Torch configure directory" FORCE)
|
||||
endif()
|
||||
endfunction()
|
||||
488
3rdparty/ncnn/tools/pnnx/src/CMakeLists.txt
vendored
Normal file
488
3rdparty/ncnn/tools/pnnx/src/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,488 @@
|
||||
|
||||
include_directories(${CMAKE_CURRENT_SOURCE_DIR})
|
||||
|
||||
set(pnnx_pass_level0_SRCS
|
||||
pass_level0/constant_unpooling.cpp
|
||||
pass_level0/inline_block.cpp
|
||||
pass_level0/shape_inference.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level1_SRCS
|
||||
pass_level1/nn_AdaptiveAvgPool1d.cpp
|
||||
pass_level1/nn_AdaptiveAvgPool2d.cpp
|
||||
pass_level1/nn_AdaptiveAvgPool3d.cpp
|
||||
pass_level1/nn_AdaptiveMaxPool1d.cpp
|
||||
pass_level1/nn_AdaptiveMaxPool2d.cpp
|
||||
pass_level1/nn_AdaptiveMaxPool3d.cpp
|
||||
pass_level1/nn_AlphaDropout.cpp
|
||||
pass_level1/nn_AvgPool1d.cpp
|
||||
pass_level1/nn_AvgPool2d.cpp
|
||||
pass_level1/nn_AvgPool3d.cpp
|
||||
pass_level1/nn_BatchNorm1d.cpp
|
||||
pass_level1/nn_BatchNorm2d.cpp
|
||||
pass_level1/nn_BatchNorm3d.cpp
|
||||
pass_level1/nn_CELU.cpp
|
||||
pass_level1/nn_ChannelShuffle.cpp
|
||||
pass_level1/nn_ConstantPad1d.cpp
|
||||
pass_level1/nn_ConstantPad2d.cpp
|
||||
pass_level1/nn_ConstantPad3d.cpp
|
||||
pass_level1/nn_Conv1d.cpp
|
||||
pass_level1/nn_Conv2d.cpp
|
||||
pass_level1/nn_Conv3d.cpp
|
||||
pass_level1/nn_ConvTranspose1d.cpp
|
||||
pass_level1/nn_ConvTranspose2d.cpp
|
||||
pass_level1/nn_ConvTranspose3d.cpp
|
||||
pass_level1/nn_Dropout.cpp
|
||||
pass_level1/nn_Dropout2d.cpp
|
||||
pass_level1/nn_Dropout3d.cpp
|
||||
pass_level1/nn_ELU.cpp
|
||||
pass_level1/nn_Embedding.cpp
|
||||
pass_level1/nn_GELU.cpp
|
||||
pass_level1/nn_GroupNorm.cpp
|
||||
pass_level1/nn_GRU.cpp
|
||||
pass_level1/nn_Hardshrink.cpp
|
||||
pass_level1/nn_Hardsigmoid.cpp
|
||||
pass_level1/nn_Hardswish.cpp
|
||||
pass_level1/nn_Hardtanh.cpp
|
||||
pass_level1/nn_InstanceNorm1d.cpp
|
||||
pass_level1/nn_InstanceNorm2d.cpp
|
||||
pass_level1/nn_InstanceNorm3d.cpp
|
||||
pass_level1/nn_LayerNorm.cpp
|
||||
pass_level1/nn_LeakyReLU.cpp
|
||||
pass_level1/nn_Linear.cpp
|
||||
pass_level1/nn_LocalResponseNorm.cpp
|
||||
pass_level1/nn_LogSigmoid.cpp
|
||||
pass_level1/nn_LogSoftmax.cpp
|
||||
pass_level1/nn_LPPool1d.cpp
|
||||
pass_level1/nn_LPPool2d.cpp
|
||||
pass_level1/nn_LSTM.cpp
|
||||
pass_level1/nn_MaxPool1d.cpp
|
||||
pass_level1/nn_MaxPool2d.cpp
|
||||
pass_level1/nn_MaxPool3d.cpp
|
||||
#pass_level1/nn_maxunpool2d.cpp
|
||||
pass_level1/nn_Mish.cpp
|
||||
pass_level1/nn_MultiheadAttention.cpp
|
||||
pass_level1/nn_PixelShuffle.cpp
|
||||
pass_level1/nn_PixelUnshuffle.cpp
|
||||
pass_level1/nn_PReLU.cpp
|
||||
pass_level1/nn_ReflectionPad1d.cpp
|
||||
pass_level1/nn_ReflectionPad2d.cpp
|
||||
pass_level1/nn_ReLU.cpp
|
||||
pass_level1/nn_ReLU6.cpp
|
||||
pass_level1/nn_ReplicationPad1d.cpp
|
||||
pass_level1/nn_ReplicationPad2d.cpp
|
||||
pass_level1/nn_ReplicationPad3d.cpp
|
||||
pass_level1/nn_RNN.cpp
|
||||
pass_level1/nn_RReLU.cpp
|
||||
pass_level1/nn_SELU.cpp
|
||||
pass_level1/nn_Sigmoid.cpp
|
||||
pass_level1/nn_SiLU.cpp
|
||||
pass_level1/nn_Softmax.cpp
|
||||
pass_level1/nn_Softmin.cpp
|
||||
pass_level1/nn_Softplus.cpp
|
||||
pass_level1/nn_Softshrink.cpp
|
||||
pass_level1/nn_Softsign.cpp
|
||||
pass_level1/nn_Tanh.cpp
|
||||
pass_level1/nn_Tanhshrink.cpp
|
||||
pass_level1/nn_Threshold.cpp
|
||||
pass_level1/nn_Upsample.cpp
|
||||
pass_level1/nn_UpsamplingBilinear2d.cpp
|
||||
pass_level1/nn_UpsamplingNearest2d.cpp
|
||||
pass_level1/nn_ZeroPad2d.cpp
|
||||
|
||||
pass_level1/nn_quantized_Conv2d.cpp
|
||||
pass_level1/nn_quantized_DeQuantize.cpp
|
||||
pass_level1/nn_quantized_Linear.cpp
|
||||
pass_level1/nn_quantized_Quantize.cpp
|
||||
|
||||
pass_level1/torchvision_DeformConv2d.cpp
|
||||
pass_level1/torchvision_RoIAlign.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level2_SRCS
|
||||
pass_level2/F_adaptive_avg_pool1d.cpp
|
||||
pass_level2/F_adaptive_avg_pool2d.cpp
|
||||
pass_level2/F_adaptive_avg_pool3d.cpp
|
||||
pass_level2/F_adaptive_max_pool1d.cpp
|
||||
pass_level2/F_adaptive_max_pool2d.cpp
|
||||
pass_level2/F_adaptive_max_pool3d.cpp
|
||||
pass_level2/F_alpha_dropout.cpp
|
||||
pass_level2/F_affine_grid.cpp
|
||||
pass_level2/F_avg_pool1d.cpp
|
||||
pass_level2/F_avg_pool2d.cpp
|
||||
pass_level2/F_avg_pool3d.cpp
|
||||
pass_level2/F_batch_norm.cpp
|
||||
pass_level2/F_celu.cpp
|
||||
pass_level2/F_conv1d.cpp
|
||||
pass_level2/F_conv2d.cpp
|
||||
pass_level2/F_conv3d.cpp
|
||||
pass_level2/F_conv_transpose123d.cpp
|
||||
pass_level2/F_dropout.cpp
|
||||
pass_level2/F_dropout23d.cpp
|
||||
pass_level2/F_elu.cpp
|
||||
pass_level2/F_embedding.cpp
|
||||
pass_level2/F_feature_alpha_dropout.cpp
|
||||
pass_level2/F_gelu.cpp
|
||||
pass_level2/F_grid_sample.cpp
|
||||
pass_level2/F_group_norm.cpp
|
||||
pass_level2/F_hardshrink.cpp
|
||||
pass_level2/F_hardsigmoid.cpp
|
||||
pass_level2/F_hardswish.cpp
|
||||
pass_level2/F_hardtanh.cpp
|
||||
pass_level2/F_instance_norm.cpp
|
||||
pass_level2/F_interpolate.cpp
|
||||
pass_level2/F_layer_norm.cpp
|
||||
pass_level2/F_leaky_relu.cpp
|
||||
pass_level2/F_linear.cpp
|
||||
pass_level2/F_local_response_norm.cpp
|
||||
pass_level2/F_log_softmax.cpp
|
||||
pass_level2/F_logsigmoid.cpp
|
||||
pass_level2/F_lp_pool1d.cpp
|
||||
pass_level2/F_lp_pool2d.cpp
|
||||
pass_level2/F_max_pool1d.cpp
|
||||
pass_level2/F_max_pool2d.cpp
|
||||
pass_level2/F_max_pool3d.cpp
|
||||
pass_level2/F_mish.cpp
|
||||
pass_level2/F_normalize.cpp
|
||||
pass_level2/F_pad.cpp
|
||||
pass_level2/F_pixel_shuffle.cpp
|
||||
pass_level2/F_pixel_unshuffle.cpp
|
||||
pass_level2/F_prelu.cpp
|
||||
pass_level2/F_relu.cpp
|
||||
pass_level2/F_relu6.cpp
|
||||
pass_level2/F_rrelu.cpp
|
||||
pass_level2/F_selu.cpp
|
||||
pass_level2/F_sigmoid.cpp
|
||||
pass_level2/F_silu.cpp
|
||||
pass_level2/F_softmax.cpp
|
||||
pass_level2/F_softmin.cpp
|
||||
pass_level2/F_softplus.cpp
|
||||
pass_level2/F_softshrink.cpp
|
||||
pass_level2/F_softsign.cpp
|
||||
pass_level2/F_tanh.cpp
|
||||
pass_level2/F_tanhshrink.cpp
|
||||
pass_level2/F_threshold.cpp
|
||||
pass_level2/F_upsample_bilinear.cpp
|
||||
pass_level2/F_upsample_nearest.cpp
|
||||
pass_level2/F_upsample.cpp
|
||||
pass_level2/Tensor_contiguous.cpp
|
||||
pass_level2/Tensor_expand.cpp
|
||||
pass_level2/Tensor_expand_as.cpp
|
||||
pass_level2/Tensor_index.cpp
|
||||
pass_level2/Tensor_new_empty.cpp
|
||||
pass_level2/Tensor_repeat.cpp
|
||||
pass_level2/Tensor_reshape.cpp
|
||||
pass_level2/Tensor_select.cpp
|
||||
pass_level2/Tensor_slice.cpp
|
||||
pass_level2/Tensor_view.cpp
|
||||
pass_level2/torch_addmm.cpp
|
||||
pass_level2/torch_amax.cpp
|
||||
pass_level2/torch_amin.cpp
|
||||
pass_level2/torch_arange.cpp
|
||||
pass_level2/torch_argmax.cpp
|
||||
pass_level2/torch_argmin.cpp
|
||||
pass_level2/torch_cat.cpp
|
||||
pass_level2/torch_chunk.cpp
|
||||
pass_level2/torch_clamp.cpp
|
||||
pass_level2/torch_clone.cpp
|
||||
pass_level2/torch_dequantize.cpp
|
||||
pass_level2/torch_empty.cpp
|
||||
pass_level2/torch_empty_like.cpp
|
||||
pass_level2/torch_flatten.cpp
|
||||
pass_level2/torch_flip.cpp
|
||||
pass_level2/torch_full.cpp
|
||||
pass_level2/torch_full_like.cpp
|
||||
pass_level2/torch_logsumexp.cpp
|
||||
pass_level2/torch_matmul.cpp
|
||||
pass_level2/torch_mean.cpp
|
||||
pass_level2/torch_norm.cpp
|
||||
pass_level2/torch_normal.cpp
|
||||
pass_level2/torch_ones.cpp
|
||||
pass_level2/torch_ones_like.cpp
|
||||
pass_level2/torch_prod.cpp
|
||||
pass_level2/torch_quantize_per_tensor.cpp
|
||||
pass_level2/torch_randn.cpp
|
||||
pass_level2/torch_randn_like.cpp
|
||||
pass_level2/torch_roll.cpp
|
||||
pass_level2/torch_split.cpp
|
||||
pass_level2/torch_squeeze.cpp
|
||||
pass_level2/torch_stack.cpp
|
||||
pass_level2/torch_sum.cpp
|
||||
pass_level2/torch_permute.cpp
|
||||
pass_level2/torch_transpose.cpp
|
||||
pass_level2/torch_unbind.cpp
|
||||
pass_level2/torch_unsqueeze.cpp
|
||||
pass_level2/torch_var.cpp
|
||||
pass_level2/torch_zeros.cpp
|
||||
pass_level2/torch_zeros_like.cpp
|
||||
|
||||
pass_level2/nn_quantized_FloatFunctional.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level3_SRCS
|
||||
pass_level3/assign_unique_name.cpp
|
||||
pass_level3/eliminate_noop_math.cpp
|
||||
pass_level3/eliminate_tuple_pair.cpp
|
||||
pass_level3/expand_quantization_modules.cpp
|
||||
pass_level3/fuse_cat_stack_tensors.cpp
|
||||
pass_level3/fuse_chunk_split_unbind_unpack.cpp
|
||||
pass_level3/fuse_expression.cpp
|
||||
pass_level3/fuse_index_expression.cpp
|
||||
pass_level3/fuse_rnn_unpack.cpp
|
||||
pass_level3/rename_F_conv_transposend.cpp
|
||||
pass_level3/rename_F_convmode.cpp
|
||||
pass_level3/rename_F_dropoutnd.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level4_SRCS
|
||||
pass_level4/canonicalize.cpp
|
||||
pass_level4/dead_code_elimination.cpp
|
||||
pass_level4/fuse_custom_op.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level5_SRCS
|
||||
pass_level5/eliminate_dropout.cpp
|
||||
pass_level5/eliminate_identity_operator.cpp
|
||||
pass_level5/eliminate_maxpool_indices.cpp
|
||||
pass_level5/eliminate_noop_expression.cpp
|
||||
pass_level5/eliminate_noop_pad.cpp
|
||||
pass_level5/eliminate_slice.cpp
|
||||
pass_level5/eliminate_view_reshape.cpp
|
||||
pass_level5/eval_expression.cpp
|
||||
pass_level5/fold_constants.cpp
|
||||
pass_level5/fuse_channel_shuffle.cpp
|
||||
pass_level5/fuse_constant_expression.cpp
|
||||
pass_level5/fuse_conv1d_batchnorm1d.cpp
|
||||
pass_level5/fuse_conv2d_batchnorm2d.cpp
|
||||
pass_level5/fuse_convtranspose1d_batchnorm1d.cpp
|
||||
pass_level5/fuse_convtranspose2d_batchnorm2d.cpp
|
||||
pass_level5/fuse_contiguous_view.cpp
|
||||
pass_level5/fuse_linear_batchnorm1d.cpp
|
||||
pass_level5/fuse_select_to_unbind.cpp
|
||||
pass_level5/fuse_slice_indices.cpp
|
||||
pass_level5/unroll_rnn_op.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_ncnn_SRCS
|
||||
pass_ncnn/convert_attribute.cpp
|
||||
pass_ncnn/convert_custom_op.cpp
|
||||
pass_ncnn/convert_half_to_float.cpp
|
||||
pass_ncnn/convert_input.cpp
|
||||
pass_ncnn/convert_torch_cat.cpp
|
||||
pass_ncnn/convert_torch_chunk.cpp
|
||||
pass_ncnn/convert_torch_split.cpp
|
||||
pass_ncnn/convert_torch_unbind.cpp
|
||||
pass_ncnn/eliminate_output.cpp
|
||||
pass_ncnn/expand_expression.cpp
|
||||
pass_ncnn/insert_split.cpp
|
||||
pass_ncnn/chain_multi_output.cpp
|
||||
pass_ncnn/solve_batch_index.cpp
|
||||
|
||||
pass_ncnn/eliminate_noop.cpp
|
||||
pass_ncnn/eliminate_tail_reshape_permute.cpp
|
||||
pass_ncnn/fuse_convolution_activation.cpp
|
||||
pass_ncnn/fuse_convolution1d_activation.cpp
|
||||
pass_ncnn/fuse_convolutiondepthwise_activation.cpp
|
||||
pass_ncnn/fuse_convolutiondepthwise1d_activation.cpp
|
||||
pass_ncnn/fuse_deconvolution_activation.cpp
|
||||
pass_ncnn/fuse_deconvolutiondepthwise_activation.cpp
|
||||
pass_ncnn/fuse_innerproduct_activation.cpp
|
||||
pass_ncnn/fuse_transpose_matmul.cpp
|
||||
pass_ncnn/insert_reshape_pooling.cpp
|
||||
|
||||
pass_ncnn/F_adaptive_avg_pool1d.cpp
|
||||
pass_ncnn/F_adaptive_avg_pool2d.cpp
|
||||
pass_ncnn/F_adaptive_avg_pool3d.cpp
|
||||
pass_ncnn/F_adaptive_max_pool1d.cpp
|
||||
pass_ncnn/F_adaptive_max_pool2d.cpp
|
||||
pass_ncnn/F_adaptive_max_pool3d.cpp
|
||||
pass_ncnn/F_avg_pool1d.cpp
|
||||
pass_ncnn/F_avg_pool2d.cpp
|
||||
pass_ncnn/F_avg_pool3d.cpp
|
||||
pass_ncnn/F_batch_norm.cpp
|
||||
pass_ncnn/F_conv_transpose1d.cpp
|
||||
pass_ncnn/F_conv_transpose2d.cpp
|
||||
pass_ncnn/F_conv_transpose3d.cpp
|
||||
pass_ncnn/F_conv1d.cpp
|
||||
pass_ncnn/F_conv2d.cpp
|
||||
pass_ncnn/F_conv3d.cpp
|
||||
pass_ncnn/F_elu.cpp
|
||||
pass_ncnn/F_embedding.cpp
|
||||
pass_ncnn/F_gelu.cpp
|
||||
pass_ncnn/F_group_norm.cpp
|
||||
pass_ncnn/F_hardsigmoid.cpp
|
||||
pass_ncnn/F_hardswish.cpp
|
||||
pass_ncnn/F_hardtanh.cpp
|
||||
pass_ncnn/F_instance_norm.cpp
|
||||
pass_ncnn/F_interpolate.cpp
|
||||
pass_ncnn/F_layer_norm.cpp
|
||||
pass_ncnn/F_leaky_relu.cpp
|
||||
pass_ncnn/F_linear.cpp
|
||||
pass_ncnn/F_local_response_norm.cpp
|
||||
pass_ncnn/F_max_pool1d.cpp
|
||||
pass_ncnn/F_max_pool2d.cpp
|
||||
pass_ncnn/F_max_pool3d.cpp
|
||||
pass_ncnn/F_mish.cpp
|
||||
pass_ncnn/F_normalize.cpp
|
||||
pass_ncnn/F_pad.cpp
|
||||
pass_ncnn/F_pixel_shuffle.cpp
|
||||
pass_ncnn/F_pixel_unshuffle.cpp
|
||||
pass_ncnn/F_prelu.cpp
|
||||
pass_ncnn/F_relu.cpp
|
||||
pass_ncnn/F_relu6.cpp
|
||||
pass_ncnn/F_selu.cpp
|
||||
pass_ncnn/F_sigmoid.cpp
|
||||
pass_ncnn/F_silu.cpp
|
||||
pass_ncnn/F_softmax.cpp
|
||||
pass_ncnn/F_tanh.cpp
|
||||
pass_ncnn/F_upsample_bilinear.cpp
|
||||
pass_ncnn/F_upsample_nearest.cpp
|
||||
pass_ncnn/F_upsample.cpp
|
||||
pass_ncnn/nn_AdaptiveAvgPool1d.cpp
|
||||
pass_ncnn/nn_AdaptiveAvgPool2d.cpp
|
||||
pass_ncnn/nn_AdaptiveAvgPool3d.cpp
|
||||
pass_ncnn/nn_AdaptiveMaxPool1d.cpp
|
||||
pass_ncnn/nn_AdaptiveMaxPool2d.cpp
|
||||
pass_ncnn/nn_AdaptiveMaxPool3d.cpp
|
||||
pass_ncnn/nn_AvgPool1d.cpp
|
||||
pass_ncnn/nn_AvgPool2d.cpp
|
||||
pass_ncnn/nn_AvgPool3d.cpp
|
||||
pass_ncnn/nn_BatchNorm1d.cpp
|
||||
pass_ncnn/nn_BatchNorm2d.cpp
|
||||
pass_ncnn/nn_BatchNorm3d.cpp
|
||||
pass_ncnn/nn_ChannelShuffle.cpp
|
||||
pass_ncnn/nn_ConstantPad1d.cpp
|
||||
pass_ncnn/nn_ConstantPad2d.cpp
|
||||
pass_ncnn/nn_ConstantPad3d.cpp
|
||||
pass_ncnn/nn_Conv1d.cpp
|
||||
pass_ncnn/nn_Conv2d.cpp
|
||||
pass_ncnn/nn_Conv3d.cpp
|
||||
pass_ncnn/nn_ConvTranspose1d.cpp
|
||||
pass_ncnn/nn_ConvTranspose2d.cpp
|
||||
pass_ncnn/nn_ConvTranspose3d.cpp
|
||||
pass_ncnn/nn_ELU.cpp
|
||||
pass_ncnn/nn_Embedding.cpp
|
||||
pass_ncnn/nn_GELU.cpp
|
||||
pass_ncnn/nn_GroupNorm.cpp
|
||||
pass_ncnn/nn_GRU.cpp
|
||||
pass_ncnn/nn_Hardsigmoid.cpp
|
||||
pass_ncnn/nn_Hardswish.cpp
|
||||
pass_ncnn/nn_Hardtanh.cpp
|
||||
pass_ncnn/nn_InstanceNorm2d.cpp
|
||||
pass_ncnn/nn_LayerNorm.cpp
|
||||
pass_ncnn/nn_LeakyReLU.cpp
|
||||
pass_ncnn/nn_Linear.cpp
|
||||
pass_ncnn/nn_LocalResponseNorm.cpp
|
||||
pass_ncnn/nn_LSTM.cpp
|
||||
pass_ncnn/nn_MaxPool1d.cpp
|
||||
pass_ncnn/nn_MaxPool2d.cpp
|
||||
pass_ncnn/nn_MaxPool3d.cpp
|
||||
pass_ncnn/nn_Mish.cpp
|
||||
pass_ncnn/nn_MultiheadAttention.cpp
|
||||
pass_ncnn/nn_PixelShuffle.cpp
|
||||
pass_ncnn/nn_PixelUnshuffle.cpp
|
||||
pass_ncnn/nn_PReLU.cpp
|
||||
pass_ncnn/nn_ReflectionPad1d.cpp
|
||||
pass_ncnn/nn_ReflectionPad2d.cpp
|
||||
pass_ncnn/nn_ReLU.cpp
|
||||
pass_ncnn/nn_ReLU6.cpp
|
||||
pass_ncnn/nn_ReplicationPad1d.cpp
|
||||
pass_ncnn/nn_ReplicationPad2d.cpp
|
||||
pass_ncnn/nn_RNN.cpp
|
||||
pass_ncnn/nn_SELU.cpp
|
||||
pass_ncnn/nn_Sigmoid.cpp
|
||||
pass_ncnn/nn_SiLU.cpp
|
||||
pass_ncnn/nn_Softmax.cpp
|
||||
pass_ncnn/nn_Tanh.cpp
|
||||
pass_ncnn/nn_Upsample.cpp
|
||||
pass_ncnn/nn_UpsamplingBilinear2d.cpp
|
||||
pass_ncnn/nn_UpsamplingNearest2d.cpp
|
||||
pass_ncnn/nn_ZeroPad2d.cpp
|
||||
pass_ncnn/Tensor_contiguous.cpp
|
||||
pass_ncnn/Tensor_reshape.cpp
|
||||
pass_ncnn/Tensor_repeat.cpp
|
||||
pass_ncnn/Tensor_slice.cpp
|
||||
pass_ncnn/Tensor_view.cpp
|
||||
pass_ncnn/torch_addmm.cpp
|
||||
pass_ncnn/torch_amax.cpp
|
||||
pass_ncnn/torch_amin.cpp
|
||||
pass_ncnn/torch_clamp.cpp
|
||||
pass_ncnn/torch_clone.cpp
|
||||
pass_ncnn/torch_flatten.cpp
|
||||
pass_ncnn/torch_logsumexp.cpp
|
||||
pass_ncnn/torch_matmul.cpp
|
||||
pass_ncnn/torch_mean.cpp
|
||||
pass_ncnn/torch_permute.cpp
|
||||
pass_ncnn/torch_prod.cpp
|
||||
pass_ncnn/torch_squeeze.cpp
|
||||
pass_ncnn/torch_sum.cpp
|
||||
pass_ncnn/torch_transpose.cpp
|
||||
pass_ncnn/torch_unsqueeze.cpp
|
||||
)
|
||||
|
||||
set(pnnx_SRCS
|
||||
main.cpp
|
||||
ir.cpp
|
||||
storezip.cpp
|
||||
utils.cpp
|
||||
|
||||
pass_level0.cpp
|
||||
pass_level1.cpp
|
||||
pass_level2.cpp
|
||||
pass_level3.cpp
|
||||
pass_level4.cpp
|
||||
pass_level5.cpp
|
||||
|
||||
pass_ncnn.cpp
|
||||
|
||||
${pnnx_pass_level0_SRCS}
|
||||
${pnnx_pass_level1_SRCS}
|
||||
${pnnx_pass_level2_SRCS}
|
||||
${pnnx_pass_level3_SRCS}
|
||||
${pnnx_pass_level4_SRCS}
|
||||
${pnnx_pass_level5_SRCS}
|
||||
|
||||
${pnnx_pass_ncnn_SRCS}
|
||||
)
|
||||
|
||||
if(NOT MSVC)
|
||||
add_definitions(-Wall -Wextra)
|
||||
endif()
|
||||
|
||||
add_executable(pnnx ${pnnx_SRCS})
|
||||
|
||||
if(PNNX_COVERAGE)
|
||||
target_compile_options(pnnx PUBLIC -coverage -fprofile-arcs -ftest-coverage)
|
||||
target_link_libraries(pnnx PUBLIC -coverage -lgcov)
|
||||
endif()
|
||||
|
||||
if(WIN32)
|
||||
target_compile_definitions(pnnx PUBLIC NOMINMAX)
|
||||
endif()
|
||||
|
||||
if(TorchVision_FOUND)
|
||||
target_link_libraries(pnnx PRIVATE TorchVision::TorchVision)
|
||||
endif()
|
||||
|
||||
if(WIN32)
|
||||
target_link_libraries(pnnx PRIVATE ${TORCH_LIBRARIES})
|
||||
else()
|
||||
target_link_libraries(pnnx PRIVATE ${TORCH_LIBRARIES} pthread dl)
|
||||
endif()
|
||||
|
||||
#set_target_properties(pnnx PROPERTIES COMPILE_FLAGS -fsanitize=address)
|
||||
#set_target_properties(pnnx PROPERTIES LINK_FLAGS -fsanitize=address)
|
||||
|
||||
if(APPLE)
|
||||
set_target_properties(pnnx PROPERTIES INSTALL_RPATH "@executable_path/")
|
||||
else()
|
||||
set_target_properties(pnnx PROPERTIES INSTALL_RPATH "$ORIGIN/")
|
||||
endif()
|
||||
set_target_properties(pnnx PROPERTIES MACOSX_RPATH TRUE)
|
||||
|
||||
install(TARGETS pnnx RUNTIME DESTINATION bin)
|
||||
|
||||
if (WIN32)
|
||||
file(GLOB TORCH_DLL "${TORCH_INSTALL_PREFIX}/lib/*.dll")
|
||||
install(FILES ${TORCH_DLL} DESTINATION bin)
|
||||
endif()
|
||||
2597
3rdparty/ncnn/tools/pnnx/src/ir.cpp
vendored
Normal file
2597
3rdparty/ncnn/tools/pnnx/src/ir.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
242
3rdparty/ncnn/tools/pnnx/src/ir.h
vendored
Normal file
242
3rdparty/ncnn/tools/pnnx/src/ir.h
vendored
Normal file
@@ -0,0 +1,242 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef PNNX_IR_H
|
||||
#define PNNX_IR_H
|
||||
|
||||
#include <initializer_list>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
namespace torch {
|
||||
namespace jit {
|
||||
struct Value;
|
||||
struct Node;
|
||||
} // namespace jit
|
||||
} // namespace torch
|
||||
namespace at {
|
||||
class Tensor;
|
||||
}
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Parameter
|
||||
{
|
||||
public:
|
||||
Parameter()
|
||||
: type(0)
|
||||
{
|
||||
}
|
||||
Parameter(bool _b)
|
||||
: type(1), b(_b)
|
||||
{
|
||||
}
|
||||
Parameter(int _i)
|
||||
: type(2), i(_i)
|
||||
{
|
||||
}
|
||||
Parameter(long _l)
|
||||
: type(2), i(_l)
|
||||
{
|
||||
}
|
||||
Parameter(long long _l)
|
||||
: type(2), i(_l)
|
||||
{
|
||||
}
|
||||
Parameter(float _f)
|
||||
: type(3), f(_f)
|
||||
{
|
||||
}
|
||||
Parameter(double _d)
|
||||
: type(3), f(_d)
|
||||
{
|
||||
}
|
||||
Parameter(const char* _s)
|
||||
: type(4), s(_s)
|
||||
{
|
||||
}
|
||||
Parameter(const std::string& _s)
|
||||
: type(4), s(_s)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<int>& _ai)
|
||||
: type(5), ai(_ai)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<int64_t>& _ai)
|
||||
: type(5)
|
||||
{
|
||||
for (const auto& x : _ai)
|
||||
ai.push_back((int)x);
|
||||
}
|
||||
Parameter(const std::vector<int>& _ai)
|
||||
: type(5), ai(_ai)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<float>& _af)
|
||||
: type(6), af(_af)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<double>& _af)
|
||||
: type(6)
|
||||
{
|
||||
for (const auto& x : _af)
|
||||
af.push_back((float)x);
|
||||
}
|
||||
Parameter(const std::vector<float>& _af)
|
||||
: type(6), af(_af)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<const char*>& _as)
|
||||
: type(7)
|
||||
{
|
||||
for (const auto& x : _as)
|
||||
as.push_back(std::string(x));
|
||||
}
|
||||
Parameter(const std::initializer_list<std::string>& _as)
|
||||
: type(7), as(_as)
|
||||
{
|
||||
}
|
||||
Parameter(const std::vector<std::string>& _as)
|
||||
: type(7), as(_as)
|
||||
{
|
||||
}
|
||||
|
||||
Parameter(const torch::jit::Node* value_node);
|
||||
Parameter(const torch::jit::Value* value);
|
||||
|
||||
static Parameter parse_from_string(const std::string& value);
|
||||
|
||||
// 0=null 1=b 2=i 3=f 4=s 5=ai 6=af 7=as 8=others
|
||||
int type;
|
||||
|
||||
// value
|
||||
bool b;
|
||||
int i;
|
||||
float f;
|
||||
std::string s;
|
||||
std::vector<int> ai;
|
||||
std::vector<float> af;
|
||||
std::vector<std::string> as;
|
||||
};
|
||||
|
||||
bool operator==(const Parameter& lhs, const Parameter& rhs);
|
||||
|
||||
class Attribute
|
||||
{
|
||||
public:
|
||||
Attribute()
|
||||
: type(0)
|
||||
{
|
||||
}
|
||||
|
||||
Attribute(const at::Tensor& t);
|
||||
|
||||
Attribute(const std::initializer_list<int>& shape, const std::vector<float>& t);
|
||||
|
||||
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8 9=bool
|
||||
int type;
|
||||
std::vector<int> shape;
|
||||
|
||||
std::vector<char> data;
|
||||
};
|
||||
|
||||
bool operator==(const Attribute& lhs, const Attribute& rhs);
|
||||
|
||||
// concat two attributes along the first axis
|
||||
Attribute operator+(const Attribute& a, const Attribute& b);
|
||||
|
||||
class Operator;
|
||||
class Operand
|
||||
{
|
||||
public:
|
||||
void remove_consumer(const Operator* c);
|
||||
|
||||
std::string name;
|
||||
|
||||
Operator* producer;
|
||||
std::vector<Operator*> consumers;
|
||||
|
||||
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8
|
||||
int type;
|
||||
std::vector<int> shape;
|
||||
|
||||
std::map<std::string, Parameter> params;
|
||||
|
||||
private:
|
||||
friend class Graph;
|
||||
Operand()
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
class Operator
|
||||
{
|
||||
public:
|
||||
std::string type;
|
||||
std::string name;
|
||||
|
||||
std::vector<Operand*> inputs;
|
||||
std::vector<Operand*> outputs;
|
||||
|
||||
std::vector<std::string> inputnames;
|
||||
std::map<std::string, Parameter> params;
|
||||
std::map<std::string, Attribute> attrs;
|
||||
|
||||
private:
|
||||
friend class Graph;
|
||||
Operator()
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
class Graph
|
||||
{
|
||||
public:
|
||||
Graph();
|
||||
~Graph();
|
||||
|
||||
int load(const std::string& parampath, const std::string& binpath);
|
||||
int save(const std::string& parampath, const std::string& binpath);
|
||||
|
||||
int python(const std::string& pypath, const std::string& binpath);
|
||||
|
||||
int ncnn(const std::string& parampath, const std::string& binpath, const std::string& pypath);
|
||||
|
||||
int parse(const std::string& param);
|
||||
|
||||
Operator* new_operator(const std::string& type, const std::string& name);
|
||||
|
||||
Operator* new_operator_before(const std::string& type, const std::string& name, const Operator* cur);
|
||||
|
||||
Operator* new_operator_after(const std::string& type, const std::string& name, const Operator* cur);
|
||||
|
||||
Operand* new_operand(const torch::jit::Value* v);
|
||||
|
||||
Operand* new_operand(const std::string& name);
|
||||
|
||||
Operand* get_operand(const std::string& name);
|
||||
|
||||
std::vector<Operator*> ops;
|
||||
std::vector<Operand*> operands;
|
||||
|
||||
private:
|
||||
Graph(const Graph& rhs);
|
||||
Graph& operator=(const Graph& rhs);
|
||||
};
|
||||
|
||||
} // namespace pnnx
|
||||
|
||||
#endif // PNNX_IR_H
|
||||
396
3rdparty/ncnn/tools/pnnx/src/main.cpp
vendored
Normal file
396
3rdparty/ncnn/tools/pnnx/src/main.cpp
vendored
Normal file
@@ -0,0 +1,396 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <stdio.h>
|
||||
|
||||
#if _WIN32
|
||||
#include <windows.h>
|
||||
#else
|
||||
#include <dlfcn.h>
|
||||
#endif
|
||||
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
#include <torch/script.h>
|
||||
|
||||
#ifdef PNNX_TORCHVISION
|
||||
// register torchvision ops via including headers
|
||||
#include <torchvision/vision.h>
|
||||
#endif
|
||||
|
||||
#include "ir.h"
|
||||
#include "pass_level0.h"
|
||||
#include "pass_level1.h"
|
||||
#include "pass_level2.h"
|
||||
#include "pass_level3.h"
|
||||
#include "pass_level4.h"
|
||||
#include "pass_level5.h"
|
||||
|
||||
#include "pass_ncnn.h"
|
||||
|
||||
static std::string get_basename(const std::string& path)
|
||||
{
|
||||
return path.substr(0, path.find_last_of('.'));
|
||||
}
|
||||
|
||||
static void parse_string_list(char* s, std::vector<std::string>& list)
|
||||
{
|
||||
list.clear();
|
||||
|
||||
char* pch = strtok(s, ",");
|
||||
while (pch != NULL)
|
||||
{
|
||||
list.push_back(std::string(pch));
|
||||
|
||||
pch = strtok(NULL, ",");
|
||||
}
|
||||
}
|
||||
|
||||
static void print_string_list(const std::vector<std::string>& list)
|
||||
{
|
||||
for (size_t i = 0; i < list.size(); i++)
|
||||
{
|
||||
fprintf(stderr, "%s", list[i].c_str());
|
||||
if (i + 1 != list.size())
|
||||
fprintf(stderr, ",");
|
||||
}
|
||||
}
|
||||
|
||||
static void parse_shape_list(char* s, std::vector<std::vector<int64_t> >& shapes, std::vector<std::string>& types)
|
||||
{
|
||||
shapes.clear();
|
||||
types.clear();
|
||||
|
||||
char* pch = strtok(s, "[]");
|
||||
while (pch != NULL)
|
||||
{
|
||||
// assign user data type
|
||||
if (!types.empty() && (pch[0] == 'f' || pch[0] == 'i' || pch[0] == 'u'))
|
||||
{
|
||||
char type[32];
|
||||
int nscan = sscanf(pch, "%31[^,]", type);
|
||||
if (nscan == 1)
|
||||
{
|
||||
types[types.size() - 1] = std::string(type);
|
||||
}
|
||||
}
|
||||
|
||||
// parse a,b,c
|
||||
int v;
|
||||
int nconsumed = 0;
|
||||
int nscan = sscanf(pch, "%d%n", &v, &nconsumed);
|
||||
if (nscan == 1)
|
||||
{
|
||||
// ok we get shape
|
||||
pch += nconsumed;
|
||||
|
||||
std::vector<int64_t> s;
|
||||
s.push_back(v);
|
||||
|
||||
nscan = sscanf(pch, ",%d%n", &v, &nconsumed);
|
||||
while (nscan == 1)
|
||||
{
|
||||
pch += nconsumed;
|
||||
|
||||
s.push_back(v);
|
||||
|
||||
nscan = sscanf(pch, ",%d%n", &v, &nconsumed);
|
||||
}
|
||||
|
||||
// shape end
|
||||
shapes.push_back(s);
|
||||
types.push_back("f32");
|
||||
}
|
||||
|
||||
pch = strtok(NULL, "[]");
|
||||
}
|
||||
}
|
||||
|
||||
static void print_shape_list(const std::vector<std::vector<int64_t> >& shapes, const std::vector<std::string>& types)
|
||||
{
|
||||
for (size_t i = 0; i < shapes.size(); i++)
|
||||
{
|
||||
const std::vector<int64_t>& s = shapes[i];
|
||||
const std::string& t = types[i];
|
||||
fprintf(stderr, "[");
|
||||
for (size_t j = 0; j < s.size(); j++)
|
||||
{
|
||||
fprintf(stderr, "%ld", s[j]);
|
||||
if (j != s.size() - 1)
|
||||
fprintf(stderr, ",");
|
||||
}
|
||||
fprintf(stderr, "]");
|
||||
fprintf(stderr, "%s", t.c_str());
|
||||
if (i != shapes.size() - 1)
|
||||
fprintf(stderr, ",");
|
||||
}
|
||||
}
|
||||
|
||||
static c10::ScalarType input_type_to_c10_ScalarType(const std::string& t)
|
||||
{
|
||||
if (t == "f32") return torch::kFloat32;
|
||||
if (t == "f16") return torch::kFloat16;
|
||||
if (t == "f64") return torch::kFloat64;
|
||||
if (t == "i32") return torch::kInt32;
|
||||
if (t == "i16") return torch::kInt16;
|
||||
if (t == "i64") return torch::kInt64;
|
||||
if (t == "i8") return torch::kInt8;
|
||||
if (t == "u8") return torch::kUInt8;
|
||||
|
||||
fprintf(stderr, "unsupported type %s fallback to f32\n", t.c_str());
|
||||
return torch::kFloat32;
|
||||
}
|
||||
|
||||
static void show_usage()
|
||||
{
|
||||
fprintf(stderr, "Usage: pnnx [model.pt] [(key=value)...]\n");
|
||||
fprintf(stderr, " pnnxparam=model.pnnx.param\n");
|
||||
fprintf(stderr, " pnnxbin=model.pnnx.bin\n");
|
||||
fprintf(stderr, " pnnxpy=model_pnnx.py\n");
|
||||
fprintf(stderr, " ncnnparam=model.ncnn.param\n");
|
||||
fprintf(stderr, " ncnnbin=model.ncnn.bin\n");
|
||||
fprintf(stderr, " ncnnpy=model_ncnn.py\n");
|
||||
fprintf(stderr, " optlevel=2\n");
|
||||
fprintf(stderr, " device=cpu/gpu\n");
|
||||
fprintf(stderr, " inputshape=[1,3,224,224],...\n");
|
||||
fprintf(stderr, " inputshape2=[1,3,320,320],...\n");
|
||||
#if _WIN32
|
||||
fprintf(stderr, " customop=C:\\Users\\nihui\\AppData\\Local\\torch_extensions\\torch_extensions\\Cache\\fused\\fused.dll,...\n");
|
||||
#else
|
||||
fprintf(stderr, " customop=/home/nihui/.cache/torch_extensions/fused/fused.so,...\n");
|
||||
#endif
|
||||
fprintf(stderr, " moduleop=models.common.Focus,models.yolo.Detect,...\n");
|
||||
fprintf(stderr, "Sample usage: pnnx mobilenet_v2.pt inputshape=[1,3,224,224]\n");
|
||||
fprintf(stderr, " pnnx yolov5s.pt inputshape=[1,3,640,640]f32 inputshape2=[1,3,320,320]f32 device=gpu moduleop=models.common.Focus,models.yolo.Detect\n");
|
||||
}
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
if (argc < 2)
|
||||
{
|
||||
show_usage();
|
||||
return -1;
|
||||
}
|
||||
|
||||
for (int i = 1; i < argc; i++)
|
||||
{
|
||||
if (argv[i][0] == '-')
|
||||
{
|
||||
show_usage();
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
std::string ptpath = std::string(argv[1]);
|
||||
|
||||
std::string ptbase = get_basename(ptpath);
|
||||
|
||||
std::string pnnxparampath = ptbase + ".pnnx.param";
|
||||
std::string pnnxbinpath = ptbase + ".pnnx.bin";
|
||||
std::string pnnxpypath = ptbase + "_pnnx.py";
|
||||
std::string ncnnparampath = ptbase + ".ncnn.param";
|
||||
std::string ncnnbinpath = ptbase + ".ncnn.bin";
|
||||
std::string ncnnpypath = ptbase + "_ncnn.py";
|
||||
int optlevel = 2;
|
||||
std::string device = "cpu";
|
||||
std::vector<std::vector<int64_t> > input_shapes;
|
||||
std::vector<std::string> input_types;
|
||||
std::vector<std::vector<int64_t> > input_shapes2;
|
||||
std::vector<std::string> input_types2;
|
||||
std::vector<std::string> customop_modules;
|
||||
std::vector<std::string> module_operators;
|
||||
|
||||
for (int i = 2; i < argc; i++)
|
||||
{
|
||||
// key=value
|
||||
char* kv = argv[i];
|
||||
|
||||
char* eqs = strchr(kv, '=');
|
||||
if (eqs == NULL)
|
||||
{
|
||||
fprintf(stderr, "unrecognized arg %s\n", kv);
|
||||
continue;
|
||||
}
|
||||
|
||||
// split k v
|
||||
eqs[0] = '\0';
|
||||
const char* key = kv;
|
||||
char* value = eqs + 1;
|
||||
|
||||
if (strcmp(key, "pnnxparam") == 0)
|
||||
pnnxparampath = std::string(value);
|
||||
if (strcmp(key, "pnnxbin") == 0)
|
||||
pnnxbinpath = std::string(value);
|
||||
if (strcmp(key, "pnnxpy") == 0)
|
||||
pnnxpypath = std::string(value);
|
||||
if (strcmp(key, "ncnnparam") == 0)
|
||||
ncnnparampath = std::string(value);
|
||||
if (strcmp(key, "ncnnbin") == 0)
|
||||
ncnnbinpath = std::string(value);
|
||||
if (strcmp(key, "ncnnpy") == 0)
|
||||
ncnnpypath = std::string(value);
|
||||
if (strcmp(key, "optlevel") == 0)
|
||||
optlevel = atoi(value);
|
||||
if (strcmp(key, "device") == 0)
|
||||
device = value;
|
||||
if (strcmp(key, "inputshape") == 0)
|
||||
parse_shape_list(value, input_shapes, input_types);
|
||||
if (strcmp(key, "inputshape2") == 0)
|
||||
parse_shape_list(value, input_shapes2, input_types2);
|
||||
if (strcmp(key, "customop") == 0)
|
||||
parse_string_list(value, customop_modules);
|
||||
if (strcmp(key, "moduleop") == 0)
|
||||
parse_string_list(value, module_operators);
|
||||
}
|
||||
|
||||
// print options
|
||||
{
|
||||
fprintf(stderr, "pnnxparam = %s\n", pnnxparampath.c_str());
|
||||
fprintf(stderr, "pnnxbin = %s\n", pnnxbinpath.c_str());
|
||||
fprintf(stderr, "pnnxpy = %s\n", pnnxpypath.c_str());
|
||||
fprintf(stderr, "ncnnparam = %s\n", ncnnparampath.c_str());
|
||||
fprintf(stderr, "ncnnbin = %s\n", ncnnbinpath.c_str());
|
||||
fprintf(stderr, "ncnnpy = %s\n", ncnnpypath.c_str());
|
||||
fprintf(stderr, "optlevel = %d\n", optlevel);
|
||||
fprintf(stderr, "device = %s\n", device.c_str());
|
||||
fprintf(stderr, "inputshape = ");
|
||||
print_shape_list(input_shapes, input_types);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "inputshape2 = ");
|
||||
print_shape_list(input_shapes2, input_types2);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "customop = ");
|
||||
print_string_list(customop_modules);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "moduleop = ");
|
||||
print_string_list(module_operators);
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
for (auto m : customop_modules)
|
||||
{
|
||||
fprintf(stderr, "load custom module %s\n", m.c_str());
|
||||
#if _WIN32
|
||||
HMODULE handle = LoadLibraryExA(m.c_str(), NULL, LOAD_WITH_ALTERED_SEARCH_PATH);
|
||||
if (!handle)
|
||||
{
|
||||
fprintf(stderr, "LoadLibraryExA %s failed %s\n", m.c_str(), GetLastError());
|
||||
}
|
||||
#else
|
||||
void* handle = dlopen(m.c_str(), RTLD_LAZY);
|
||||
if (!handle)
|
||||
{
|
||||
fprintf(stderr, "dlopen %s failed %s\n", m.c_str(), dlerror());
|
||||
}
|
||||
#endif
|
||||
}
|
||||
|
||||
std::vector<at::Tensor> input_tensors;
|
||||
for (size_t i = 0; i < input_shapes.size(); i++)
|
||||
{
|
||||
const std::vector<int64_t>& shape = input_shapes[i];
|
||||
const std::string& type = input_types[i];
|
||||
|
||||
at::Tensor t = torch::ones(shape, input_type_to_c10_ScalarType(type));
|
||||
if (device == "gpu")
|
||||
t = t.cuda();
|
||||
|
||||
input_tensors.push_back(t);
|
||||
}
|
||||
|
||||
std::vector<at::Tensor> input_tensors2;
|
||||
for (size_t i = 0; i < input_shapes2.size(); i++)
|
||||
{
|
||||
const std::vector<int64_t>& shape = input_shapes2[i];
|
||||
const std::string& type = input_types2[i];
|
||||
|
||||
at::Tensor t = torch::ones(shape, input_type_to_c10_ScalarType(type));
|
||||
if (device == "gpu")
|
||||
t = t.cuda();
|
||||
|
||||
input_tensors2.push_back(t);
|
||||
}
|
||||
|
||||
torch::jit::Module mod = torch::jit::load(ptpath);
|
||||
|
||||
mod.eval();
|
||||
|
||||
// mod.dump(true, false, false);
|
||||
// mod.dump(true, true, true);
|
||||
|
||||
auto g = mod.get_method("forward").graph();
|
||||
|
||||
// g->dump();
|
||||
|
||||
fprintf(stderr, "############# pass_level0\n");
|
||||
|
||||
std::map<std::string, pnnx::Attribute> foldable_constants;
|
||||
pnnx::pass_level0(mod, g, input_tensors, input_tensors2, module_operators, ptpath, foldable_constants);
|
||||
|
||||
// g->dump();
|
||||
|
||||
fprintf(stderr, "############# pass_level1\n");
|
||||
|
||||
pnnx::Graph pnnx_graph;
|
||||
pnnx::pass_level1(mod, g, pnnx_graph);
|
||||
|
||||
// g->dump();
|
||||
|
||||
fprintf(stderr, "############# pass_level2\n");
|
||||
|
||||
pnnx::pass_level2(pnnx_graph);
|
||||
|
||||
pnnx_graph.save("debug.param", "debug.bin");
|
||||
|
||||
if (optlevel >= 1)
|
||||
{
|
||||
fprintf(stderr, "############# pass_level3\n");
|
||||
|
||||
pnnx::pass_level3(pnnx_graph);
|
||||
|
||||
fprintf(stderr, "############# pass_level4\n");
|
||||
|
||||
pnnx::pass_level4(pnnx_graph);
|
||||
}
|
||||
|
||||
pnnx_graph.save("debug2.param", "debug2.bin");
|
||||
|
||||
if (optlevel >= 2)
|
||||
{
|
||||
fprintf(stderr, "############# pass_level5\n");
|
||||
|
||||
pnnx::pass_level5(pnnx_graph, foldable_constants);
|
||||
}
|
||||
|
||||
pnnx_graph.save(pnnxparampath, pnnxbinpath);
|
||||
|
||||
pnnx_graph.python(pnnxpypath, pnnxbinpath);
|
||||
|
||||
// if (optlevel >= 2)
|
||||
{
|
||||
fprintf(stderr, "############# pass_ncnn\n");
|
||||
|
||||
pnnx::pass_ncnn(pnnx_graph);
|
||||
|
||||
pnnx_graph.ncnn(ncnnparampath, ncnnbinpath, ncnnpypath);
|
||||
}
|
||||
|
||||
// pnnx::Graph pnnx_graph2;
|
||||
|
||||
// pnnx_graph2.load("pnnx.param", "pnnx.bin");
|
||||
// pnnx_graph2.save("pnnx2.param", "pnnx2.bin");
|
||||
|
||||
return 0;
|
||||
}
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level0.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level0.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level0.h"
|
||||
|
||||
#include "pass_level0/constant_unpooling.h"
|
||||
#include "pass_level0/inline_block.h"
|
||||
#include "pass_level0/shape_inference.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void pass_level0(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& g, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants)
|
||||
{
|
||||
inline_block(g, module_operators);
|
||||
|
||||
constant_unpooling(g);
|
||||
|
||||
if (!input_tensors.empty())
|
||||
{
|
||||
shape_inference(mod, g, input_tensors, input_tensors2, module_operators, ptpath, foldable_constants);
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
27
3rdparty/ncnn/tools/pnnx/src/pass_level0.h
vendored
Normal file
27
3rdparty/ncnn/tools/pnnx/src/pass_level0.h
vendored
Normal file
@@ -0,0 +1,27 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef PNNX_PASS_LEVEL0_H
|
||||
#define PNNX_PASS_LEVEL0_H
|
||||
|
||||
#include <torch/script.h>
|
||||
#include "ir.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void pass_level0(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& g, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants);
|
||||
|
||||
} // namespace pnnx
|
||||
|
||||
#endif // PNNX_PASS_LEVEL0_H
|
||||
80
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.cpp
vendored
Normal file
80
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.cpp
vendored
Normal file
@@ -0,0 +1,80 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "constant_unpooling.h"
|
||||
|
||||
#include <unordered_map>
|
||||
#include <unordered_set>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void ConstantUnpooling(std::shared_ptr<torch::jit::Graph>& graph, torch::jit::Block* block, std::unordered_set<torch::jit::Node*>& constants)
|
||||
{
|
||||
for (auto it = block->nodes().begin(); it != block->nodes().end();)
|
||||
{
|
||||
auto node = *it;
|
||||
// node may be moved to a different block so advance iterator now
|
||||
++it;
|
||||
|
||||
if (!node->blocks().empty())
|
||||
{
|
||||
// Traverse sub-blocks.
|
||||
for (auto block : node->blocks())
|
||||
{
|
||||
ConstantUnpooling(graph, block, constants);
|
||||
}
|
||||
|
||||
continue;
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)node->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = node->input(i);
|
||||
|
||||
if (in->node()->kind() != c10::prim::Constant)
|
||||
continue;
|
||||
|
||||
// input constant node
|
||||
if (constants.find(in->node()) == constants.end())
|
||||
{
|
||||
constants.insert(in->node());
|
||||
continue;
|
||||
}
|
||||
|
||||
torch::jit::WithInsertPoint guard(node);
|
||||
|
||||
std::unordered_map<torch::jit::Value*, torch::jit::Value*> value_map;
|
||||
auto value_map_func = [&](torch::jit::Value* v) {
|
||||
return value_map.at(v);
|
||||
};
|
||||
|
||||
// graph->setInsertPoint(node);
|
||||
|
||||
auto* new_constant_node = graph->insertNode(graph->createClone(in->node(), value_map_func, false));
|
||||
|
||||
// fprintf(stderr, "new_constant_node %s\n", new_constant_node->outputs()[0]->debugName().c_str());
|
||||
|
||||
// create new constant node
|
||||
node->replaceInput(i, new_constant_node->outputs()[0]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void constant_unpooling(std::shared_ptr<torch::jit::Graph>& graph)
|
||||
{
|
||||
std::unordered_set<torch::jit::Node*> constants;
|
||||
ConstantUnpooling(graph, graph->block(), constants);
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.h
vendored
Normal file
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.h
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/script.h>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void constant_unpooling(std::shared_ptr<torch::jit::Graph>& graph);
|
||||
|
||||
} // namespace pnnx
|
||||
142
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.cpp
vendored
Normal file
142
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.cpp
vendored
Normal file
@@ -0,0 +1,142 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "inline_block.h"
|
||||
#include "../pass_level1.h"
|
||||
|
||||
#include <set>
|
||||
|
||||
#include <torch/csrc/jit/passes/quantization/helper.h>
|
||||
#include <torch/csrc/api/include/torch/version.h>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
static void inlineCallTo(torch::jit::Node* to_replace, torch::jit::Function* callee)
|
||||
{
|
||||
torch::jit::WithInsertPoint guard(to_replace);
|
||||
|
||||
std::unordered_map<torch::jit::Value*, torch::jit::Value*> value_map;
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
std::vector<torch::jit::Value*> new_outputs = torch::jit::insertGraph(*to_replace->owningGraph(), *(toGraphFunction(*callee).graph()), to_replace->inputs(), value_map);
|
||||
#else
|
||||
std::vector<torch::jit::Value*> new_outputs = torch::jit::insertGraph(*to_replace->owningGraph(), *(callee->graph()), to_replace->inputs(), value_map);
|
||||
#endif
|
||||
|
||||
const auto& old_outputs = to_replace->outputs();
|
||||
for (size_t i = 0; i < old_outputs.size(); ++i)
|
||||
{
|
||||
new_outputs[i]->copyMetadata(old_outputs[i]);
|
||||
|
||||
old_outputs[i]->replaceAllUsesWith(new_outputs[i]);
|
||||
}
|
||||
|
||||
to_replace->destroy();
|
||||
}
|
||||
|
||||
static void inlineCalls(torch::jit::Block* block, const std::vector<std::string>& module_operators, std::set<std::string>& inlined_modules)
|
||||
{
|
||||
for (auto it = block->nodes().begin(), end = block->nodes().end(); it != end;)
|
||||
{
|
||||
torch::jit::Node* n = *it++;
|
||||
if (n->kind() == c10::prim::CallFunction)
|
||||
{
|
||||
auto function_constant = n->input(0)->node();
|
||||
auto fun_type = function_constant->output()->type()->expect<torch::jit::FunctionType>();
|
||||
if (!fun_type->function()->isGraphFunction())
|
||||
continue;
|
||||
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
inlineCalls(toGraphFunction(*(fun_type->function())).graph()->block(), module_operators, inlined_modules);
|
||||
#else
|
||||
inlineCalls(fun_type->function()->graph()->block(), module_operators, inlined_modules);
|
||||
#endif
|
||||
|
||||
n->removeInput(0);
|
||||
|
||||
fprintf(stderr, "inline function %s\n", fun_type->function()->name().c_str());
|
||||
|
||||
pnnx::inlineCallTo(n, fun_type->function());
|
||||
}
|
||||
else if (n->kind() == c10::prim::CallMethod)
|
||||
{
|
||||
auto class_type = n->input(0)->type()->cast<torch::jit::ClassType>();
|
||||
if (!class_type)
|
||||
continue;
|
||||
|
||||
const std::string& function_name = n->s(torch::jit::attr::name);
|
||||
torch::jit::Function& function = class_type->getMethod(function_name);
|
||||
if (!function.isGraphFunction())
|
||||
continue;
|
||||
|
||||
std::string class_type_str = torch::jit::removeTorchMangle(class_type->str());
|
||||
|
||||
bool skip_inline = false;
|
||||
for (const auto& ow : get_global_pnnx_fuse_module_passes())
|
||||
{
|
||||
if (class_type_str == ow->match_type_str())
|
||||
{
|
||||
skip_inline = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (skip_inline)
|
||||
continue;
|
||||
|
||||
std::string class_type_str_no_torch_prefix = class_type_str.substr(10);
|
||||
|
||||
if (std::find(module_operators.begin(), module_operators.end(), class_type_str_no_torch_prefix) != module_operators.end())
|
||||
{
|
||||
continue;
|
||||
}
|
||||
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
inlineCalls(toGraphFunction(function).graph()->block(), module_operators, inlined_modules);
|
||||
#else
|
||||
inlineCalls(function.graph()->block(), module_operators, inlined_modules);
|
||||
#endif
|
||||
|
||||
inlined_modules.insert(class_type_str_no_torch_prefix);
|
||||
|
||||
// fprintf(stderr, "inline %s\n", class_type_str_no_torch_prefix.c_str());
|
||||
// fprintf(stderr, "inline method %s %s %s\n", function.name().c_str(), class_type->str().c_str(), n->input(0)->node()->s(torch::jit::attr::name).c_str());
|
||||
|
||||
pnnx::inlineCallTo(n, &function);
|
||||
}
|
||||
else
|
||||
{
|
||||
for (auto b : n->blocks())
|
||||
{
|
||||
inlineCalls(b, module_operators, inlined_modules);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void inline_block(std::shared_ptr<torch::jit::Graph>& graph, const std::vector<std::string>& module_operators)
|
||||
{
|
||||
std::set<std::string> inlined_modules;
|
||||
|
||||
inlineCalls(graph->block(), module_operators, inlined_modules);
|
||||
|
||||
for (const auto& x : inlined_modules)
|
||||
{
|
||||
if (x == "torch.nn.modules.container.Sequential")
|
||||
continue;
|
||||
|
||||
fprintf(stderr, "inline module = %s\n", x.c_str());
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.h
vendored
Normal file
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.h
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/script.h>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void inline_block(std::shared_ptr<torch::jit::Graph>& graph, const std::vector<std::string>& module_operators);
|
||||
|
||||
} // namespace pnnx
|
||||
293
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.cpp
vendored
Normal file
293
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.cpp
vendored
Normal file
@@ -0,0 +1,293 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "shape_inference.h"
|
||||
#include <unordered_set>
|
||||
|
||||
#include "pass_level0/constant_unpooling.h"
|
||||
#include "pass_level0/inline_block.h"
|
||||
#include "pass_level0/shape_inference.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
static bool value_link_input(const torch::jit::Value* v, const std::vector<torch::jit::Value*>& inputs)
|
||||
{
|
||||
for (auto x : inputs)
|
||||
{
|
||||
if (v == x)
|
||||
return true;
|
||||
}
|
||||
|
||||
for (size_t i = 0; i < v->node()->inputs().size(); i++)
|
||||
{
|
||||
bool link = value_link_input(v->node()->inputs()[i], inputs);
|
||||
if (link)
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
static bool value_link_output(const torch::jit::Value* v, const std::vector<torch::jit::Value*>& outputs)
|
||||
{
|
||||
for (auto x : outputs)
|
||||
{
|
||||
if (v == x)
|
||||
return true;
|
||||
}
|
||||
|
||||
for (size_t i = 0; i < v->uses().size(); i++)
|
||||
{
|
||||
auto node = v->uses()[i].user;
|
||||
for (auto x : node->outputs())
|
||||
{
|
||||
bool link = value_link_output(x, outputs);
|
||||
if (link)
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
void shape_inference(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& graph, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants)
|
||||
{
|
||||
// collect all intermediate output tensors
|
||||
std::vector<std::unordered_set<std::string> > more_value_names;
|
||||
std::vector<std::vector<torch::jit::Value*> > more_values;
|
||||
{
|
||||
std::unordered_set<std::string> value_names;
|
||||
std::vector<torch::jit::Value*> values;
|
||||
for (const auto& n : graph->nodes())
|
||||
{
|
||||
for (const auto& v : n->outputs())
|
||||
{
|
||||
auto tensor_type = v->type()->cast<torch::jit::TensorType>();
|
||||
if (!tensor_type)
|
||||
continue;
|
||||
|
||||
value_names.insert(v->debugName());
|
||||
values.push_back(v);
|
||||
}
|
||||
|
||||
// too many intermediate blobs in one inference results oom
|
||||
if (value_names.size() >= 1000)
|
||||
{
|
||||
more_value_names.push_back(value_names);
|
||||
value_names.clear();
|
||||
|
||||
more_values.push_back(values);
|
||||
values.clear();
|
||||
}
|
||||
}
|
||||
|
||||
if (value_names.size() > 0)
|
||||
{
|
||||
more_value_names.push_back(value_names);
|
||||
more_values.push_back(values);
|
||||
}
|
||||
}
|
||||
|
||||
// collect graph inputs outputs
|
||||
std::vector<torch::jit::Value*> g_inputs;
|
||||
for (size_t i = 1; i < graph->inputs().size(); i++)
|
||||
{
|
||||
g_inputs.push_back(graph->inputs()[i]);
|
||||
}
|
||||
std::vector<torch::jit::Value*> g_outputs;
|
||||
for (size_t i = 0; i < graph->outputs().size(); i++)
|
||||
{
|
||||
g_outputs.push_back(graph->outputs()[i]);
|
||||
}
|
||||
|
||||
std::vector<torch::jit::IValue> inputs;
|
||||
for (size_t i = 0; i < input_tensors.size(); i++)
|
||||
{
|
||||
const at::Tensor& it = input_tensors[i];
|
||||
inputs.push_back(it);
|
||||
}
|
||||
|
||||
std::vector<torch::jit::IValue> inputs2;
|
||||
for (size_t i = 0; i < input_tensors2.size(); i++)
|
||||
{
|
||||
const at::Tensor& it = input_tensors2[i];
|
||||
inputs2.push_back(it);
|
||||
}
|
||||
|
||||
std::map<torch::jit::Value*, at::Tensor> output_tensors;
|
||||
|
||||
for (size_t p = 0; p < more_value_names.size(); p++)
|
||||
{
|
||||
std::unordered_set<std::string>& value_names = more_value_names[p];
|
||||
std::vector<torch::jit::Value*>& values = more_values[p];
|
||||
|
||||
// auto mod2 = mod.deepcopy();
|
||||
|
||||
torch::jit::Module mod2 = torch::jit::load(ptpath);
|
||||
mod2.eval();
|
||||
|
||||
auto graph2 = mod2.get_method("forward").graph();
|
||||
|
||||
inline_block(graph2, module_operators);
|
||||
|
||||
constant_unpooling(graph2);
|
||||
|
||||
std::vector<torch::jit::Value*> values2;
|
||||
for (auto n : graph2->nodes())
|
||||
{
|
||||
for (const auto& v : n->outputs())
|
||||
{
|
||||
auto tensor_type = v->type()->cast<torch::jit::TensorType>();
|
||||
if (!tensor_type)
|
||||
continue;
|
||||
|
||||
if (value_names.find(v->debugName()) != value_names.end())
|
||||
{
|
||||
values2.push_back(v);
|
||||
fprintf(stderr, "%s ", v->debugName().c_str());
|
||||
}
|
||||
}
|
||||
}
|
||||
fprintf(stderr, "\n----------------\n\n");
|
||||
|
||||
// set new graph output
|
||||
torch::jit::Node* new_return_node = graph2->createTuple(at::ArrayRef<torch::jit::Value*>(values2));
|
||||
|
||||
graph2->appendNode(new_return_node);
|
||||
|
||||
graph2->eraseOutput(0);
|
||||
graph2->registerOutput(new_return_node->outputs()[0]);
|
||||
|
||||
// inference for all tensors
|
||||
auto outputs = mod2.copy().forward(inputs).toTuple();
|
||||
|
||||
if (input_tensors2.empty())
|
||||
{
|
||||
// assign shape info
|
||||
for (size_t i = 0; i < values2.size(); i++)
|
||||
{
|
||||
auto v = values[i];
|
||||
auto t = outputs->elements()[i].toTensor();
|
||||
|
||||
v->setType(c10::TensorType::create(t));
|
||||
|
||||
// check if value that does not depend on inputs
|
||||
if (!value_link_input(v, g_inputs) && value_link_output(v, g_outputs))
|
||||
{
|
||||
output_tensors[v] = t;
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
// assign dynamic shape info
|
||||
auto outputs2 = mod2.copy().forward(inputs2).toTuple();
|
||||
|
||||
fprintf(stderr, "assign dynamic shape info\n");
|
||||
|
||||
for (size_t i = 0; i < values2.size(); i++)
|
||||
{
|
||||
auto v = values[i];
|
||||
auto t = outputs->elements()[i].toTensor();
|
||||
auto t2 = outputs2->elements()[i].toTensor();
|
||||
|
||||
auto type1 = c10::TensorType::create(t);
|
||||
auto type2 = c10::TensorType::create(t2);
|
||||
|
||||
std::vector<c10::ShapeSymbol> sizes1 = type1->symbolic_sizes().sizes().value();
|
||||
std::vector<c10::ShapeSymbol> sizes2 = type2->symbolic_sizes().sizes().value();
|
||||
|
||||
for (size_t i = 0; i < sizes1.size(); i++)
|
||||
{
|
||||
if (sizes1[i] == sizes2[i])
|
||||
continue;
|
||||
|
||||
sizes1[i] = c10::ShapeSymbol::fromStaticSize(-1);
|
||||
}
|
||||
|
||||
auto finaltype = type1->withSymbolicShapes(c10::SymbolicShape(sizes1));
|
||||
|
||||
v->setType(finaltype);
|
||||
|
||||
// check if value that does not depend on inputs
|
||||
if (!value_link_input(v, g_inputs) && value_link_output(v, g_outputs))
|
||||
{
|
||||
output_tensors[v] = t;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (input_tensors2.empty())
|
||||
{
|
||||
for (size_t i = 0; i < input_tensors.size(); i++)
|
||||
{
|
||||
auto type = c10::TensorType::create(input_tensors[i]);
|
||||
|
||||
graph->inputs()[1 + i]->setType(type);
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
for (size_t i = 0; i < input_tensors.size(); i++)
|
||||
{
|
||||
auto type1 = c10::TensorType::create(input_tensors[i]);
|
||||
auto type2 = c10::TensorType::create(input_tensors2[i]);
|
||||
|
||||
std::vector<c10::ShapeSymbol> sizes1 = type1->symbolic_sizes().sizes().value();
|
||||
std::vector<c10::ShapeSymbol> sizes2 = type2->symbolic_sizes().sizes().value();
|
||||
|
||||
for (size_t i = 0; i < sizes1.size(); i++)
|
||||
{
|
||||
if (sizes1[i] == sizes2[i])
|
||||
continue;
|
||||
|
||||
sizes1[i] = c10::ShapeSymbol::fromStaticSize(-1);
|
||||
}
|
||||
|
||||
auto finaltype = type1->withSymbolicShapes(c10::SymbolicShape(sizes1));
|
||||
|
||||
graph->inputs()[1 + i]->setType(finaltype);
|
||||
}
|
||||
}
|
||||
|
||||
for (auto xx : output_tensors)
|
||||
{
|
||||
auto v = xx.first;
|
||||
auto tensor = xx.second;
|
||||
|
||||
bool link_to_output = false;
|
||||
for (size_t i = 0; i < v->uses().size(); i++)
|
||||
{
|
||||
auto node = v->uses()[i].user;
|
||||
for (auto x : node->outputs())
|
||||
{
|
||||
if (output_tensors.find(x) == output_tensors.end())
|
||||
{
|
||||
link_to_output = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const int ndim = (int)tensor.dim();
|
||||
if (link_to_output && ndim > 0)
|
||||
{
|
||||
fprintf(stderr, "foldable_constant %s\n", v->debugName().c_str());
|
||||
foldable_constants[v->debugName()] = Attribute(tensor);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
23
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.h
vendored
Normal file
23
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.h
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/script.h>
|
||||
#include <map>
|
||||
#include "ir.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void shape_inference(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& graph, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants);
|
||||
|
||||
} // namespace pnnx
|
||||
313
3rdparty/ncnn/tools/pnnx/src/pass_level1.cpp
vendored
Normal file
313
3rdparty/ncnn/tools/pnnx/src/pass_level1.cpp
vendored
Normal file
@@ -0,0 +1,313 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/csrc/jit/passes/quantization/helper.h>
|
||||
#include <torch/csrc/api/include/torch/version.h>
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
FuseModulePass::~FuseModulePass()
|
||||
{
|
||||
}
|
||||
|
||||
void FuseModulePass::write(Operator* /*op*/, const std::shared_ptr<torch::jit::Graph>& /*graph*/) const
|
||||
{
|
||||
}
|
||||
|
||||
void FuseModulePass::write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& /*mod*/) const
|
||||
{
|
||||
write(op, graph);
|
||||
}
|
||||
|
||||
static std::vector<const FuseModulePass*> g_global_pnnx_fuse_module_passes;
|
||||
|
||||
const std::vector<const FuseModulePass*>& get_global_pnnx_fuse_module_passes()
|
||||
{
|
||||
return g_global_pnnx_fuse_module_passes;
|
||||
}
|
||||
|
||||
FuseModulePassRegister::FuseModulePassRegister(const FuseModulePass* _pass)
|
||||
: pass(_pass)
|
||||
{
|
||||
g_global_pnnx_fuse_module_passes.push_back(pass);
|
||||
}
|
||||
|
||||
FuseModulePassRegister::~FuseModulePassRegister()
|
||||
{
|
||||
delete pass;
|
||||
}
|
||||
|
||||
void pass_level1(const torch::jit::Module& mod, const std::shared_ptr<torch::jit::Graph>& g, Graph& pg)
|
||||
{
|
||||
for (int i = 1; i < (int)g->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = g->inputs()[i];
|
||||
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_input_%d", i - 1);
|
||||
|
||||
Operator* op = pg.new_operator("pnnx.Input", name);
|
||||
Operand* r = pg.new_operand(in);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
std::map<std::string, std::string> class_type_to_names;
|
||||
int pnnx_unknown_index = 0;
|
||||
|
||||
for (const auto& n : g->block()->nodes())
|
||||
{
|
||||
if (n->kind() == c10::prim::GetAttr)
|
||||
{
|
||||
// pass
|
||||
std::string name = n->s(torch::jit::attr::name);
|
||||
// std::string name = n->debugName();
|
||||
|
||||
auto class_type = n->output(0)->type()->cast<torch::jit::ClassType>();
|
||||
|
||||
if (class_type)
|
||||
{
|
||||
std::string class_type_str = class_type->str();
|
||||
class_type_to_names[class_type_str] = name;
|
||||
// class_type_to_names[class_type_str] = class_type_str + "." + name;
|
||||
}
|
||||
else
|
||||
{
|
||||
// Tensor from some class
|
||||
// Operator* op = pg.new_operator(n->kind().toDisplayString(), name);
|
||||
Operator* op = pg.new_operator("pnnx.Attribute", name);
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
std::deque<std::string> module_names; // = split(n->input(0)->node()->s(torch::jit::attr::name), '.');
|
||||
{
|
||||
auto np = n->input(0)->node();
|
||||
while (np->hasAttribute(torch::jit::attr::name))
|
||||
{
|
||||
module_names.push_front(np->s(torch::jit::attr::name));
|
||||
np = np->input(0)->node();
|
||||
}
|
||||
}
|
||||
|
||||
std::string wrapped_name;
|
||||
auto sub_mod = mod;
|
||||
for (auto module_name : module_names)
|
||||
{
|
||||
if (wrapped_name.size() > 0)
|
||||
wrapped_name = wrapped_name + "." + module_name;
|
||||
else
|
||||
wrapped_name = module_name;
|
||||
sub_mod = sub_mod.attr(module_name).toModule();
|
||||
}
|
||||
|
||||
if (wrapped_name.empty())
|
||||
{
|
||||
// top-level module
|
||||
wrapped_name = name;
|
||||
}
|
||||
|
||||
op->name = wrapped_name;
|
||||
|
||||
// op->params["this"] = n->input(i)
|
||||
|
||||
// sub_mod.dump(true, true, true);
|
||||
|
||||
op->attrs[name] = sub_mod.attr(name).toTensor();
|
||||
}
|
||||
}
|
||||
else if (n->kind() == c10::prim::Constant) // || n->kind() == c10::prim::ListConstruct)
|
||||
{
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_%d", pnnx_unknown_index++);
|
||||
|
||||
Operator* op = pg.new_operator(n->kind().toDisplayString(), name);
|
||||
|
||||
for (int i = 0; i < (int)n->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = n->input(i);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
op->params["value"] = n;
|
||||
|
||||
if (op->params["value"].type == 8)
|
||||
{
|
||||
op->type = "pnnx.Attribute";
|
||||
|
||||
op->params.erase("value");
|
||||
|
||||
op->attrs[name] = n->t(torch::jit::attr::value);
|
||||
}
|
||||
}
|
||||
else if (n->kind() == c10::prim::CallMethod)
|
||||
{
|
||||
auto class_type = n->input(0)->type()->cast<torch::jit::ClassType>();
|
||||
// const std::string& name = n->s(torch::jit::attr::name);
|
||||
|
||||
// fprintf(stderr, "call %s\n", class_type->str().c_str());
|
||||
|
||||
std::string name = class_type_to_names[class_type->str()];
|
||||
|
||||
std::string class_type_str = torch::jit::removeTorchMangle(class_type->str());
|
||||
|
||||
std::string optypename = class_type_str;
|
||||
for (const auto& ow : get_global_pnnx_fuse_module_passes())
|
||||
{
|
||||
if (class_type_str != ow->match_type_str())
|
||||
continue;
|
||||
|
||||
optypename = ow->type_str();
|
||||
break;
|
||||
}
|
||||
|
||||
if (optypename == class_type_str)
|
||||
{
|
||||
optypename = class_type_str.substr(10);
|
||||
}
|
||||
|
||||
Operator* op = pg.new_operator(optypename, name);
|
||||
|
||||
for (int i = 1; i < (int)n->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = n->input(i);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
for (const auto& ow : get_global_pnnx_fuse_module_passes())
|
||||
{
|
||||
if (class_type_str != ow->match_type_str())
|
||||
continue;
|
||||
|
||||
auto class_type = n->input(0)->type()->cast<torch::jit::ClassType>();
|
||||
torch::jit::Function& function = class_type->getMethod(n->s(torch::jit::attr::name));
|
||||
|
||||
std::deque<std::string> module_names; // = split(n->input(0)->node()->s(torch::jit::attr::name), '.');
|
||||
{
|
||||
auto np = n->input(0)->node();
|
||||
while (np->hasAttribute(torch::jit::attr::name))
|
||||
{
|
||||
module_names.push_front(np->s(torch::jit::attr::name));
|
||||
np = np->input(0)->node();
|
||||
}
|
||||
}
|
||||
|
||||
std::string wrapped_name;
|
||||
auto sub_mod = mod;
|
||||
for (auto module_name : module_names)
|
||||
{
|
||||
if (wrapped_name.size() > 0)
|
||||
wrapped_name = wrapped_name + "." + module_name;
|
||||
else
|
||||
wrapped_name = module_name;
|
||||
sub_mod = sub_mod.attr(module_name).toModule();
|
||||
}
|
||||
|
||||
op->name = wrapped_name;
|
||||
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
ow->write(op, toGraphFunction(function).graph(), sub_mod);
|
||||
#else
|
||||
ow->write(op, function.graph(), sub_mod);
|
||||
#endif
|
||||
|
||||
break;
|
||||
}
|
||||
}
|
||||
// else if (n->kind() == c10::prim::CallFunction)
|
||||
// {
|
||||
// fprintf(stderr, "function %s", n->kind().toDisplayString());
|
||||
//
|
||||
// AT_ASSERT(cur->input(0)->node()->kind() == c10::prim::Constant);
|
||||
// auto function_constant = cur->input(0)->node();
|
||||
// auto fun_type = function_constant->output()->type()->expect<torch::jit::FunctionType>();
|
||||
// if (!fun_type->function()->isGraphFunction())
|
||||
// {
|
||||
// continue;
|
||||
// }
|
||||
// cur->removeInput(0);
|
||||
//
|
||||
// fprintf(stderr, "inline function %s\n", fun_type->function()->name().c_str());
|
||||
//
|
||||
// GRAPH_UPDATE("Inlining function '", fun_type->function()->name(), "' to ", *cur);
|
||||
// GRAPH_UPDATE("Function body: ", *fun_type->function()->optimized_graph());
|
||||
// inlineCallTo(cur, fun_type->function(), false);
|
||||
// break;
|
||||
// }
|
||||
else
|
||||
{
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_%d", pnnx_unknown_index++);
|
||||
|
||||
Operator* op = pg.new_operator(n->kind().toDisplayString(), name);
|
||||
|
||||
for (int i = 0; i < (int)n->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = n->input(i);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)g->outputs().size(); i++)
|
||||
{
|
||||
const auto& in = g->outputs()[i];
|
||||
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_output_%d", i);
|
||||
Operator* op = pg.new_operator("pnnx.Output", name);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
55
3rdparty/ncnn/tools/pnnx/src/pass_level1.h
vendored
Normal file
55
3rdparty/ncnn/tools/pnnx/src/pass_level1.h
vendored
Normal file
@@ -0,0 +1,55 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef PNNX_PASS_LEVEL1_H
|
||||
#define PNNX_PASS_LEVEL1_H
|
||||
|
||||
#include <torch/script.h>
|
||||
#include <torch/csrc/jit/api/module.h>
|
||||
#include "ir.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class FuseModulePass
|
||||
{
|
||||
public:
|
||||
virtual ~FuseModulePass();
|
||||
|
||||
virtual const char* match_type_str() const = 0;
|
||||
|
||||
virtual const char* type_str() const = 0;
|
||||
|
||||
virtual void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const;
|
||||
|
||||
virtual void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const;
|
||||
};
|
||||
|
||||
class FuseModulePassRegister
|
||||
{
|
||||
public:
|
||||
FuseModulePassRegister(const FuseModulePass* pass);
|
||||
~FuseModulePassRegister();
|
||||
const FuseModulePass* pass;
|
||||
};
|
||||
|
||||
const std::vector<const FuseModulePass*>& get_global_pnnx_fuse_module_passes();
|
||||
|
||||
#define REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(CLASS) \
|
||||
static FuseModulePassRegister g_global_pnnx_fusemodulepass_##CLASS##_register(new CLASS);
|
||||
|
||||
void pass_level1(const torch::jit::Module& mod, const std::shared_ptr<torch::jit::Graph>& g, Graph& pg);
|
||||
|
||||
} // namespace pnnx
|
||||
|
||||
#endif // PNNX_PASS_LEVEL1_H
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool1d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool1d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveAvgPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveAvgPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveAvgPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_avg_pool1d = find_node_by_kind(graph, "aten::adaptive_avg_pool1d");
|
||||
|
||||
op->params["output_size"] = adaptive_avg_pool1d->namedInput("output_size");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveAvgPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool2d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool2d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveAvgPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveAvgPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveAvgPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_avg_pool2d = find_node_by_kind(graph, "aten::adaptive_avg_pool2d");
|
||||
|
||||
op->params["output_size"] = adaptive_avg_pool2d->namedInput("output_size");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveAvgPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool3d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool3d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveAvgPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveAvgPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveAvgPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_avg_pool3d = find_node_by_kind(graph, "aten::adaptive_avg_pool3d");
|
||||
|
||||
op->params["output_size"] = adaptive_avg_pool3d->namedInput("output_size");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveAvgPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool1d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool1d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveMaxPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveMaxPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveMaxPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_max_pool1d = find_node_by_kind(graph, "aten::adaptive_max_pool1d");
|
||||
|
||||
op->params["output_size"] = adaptive_max_pool1d->namedInput("output_size");
|
||||
op->params["return_indices"] = graph->outputs()[0]->node()->kind() == c10::prim::TupleConstruct ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveMaxPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool2d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool2d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveMaxPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveMaxPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveMaxPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_max_pool2d = find_node_by_kind(graph, "aten::adaptive_max_pool2d");
|
||||
|
||||
op->params["output_size"] = adaptive_max_pool2d->namedInput("output_size");
|
||||
op->params["return_indices"] = graph->outputs()[0]->node()->kind() == c10::prim::TupleConstruct ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveMaxPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool3d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool3d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveMaxPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveMaxPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveMaxPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_max_pool3d = find_node_by_kind(graph, "aten::adaptive_max_pool3d");
|
||||
|
||||
op->params["output_size"] = adaptive_max_pool3d->namedInput("output_size");
|
||||
op->params["return_indices"] = graph->outputs()[0]->node()->kind() == c10::prim::TupleConstruct ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveMaxPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AlphaDropout.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AlphaDropout.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AlphaDropout : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.AlphaDropout";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AlphaDropout";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AlphaDropout)
|
||||
|
||||
} // namespace pnnx
|
||||
48
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool1d.cpp
vendored
Normal file
48
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool1d.cpp
vendored
Normal file
@@ -0,0 +1,48 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AvgPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AvgPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AvgPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool1d = find_node_by_kind(graph, "aten::avg_pool1d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool1d->namedInput("kernel_size");
|
||||
op->params["stride"] = avg_pool1d->namedInput("stride");
|
||||
op->params["padding"] = avg_pool1d->namedInput("padding");
|
||||
op->params["ceil_mode"] = avg_pool1d->namedInput("ceil_mode");
|
||||
op->params["count_include_pad"] = avg_pool1d->namedInput("count_include_pad");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AvgPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool2d.cpp
vendored
Normal file
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool2d.cpp
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AvgPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AvgPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AvgPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool2d = find_node_by_kind(graph, "aten::avg_pool2d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool2d->namedInput("kernel_size");
|
||||
op->params["stride"] = avg_pool2d->namedInput("stride");
|
||||
op->params["padding"] = avg_pool2d->namedInput("padding");
|
||||
op->params["ceil_mode"] = avg_pool2d->namedInput("ceil_mode");
|
||||
op->params["count_include_pad"] = avg_pool2d->namedInput("count_include_pad");
|
||||
op->params["divisor_override"] = avg_pool2d->namedInput("divisor_override");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AvgPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool3d.cpp
vendored
Normal file
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool3d.cpp
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AvgPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AvgPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AvgPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool3d = find_node_by_kind(graph, "aten::avg_pool3d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool3d->namedInput("kernel_size");
|
||||
op->params["stride"] = avg_pool3d->namedInput("stride");
|
||||
op->params["padding"] = avg_pool3d->namedInput("padding");
|
||||
op->params["ceil_mode"] = avg_pool3d->namedInput("ceil_mode");
|
||||
op->params["count_include_pad"] = avg_pool3d->namedInput("count_include_pad");
|
||||
op->params["divisor_override"] = avg_pool3d->namedInput("divisor_override");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AvgPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm1d.cpp
vendored
Normal file
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm1d.cpp
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class BatchNorm1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.batchnorm.BatchNorm1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.BatchNorm1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* bn = find_node_by_kind(graph, "aten::batch_norm");
|
||||
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
const auto& running_var = mod.attr("running_var").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
op->params["eps"] = bn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = running_var;
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(BatchNorm1d)
|
||||
|
||||
} // namespace pnnx
|
||||
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm2d.cpp
vendored
Normal file
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm2d.cpp
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class BatchNorm2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.batchnorm.BatchNorm2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.BatchNorm2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* bn = find_node_by_kind(graph, "aten::batch_norm");
|
||||
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
const auto& running_var = mod.attr("running_var").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
op->params["eps"] = bn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = running_var;
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(BatchNorm2d)
|
||||
|
||||
} // namespace pnnx
|
||||
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm3d.cpp
vendored
Normal file
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm3d.cpp
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class BatchNorm3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.batchnorm.BatchNorm3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.BatchNorm3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* bn = find_node_by_kind(graph, "aten::batch_norm");
|
||||
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
const auto& running_var = mod.attr("running_var").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
op->params["eps"] = bn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = running_var;
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(BatchNorm3d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_CELU.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_CELU.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class CELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.CELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.CELU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* celu = find_node_by_kind(graph, "aten::celu");
|
||||
|
||||
op->params["alpha"] = celu->namedInput("alpha");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(CELU)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ChannelShuffle.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ChannelShuffle.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ChannelShuffle : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.channelshuffle.ChannelShuffle";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ChannelShuffle";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* channel_shuffle = find_node_by_kind(graph, "aten::channel_shuffle");
|
||||
|
||||
op->params["groups"] = channel_shuffle->namedInput("groups");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ChannelShuffle)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad1d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad1d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConstantPad1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ConstantPad1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConstantPad1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
op->params["value"] = constant_pad_nd->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConstantPad1d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad2d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad2d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConstantPad2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ConstantPad2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConstantPad2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
op->params["value"] = constant_pad_nd->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConstantPad2d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad3d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad3d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConstantPad3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ConstantPad3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConstantPad3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
op->params["value"] = constant_pad_nd->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConstantPad3d)
|
||||
|
||||
} // namespace pnnx
|
||||
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv1d.cpp
vendored
Normal file
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv1d.cpp
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
// #include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Conv1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.Conv1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Conv1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// {
|
||||
// pnnx::Graph pnnx_graph;
|
||||
//
|
||||
// pnnx_graph.load(mod, graph);
|
||||
//
|
||||
// pnnx::fuse_expression(pnnx_graph);
|
||||
//
|
||||
// pnnx_graph.save("tmp.param", "tmp.bin");
|
||||
// }
|
||||
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
const torch::jit::Node* convolution_mode = find_node_by_kind(graph, "aten::_convolution_mode");
|
||||
const torch::jit::Node* reflection_pad1d = find_node_by_kind(graph, "aten::reflection_pad1d");
|
||||
const torch::jit::Node* replication_pad1d = find_node_by_kind(graph, "aten::replication_pad1d");
|
||||
|
||||
if (convolution_mode)
|
||||
{
|
||||
convolution = convolution_mode;
|
||||
}
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["out_channels"] = weight.size(0);
|
||||
op->params["kernel_size"] = Parameter{weight.size(2)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
if (reflection_pad1d)
|
||||
{
|
||||
op->params["padding_mode"] = "reflect";
|
||||
op->params["padding"] = reflection_pad1d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 2)
|
||||
{
|
||||
// Conv1d only accepts tuple of one integer
|
||||
if (padding[0] == padding[1])
|
||||
{
|
||||
padding.resize(1);
|
||||
}
|
||||
else if (padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else if (replication_pad1d)
|
||||
{
|
||||
op->params["padding_mode"] = "replicate";
|
||||
op->params["padding"] = replication_pad1d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 2)
|
||||
{
|
||||
// Conv1d only accepts tuple of one integer
|
||||
if (padding[0] == padding[1])
|
||||
{
|
||||
padding.resize(1);
|
||||
}
|
||||
else if (padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
}
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Conv1d)
|
||||
|
||||
} // namespace pnnx
|
||||
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv2d.cpp
vendored
Normal file
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv2d.cpp
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
// #include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Conv2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.Conv2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Conv2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// {
|
||||
// pnnx::Graph pnnx_graph;
|
||||
//
|
||||
// pnnx_graph.load(mod, graph);
|
||||
//
|
||||
// pnnx::fuse_expression(pnnx_graph);
|
||||
//
|
||||
// pnnx_graph.save("tmp.param", "tmp.bin");
|
||||
// }
|
||||
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
const torch::jit::Node* convolution_mode = find_node_by_kind(graph, "aten::_convolution_mode");
|
||||
const torch::jit::Node* reflection_pad2d = find_node_by_kind(graph, "aten::reflection_pad2d");
|
||||
const torch::jit::Node* replication_pad2d = find_node_by_kind(graph, "aten::replication_pad2d");
|
||||
|
||||
if (convolution_mode)
|
||||
{
|
||||
convolution = convolution_mode;
|
||||
}
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["out_channels"] = weight.size(0);
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
if (reflection_pad2d)
|
||||
{
|
||||
op->params["padding_mode"] = "reflect";
|
||||
op->params["padding"] = reflection_pad2d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 4)
|
||||
{
|
||||
// Conv2d only accepts tuple of two integers
|
||||
if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3])
|
||||
{
|
||||
padding.resize(2);
|
||||
}
|
||||
else if (padding[0] == padding[2] && padding[1] == padding[3] && padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else if (replication_pad2d)
|
||||
{
|
||||
op->params["padding_mode"] = "replicate";
|
||||
op->params["padding"] = replication_pad2d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 4)
|
||||
{
|
||||
// Conv2d only accepts tuple of two integers
|
||||
if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3])
|
||||
{
|
||||
padding.resize(2);
|
||||
}
|
||||
else if (padding[0] == padding[2] && padding[1] == padding[3] && padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
}
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Conv2d)
|
||||
|
||||
} // namespace pnnx
|
||||
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv3d.cpp
vendored
Normal file
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv3d.cpp
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
// #include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Conv3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.Conv3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Conv3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// {
|
||||
// pnnx::Graph pnnx_graph;
|
||||
//
|
||||
// pnnx_graph.load(mod, graph);
|
||||
//
|
||||
// pnnx::fuse_expression(pnnx_graph);
|
||||
//
|
||||
// pnnx_graph.save("tmp.param", "tmp.bin");
|
||||
// }
|
||||
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
const torch::jit::Node* convolution_mode = find_node_by_kind(graph, "aten::_convolution_mode");
|
||||
// const torch::jit::Node* reflection_pad3d = find_node_by_kind(graph, "aten::reflection_pad3d");
|
||||
// const torch::jit::Node* replication_pad3d = find_node_by_kind(graph, "aten::replication_pad3d");
|
||||
|
||||
if (convolution_mode)
|
||||
{
|
||||
convolution = convolution_mode;
|
||||
}
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["out_channels"] = weight.size(0);
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3), weight.size(4)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
// if (reflection_pad3d)
|
||||
// {
|
||||
// op->params["padding_mode"] = "reflect";
|
||||
// op->params["padding"] = reflection_pad3d->namedInput("padding");
|
||||
// std::vector<int>& padding = op->params["padding"].ai;
|
||||
// if (padding.size() == 6)
|
||||
// {
|
||||
// // Conv3d only accepts tuple of three integers
|
||||
// if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3] && padding[3] == padding[4] && padding[4] == padding[5])
|
||||
// {
|
||||
// padding.resize(3);
|
||||
// }
|
||||
// else if (padding[0] == padding[3] && padding[1] == padding[4] && padding[2] == padding[5] && padding[0] != padding[1] && padding[1] != padding[2])
|
||||
// {
|
||||
// padding.resize(0);
|
||||
// op->params["padding"].s = "same";
|
||||
// }
|
||||
// }
|
||||
// }
|
||||
// else if (replication_pad3d)
|
||||
// {
|
||||
// op->params["padding_mode"] = "replicate";
|
||||
// op->params["padding"] = replication_pad3d->namedInput("padding");
|
||||
// std::vector<int>& padding = op->params["padding"].ai;
|
||||
// if (padding.size() == 6)
|
||||
// {
|
||||
// // Conv3d only accepts tuple of three integers
|
||||
// if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3] && padding[3] == padding[4] && padding[4] == padding[5])
|
||||
// {
|
||||
// padding.resize(3);
|
||||
// }
|
||||
// else if (padding[0] == padding[3] && padding[1] == padding[4] && padding[2] == padding[5] && padding[0] != padding[1] && padding[1] != padding[2])
|
||||
// {
|
||||
// padding.resize(0);
|
||||
// op->params["padding"].s = "same";
|
||||
// }
|
||||
// }
|
||||
// }
|
||||
// else
|
||||
{
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
}
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Conv3d)
|
||||
|
||||
} // namespace pnnx
|
||||
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose1d.cpp
vendored
Normal file
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose1d.cpp
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConvTranspose1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.ConvTranspose1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConvTranspose1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(0);
|
||||
op->params["out_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["kernel_size"] = Parameter{weight.size(2)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
op->params["output_padding"] = convolution->namedInput("output_padding");
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConvTranspose1d)
|
||||
|
||||
} // namespace pnnx
|
||||
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose2d.cpp
vendored
Normal file
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose2d.cpp
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConvTranspose2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.ConvTranspose2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConvTranspose2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(0);
|
||||
op->params["out_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
op->params["output_padding"] = convolution->namedInput("output_padding");
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConvTranspose2d)
|
||||
|
||||
} // namespace pnnx
|
||||
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose3d.cpp
vendored
Normal file
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose3d.cpp
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConvTranspose3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.ConvTranspose3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConvTranspose3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(0);
|
||||
op->params["out_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3), weight.size(4)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
op->params["output_padding"] = convolution->namedInput("output_padding");
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConvTranspose3d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Dropout : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.Dropout";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Dropout";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Dropout)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout2d.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout2d.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Dropout2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.Dropout2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Dropout2d";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Dropout2d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout3d.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout3d.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Dropout3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.Dropout3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Dropout3d";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Dropout3d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ELU.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ELU.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.ELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ELU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* elu = find_node_by_kind(graph, "aten::elu");
|
||||
|
||||
op->params["alpha"] = elu->namedInput("alpha");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ELU)
|
||||
|
||||
} // namespace pnnx
|
||||
53
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Embedding.cpp
vendored
Normal file
53
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Embedding.cpp
vendored
Normal file
@@ -0,0 +1,53 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Embedding : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.sparse.Embedding";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Embedding";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* embedding = find_node_by_kind(graph, "aten::embedding");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_embeddings"] = weight.size(0);
|
||||
op->params["embedding_dim"] = weight.size(1);
|
||||
|
||||
// op->params["padding_idx"] = embedding->namedInput("padding_idx");
|
||||
// op->params["scale_grad_by_freq"] = embedding->namedInput("scale_grad_by_freq");
|
||||
op->params["sparse"] = embedding->namedInput("sparse");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Embedding)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GELU.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GELU.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class GELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.GELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.GELU";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(GELU)
|
||||
|
||||
} // namespace pnnx
|
||||
110
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GRU.cpp
vendored
Normal file
110
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GRU.cpp
vendored
Normal file
@@ -0,0 +1,110 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class GRU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.rnn.GRU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.GRU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// mod.dump(true, true, true);
|
||||
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* gru = find_node_by_kind(graph, "aten::gru");
|
||||
|
||||
const torch::jit::Node* return_tuple = find_node_by_kind(graph, "prim::TupleConstruct");
|
||||
if (return_tuple && return_tuple->inputs().size() == 2 && gru->outputs().size() == 2
|
||||
&& return_tuple->inputs()[0] == gru->outputs()[1] && return_tuple->inputs()[1] == gru->outputs()[0])
|
||||
{
|
||||
// mark the swapped output tuple
|
||||
// we would restore the fine order in pass_level3/fuse_rnn_unpack
|
||||
fprintf(stderr, "swapped detected !\n");
|
||||
op->params["pnnx_rnn_output_swapped"] = 1;
|
||||
}
|
||||
|
||||
// for (auto aa : gru->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
const auto& weight_ih_l0 = mod.attr("weight_ih_l0").toTensor();
|
||||
|
||||
op->params["input_size"] = weight_ih_l0.size(1);
|
||||
op->params["hidden_size"] = weight_ih_l0.size(0) / 3;
|
||||
op->params["num_layers"] = gru->namedInput("num_layers");
|
||||
op->params["bias"] = gru->namedInput("has_biases");
|
||||
op->params["batch_first"] = gru->namedInput("batch_first");
|
||||
op->params["bidirectional"] = gru->namedInput("bidirectional");
|
||||
|
||||
const int num_layers = op->params["num_layers"].i;
|
||||
const bool bias = op->params["bias"].b;
|
||||
const bool bidirectional = op->params["bidirectional"].b;
|
||||
|
||||
for (int k = 0; k < num_layers; k++)
|
||||
{
|
||||
std::string weight_ih_lk_key = std::string("weight_ih_l") + std::to_string(k);
|
||||
std::string weight_hh_lk_key = std::string("weight_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[weight_ih_lk_key] = mod.attr(weight_ih_lk_key).toTensor();
|
||||
op->attrs[weight_hh_lk_key] = mod.attr(weight_hh_lk_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_key = std::string("bias_ih_l") + std::to_string(k);
|
||||
std::string bias_hh_lk_key = std::string("bias_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[bias_ih_lk_key] = mod.attr(bias_ih_lk_key).toTensor();
|
||||
op->attrs[bias_hh_lk_key] = mod.attr(bias_hh_lk_key).toTensor();
|
||||
}
|
||||
|
||||
if (bidirectional)
|
||||
{
|
||||
std::string weight_ih_lk_reverse_key = std::string("weight_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string weight_hh_lk_reverse_key = std::string("weight_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[weight_ih_lk_reverse_key] = mod.attr(weight_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[weight_hh_lk_reverse_key] = mod.attr(weight_hh_lk_reverse_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_reverse_key = std::string("bias_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string bias_hh_lk_reverse_key = std::string("bias_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[bias_ih_lk_reverse_key] = mod.attr(bias_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[bias_hh_lk_reverse_key] = mod.attr(bias_hh_lk_reverse_key).toTensor();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(GRU)
|
||||
|
||||
} // namespace pnnx
|
||||
67
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GroupNorm.cpp
vendored
Normal file
67
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GroupNorm.cpp
vendored
Normal file
@@ -0,0 +1,67 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class GroupNorm : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.normalization.GroupNorm";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.GroupNorm";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* gn = find_node_by_kind(graph, "aten::group_norm");
|
||||
|
||||
// for (auto aa : gn->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["num_groups"] = gn->namedInput("num_groups");
|
||||
op->params["eps"] = gn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_channels"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
else
|
||||
{
|
||||
fprintf(stderr, "Cannot resolve GroupNorm num_channels when affint=False\n");
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(GroupNorm)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardshrink.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardshrink.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardshrink : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardshrink";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardshrink";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* hardshrink = find_node_by_kind(graph, "aten::hardshrink");
|
||||
|
||||
op->params["lambd"] = hardshrink->namedInput("lambd");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardshrink)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardsigmoid.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardsigmoid.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardsigmoid : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardsigmoid";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardsigmoid";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardsigmoid)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardswish.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardswish.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardswish : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardswish";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardswish";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardswish)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardtanh.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardtanh.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardtanh : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardtanh";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardtanh";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* hardtanh = find_node_by_kind(graph, "aten::hardtanh");
|
||||
|
||||
op->params["min_val"] = hardtanh->namedInput("min_val");
|
||||
op->params["max_val"] = hardtanh->namedInput("max_val");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardtanh)
|
||||
|
||||
} // namespace pnnx
|
||||
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm1d.cpp
vendored
Normal file
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm1d.cpp
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class InstanceNorm1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.instancenorm.InstanceNorm1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.InstanceNorm1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* in = find_node_by_kind(graph, "aten::instance_norm");
|
||||
|
||||
// for (auto aa : in->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["eps"] = in->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
op->params["track_running_stats"] = mod.hasattr("running_mean") && mod.hasattr("running_var");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_features"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
|
||||
if (mod.hasattr("running_mean") && mod.hasattr("running_var"))
|
||||
{
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = mod.attr("running_var").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(InstanceNorm1d)
|
||||
|
||||
} // namespace pnnx
|
||||
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm2d.cpp
vendored
Normal file
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm2d.cpp
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class InstanceNorm2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.instancenorm.InstanceNorm2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.InstanceNorm2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* in = find_node_by_kind(graph, "aten::instance_norm");
|
||||
|
||||
// for (auto aa : in->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["eps"] = in->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
op->params["track_running_stats"] = mod.hasattr("running_mean") && mod.hasattr("running_var");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_features"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
|
||||
if (mod.hasattr("running_mean") && mod.hasattr("running_var"))
|
||||
{
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = mod.attr("running_var").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(InstanceNorm2d)
|
||||
|
||||
} // namespace pnnx
|
||||
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm3d.cpp
vendored
Normal file
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm3d.cpp
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class InstanceNorm3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.instancenorm.InstanceNorm3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.InstanceNorm3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* in = find_node_by_kind(graph, "aten::instance_norm");
|
||||
|
||||
// for (auto aa : in->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["eps"] = in->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
op->params["track_running_stats"] = mod.hasattr("running_mean") && mod.hasattr("running_var");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_features"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
|
||||
if (mod.hasattr("running_mean") && mod.hasattr("running_var"))
|
||||
{
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = mod.attr("running_var").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(InstanceNorm3d)
|
||||
|
||||
} // namespace pnnx
|
||||
56
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LPPool1d.cpp
vendored
Normal file
56
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LPPool1d.cpp
vendored
Normal file
@@ -0,0 +1,56 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LPPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.LPPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LPPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* pow = find_node_by_kind(graph, "aten::pow");
|
||||
op->params["norm_type"] = pow->inputs()[1];
|
||||
|
||||
const torch::jit::Node* avg_pool1d = find_node_by_kind(graph, "aten::avg_pool1d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool1d->namedInput("kernel_size")->node()->inputs()[0];
|
||||
if (avg_pool1d->namedInput("stride")->node()->inputs().size() == 0)
|
||||
{
|
||||
op->params["stride"] = op->params["kernel_size"];
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["stride"] = avg_pool1d->namedInput("stride")->node()->inputs()[0];
|
||||
}
|
||||
op->params["ceil_mode"] = avg_pool1d->namedInput("ceil_mode");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LPPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user