feat: 切换后端至PaddleOCR-NCNN,切换工程为CMake
1.项目后端整体迁移至PaddleOCR-NCNN算法,已通过基本的兼容性测试 2.工程改为使用CMake组织,后续为了更好地兼容第三方库,不再提供QMake工程 3.重整权利声明文件,重整代码工程,确保最小化侵权风险 Log: 切换后端至PaddleOCR-NCNN,切换工程为CMake Change-Id: I4d5d2c5d37505a4a24b389b1a4c5d12f17bfa38c
This commit is contained in:
70
3rdparty/ncnn/tools/pnnx/CMakeLists.txt
vendored
Normal file
70
3rdparty/ncnn/tools/pnnx/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,70 @@
|
||||
|
||||
if(NOT CMAKE_VERSION VERSION_LESS "3.15")
|
||||
# enable CMAKE_MSVC_RUNTIME_LIBRARY
|
||||
cmake_policy(SET CMP0091 NEW)
|
||||
endif()
|
||||
|
||||
project(pnnx)
|
||||
cmake_minimum_required(VERSION 3.12)
|
||||
|
||||
if(POLICY CMP0074)
|
||||
cmake_policy(SET CMP0074 NEW)
|
||||
endif()
|
||||
|
||||
if(MSVC AND NOT CMAKE_VERSION VERSION_LESS "3.15")
|
||||
option(PNNX_BUILD_WITH_STATIC_CRT "Enables use of statically linked CRT for statically linked pnnx" OFF)
|
||||
if(PNNX_BUILD_WITH_STATIC_CRT)
|
||||
# cmake before version 3.15 not work
|
||||
set(CMAKE_MSVC_RUNTIME_LIBRARY "MultiThreaded$<$<CONFIG:Debug>:Debug>")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
list(APPEND CMAKE_MODULE_PATH "${CMAKE_CURRENT_SOURCE_DIR}/cmake")
|
||||
include(PNNXPyTorch)
|
||||
|
||||
# c++14 is required for using torch headers
|
||||
set(CMAKE_CXX_STANDARD 14)
|
||||
|
||||
#set(CMAKE_BUILD_TYPE debug)
|
||||
#set(CMAKE_BUILD_TYPE relwithdebinfo)
|
||||
#set(CMAKE_BUILD_TYPE release)
|
||||
|
||||
option(PNNX_COVERAGE "build for coverage" OFF)
|
||||
|
||||
#set(Torch_INSTALL_DIR "/home/nihui/.local/lib/python3.9/site-packages/torch" CACHE STRING "")
|
||||
#set(Torch_INSTALL_DIR "/home/nihui/osd/pnnx/pytorch-v1.10.0/build/install" CACHE STRING "")
|
||||
#set(Torch_INSTALL_DIR "/home/nihui/osd/pnnx/libtorch" CACHE STRING "")
|
||||
set(TorchVision_INSTALL_DIR "/home/nihui/osd/vision/build/install" CACHE STRING "")
|
||||
|
||||
#set(Torch_DIR "${Torch_INSTALL_DIR}/share/cmake/Torch")
|
||||
set(TorchVision_DIR "${TorchVision_INSTALL_DIR}/share/cmake/TorchVision")
|
||||
|
||||
find_package(Python3 COMPONENTS Interpreter Development)
|
||||
|
||||
PNNXProbeForPyTorchInstall()
|
||||
find_package(Torch REQUIRED)
|
||||
|
||||
find_package(TorchVision QUIET)
|
||||
|
||||
message(STATUS "Torch_VERSION = ${Torch_VERSION}")
|
||||
message(STATUS "Torch_VERSION_MAJOR = ${Torch_VERSION_MAJOR}")
|
||||
message(STATUS "Torch_VERSION_MINOR = ${Torch_VERSION_MINOR}")
|
||||
message(STATUS "Torch_VERSION_PATCH = ${Torch_VERSION_PATCH}")
|
||||
|
||||
if(Torch_VERSION VERSION_LESS "1.8")
|
||||
message(FATAL_ERROR "pnnx only supports PyTorch >= 1.8")
|
||||
endif()
|
||||
|
||||
if(TorchVision_FOUND)
|
||||
message(STATUS "Building with TorchVision")
|
||||
add_definitions(-DPNNX_TORCHVISION)
|
||||
else()
|
||||
message(WARNING "Building without TorchVision")
|
||||
endif()
|
||||
|
||||
include_directories(${TORCH_INCLUDE_DIRS})
|
||||
|
||||
add_subdirectory(src)
|
||||
|
||||
enable_testing()
|
||||
add_subdirectory(tests)
|
||||
658
3rdparty/ncnn/tools/pnnx/README.md
vendored
Normal file
658
3rdparty/ncnn/tools/pnnx/README.md
vendored
Normal file
@@ -0,0 +1,658 @@
|
||||
# PNNX
|
||||
PyTorch Neural Network eXchange(PNNX) is an open standard for PyTorch model interoperability. PNNX provides an open model format for PyTorch. It defines computation graph as well as high level operators strictly matches PyTorch.
|
||||
|
||||
# Rationale
|
||||
PyTorch is currently one of the most popular machine learning frameworks. We need to deploy the trained AI model to various hardware and environments more conveniently and easily.
|
||||
|
||||
Before PNNX, we had the following methods:
|
||||
|
||||
1. export to ONNX, and deploy with ONNX-runtime
|
||||
2. export to ONNX, and convert onnx to inference-framework specific format, and deploy with TensorRT/OpenVINO/ncnn/etc.
|
||||
3. export to TorchScript, and deploy with libtorch
|
||||
|
||||
As far as we know, ONNX has the ability to express the PyTorch model and it is an open standard. People usually use ONNX as an intermediate representation between PyTorch and the inference platform. However, ONNX still has the following fatal problems, which makes the birth of PNNX necessary:
|
||||
|
||||
1. ONNX does not have a human-readable and editable file representation, making it difficult for users to easily modify the computation graph or add custom operators.
|
||||
2. The operator definition of ONNX is not completely in accordance with PyTorch. When exporting some PyTorch operators, glue operators are often added passively by ONNX, which makes the computation graph inconsistent with PyTorch and may impact the inference efficiency.
|
||||
3. There are a large number of additional parameters designed to be compatible with various ML frameworks in the operator definition in ONNX. These parameters increase the burden of inference implementation on hardware and software.
|
||||
|
||||
PNNX tries to define a set of operators and a simple and easy-to-use format that are completely contrasted with the python api of PyTorch, so that the conversion and interoperability of PyTorch models are more convenient.
|
||||
|
||||
# Features
|
||||
|
||||
1. [Human readable and editable format](#the-pnnxparam-format)
|
||||
2. [Plain model binary in storage zip](#the-pnnxbin-format)
|
||||
3. [One-to-one mapping of PNNX operators and PyTorch python api](#pnnx-operator)
|
||||
4. [Preserve math expression as one operator](#pnnx-expression-operator)
|
||||
5. [Preserve torch function as one operator](#pnnx-torch-function-operator)
|
||||
6. [Preserve miscellaneous module as one operator](#pnnx-module-operator)
|
||||
7. [Inference via exported PyTorch python code](#pnnx-python-inference)
|
||||
8. [Tensor shape propagation](#pnnx-shape-propagation)
|
||||
9. [Model optimization](#pnnx-model-optimization)
|
||||
10. [Custom operator support](#pnnx-custom-operator)
|
||||
|
||||
# Build TorchScript to PNNX converter
|
||||
|
||||
1. Install PyTorch and TorchVision c++ library
|
||||
2. Build PNNX with cmake
|
||||
|
||||
# Usage
|
||||
|
||||
1. Export your model to TorchScript
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torchvision.models as models
|
||||
|
||||
net = models.resnet18(pretrained=True)
|
||||
net = net.eval()
|
||||
|
||||
x = torch.rand(1, 3, 224, 224)
|
||||
|
||||
mod = torch.jit.trace(net, x)
|
||||
torch.jit.save(mod, "resnet18.pt")
|
||||
```
|
||||
|
||||
2. Convert TorchScript to PNNX
|
||||
|
||||
```shell
|
||||
pnnx resnet18.pt inputshape=[1,3,224,224]
|
||||
```
|
||||
|
||||
Normally, you will get six files
|
||||
|
||||
```resnet18.pnnx.param``` PNNX graph definition
|
||||
|
||||
```resnet18.pnnx.bin``` PNNX model weight
|
||||
|
||||
```resnet18_pnnx.py``` PyTorch script for inference, the python code for model construction and weight initialization
|
||||
|
||||
```resnet18.ncnn.param``` ncnn graph definition
|
||||
|
||||
```resnet18.ncnn.bin``` ncnn model weight
|
||||
|
||||
```resnet18_ncnn.py``` pyncnn script for inference
|
||||
|
||||
3. Visualize PNNX with Netron
|
||||
|
||||
Open https://netron.app/ in browser, and drag resnet18.pnnx.param into it.
|
||||
|
||||
4. PNNX command line options
|
||||
|
||||
```
|
||||
Usage: pnnx [model.pt] [(key=value)...]
|
||||
pnnxparam=model.pnnx.param
|
||||
pnnxbin=model.pnnx.bin
|
||||
pnnxpy=model_pnnx.py
|
||||
ncnnparam=model.ncnn.param
|
||||
ncnnbin=model.ncnn.bin
|
||||
ncnnpy=model_ncnn.py
|
||||
optlevel=2
|
||||
device=cpu/gpu
|
||||
inputshape=[1,3,224,224],...
|
||||
inputshape2=[1,3,320,320],...
|
||||
customop=/home/nihui/.cache/torch_extensions/fused/fused.so,...
|
||||
moduleop=models.common.Focus,models.yolo.Detect,...
|
||||
Sample usage: pnnx mobilenet_v2.pt inputshape=[1,3,224,224]
|
||||
pnnx yolov5s.pt inputshape=[1,3,640,640] inputshape2=[1,3,320,320] device=gpu moduleop=models.common.Focus,models.yolo.Detect
|
||||
```
|
||||
|
||||
Parameters:
|
||||
|
||||
`pnnxparam` (default="*.pnnx.param", * is the model name): PNNX graph definition file
|
||||
|
||||
`pnnxbin` (default="*.pnnx.bin"): PNNX model weight
|
||||
|
||||
`pnnxpy` (default="*_pnnx.py"): PyTorch script for inference, including model construction and weight initialization code
|
||||
|
||||
`ncnnparam` (default="*.ncnn.param"): ncnn graph definition
|
||||
|
||||
`ncnnbin` (default="*.ncnn.bin"): ncnn model weight
|
||||
|
||||
`ncnnpy` (default="*_ncnn.py"): pyncnn script for inference
|
||||
|
||||
`optlevel` (default=2): graph optimization level
|
||||
|
||||
| Option | Optimization level |
|
||||
|--------|---------------------------------|
|
||||
| 0 | do not apply optimization |
|
||||
| 1 | optimization for inference |
|
||||
| 2 | optimization more for inference |
|
||||
|
||||
`device` (default="cpu"): device type for the input in TorchScript model, cpu or gpu
|
||||
|
||||
`inputshape` (Optional): shapes of model inputs. It is used to resolve tensor shapes in model graph. for example, `[1,3,224,224]` for the model with only 1 input, `[1,3,224,224],[1,3,224,224]` for the model that have 2 inputs.
|
||||
|
||||
`inputshape2` (Optional): shapes of alternative model inputs, the format is identical to `inputshape`. Usually, it is used with `inputshape` to resolve dynamic shape (-1) in model graph.
|
||||
|
||||
`customop` (Optional): list of Torch extensions (dynamic library) for custom operators, separated by ",". For example, `/home/nihui/.cache/torch_extensions/fused/fused.so,...`
|
||||
|
||||
`moduleop` (Optional): list of modules to keep as one big operator, separated by ",". for example, `models.common.Focus,models.yolo.Detect`
|
||||
|
||||
# The pnnx.param format
|
||||
|
||||
### example
|
||||
```
|
||||
7767517
|
||||
4 3
|
||||
pnnx.Input input 0 1 0
|
||||
nn.Conv2d conv_0 1 1 0 1 bias=1 dilation=(1,1) groups=1 in_channels=12 kernel_size=(3,3) out_channels=16 padding=(0,0) stride=(1,1) @bias=(16)f32 @weight=(16,12,3,3)f32
|
||||
nn.Conv2d conv_1 1 1 1 2 bias=1 dilation=(1,1) groups=1 in_channels=16 kernel_size=(2,2) out_channels=20 padding=(2,2) stride=(2,2) @bias=(20)f32 @weight=(20,16,2,2)f32
|
||||
pnnx.Output output 1 0 2
|
||||
```
|
||||
### overview
|
||||
```
|
||||
[magic]
|
||||
```
|
||||
* magic number : 7767517
|
||||
```
|
||||
[operator count] [operand count]
|
||||
```
|
||||
* operator count : count of the operator line follows
|
||||
* operand count : count of all operands
|
||||
### operator line
|
||||
```
|
||||
[type] [name] [input count] [output count] [input operands] [output operands] [operator params]
|
||||
```
|
||||
* type : type name, such as Conv2d ReLU etc
|
||||
* name : name of this operator
|
||||
* input count : count of the operands this operator needs as input
|
||||
* output count : count of the operands this operator produces as output
|
||||
* input operands : name list of all the input blob names, separated by space
|
||||
* output operands : name list of all the output blob names, separated by space
|
||||
* operator params : key=value pair list, separated by space, operator weights are prefixed by ```@``` symbol, tensor shapes are prefixed by ```#``` symbol, input parameter keys are prefixed by ```$```
|
||||
|
||||
# The pnnx.bin format
|
||||
|
||||
pnnx.bin file is a zip file with store-only mode(no compression)
|
||||
|
||||
weight binary file has its name composed by operator name and weight name
|
||||
|
||||
For example, ```nn.Conv2d conv_0 1 1 0 1 bias=1 dilation=(1,1) groups=1 in_channels=12 kernel_size=(3,3) out_channels=16 padding=(0,0) stride=(1,1) @bias=(16) @weight=(16,12,3,3)``` would pull conv_0.weight and conv_0.bias into pnnx.bin zip archive.
|
||||
|
||||
weight binaries can be listed or modified with any archive application eg. 7zip
|
||||
|
||||
|
||||
|
||||
# PNNX operator
|
||||
PNNX always preserve operators from what PyTorch python api provides.
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
self.attention = nn.MultiheadAttention(embed_dim=256, num_heads=32)
|
||||
|
||||
def forward(self, x):
|
||||
x, _ = self.attention(x, x, x)
|
||||
return x
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|
|
||||
|----|---|---|
|
||||
|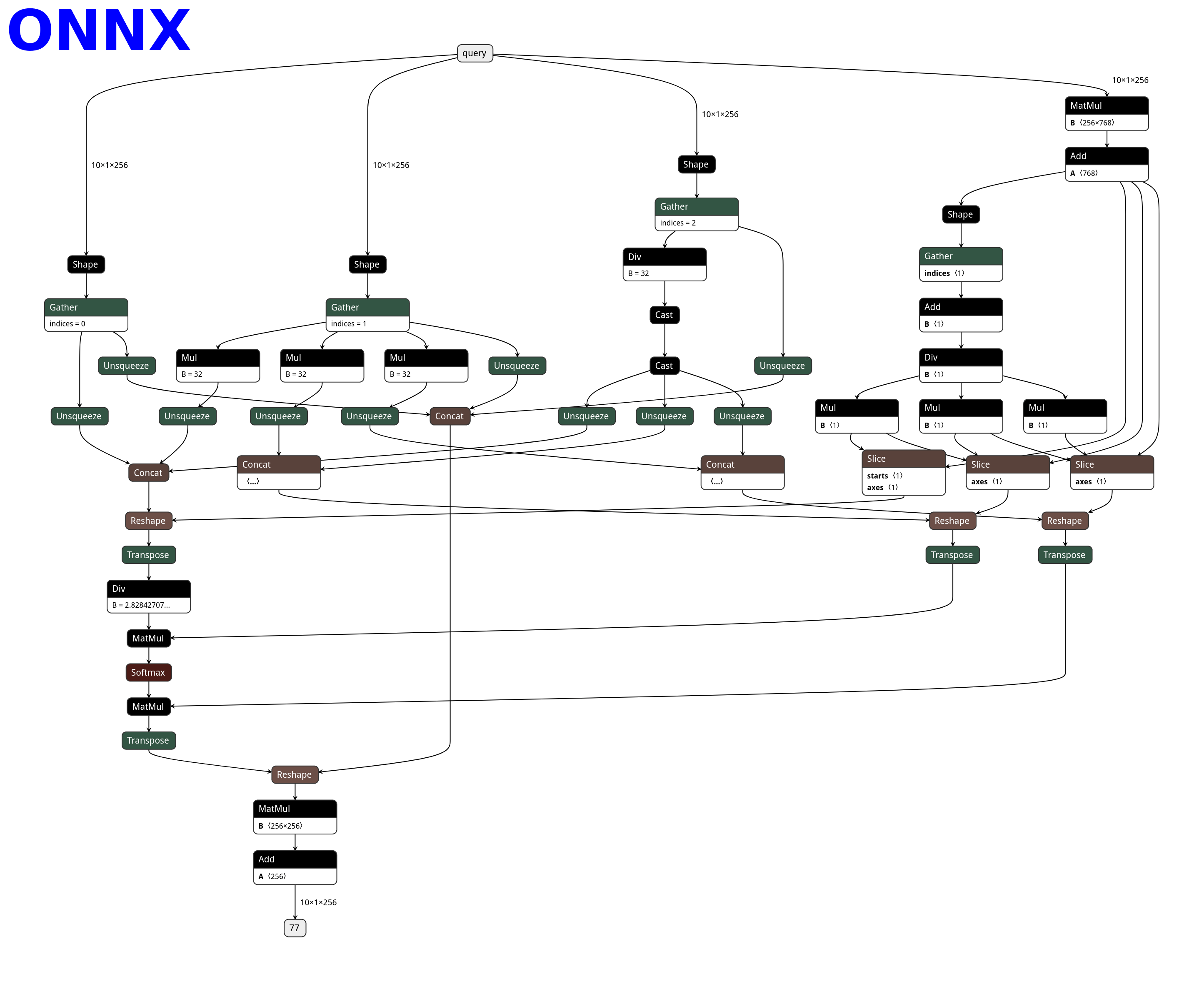|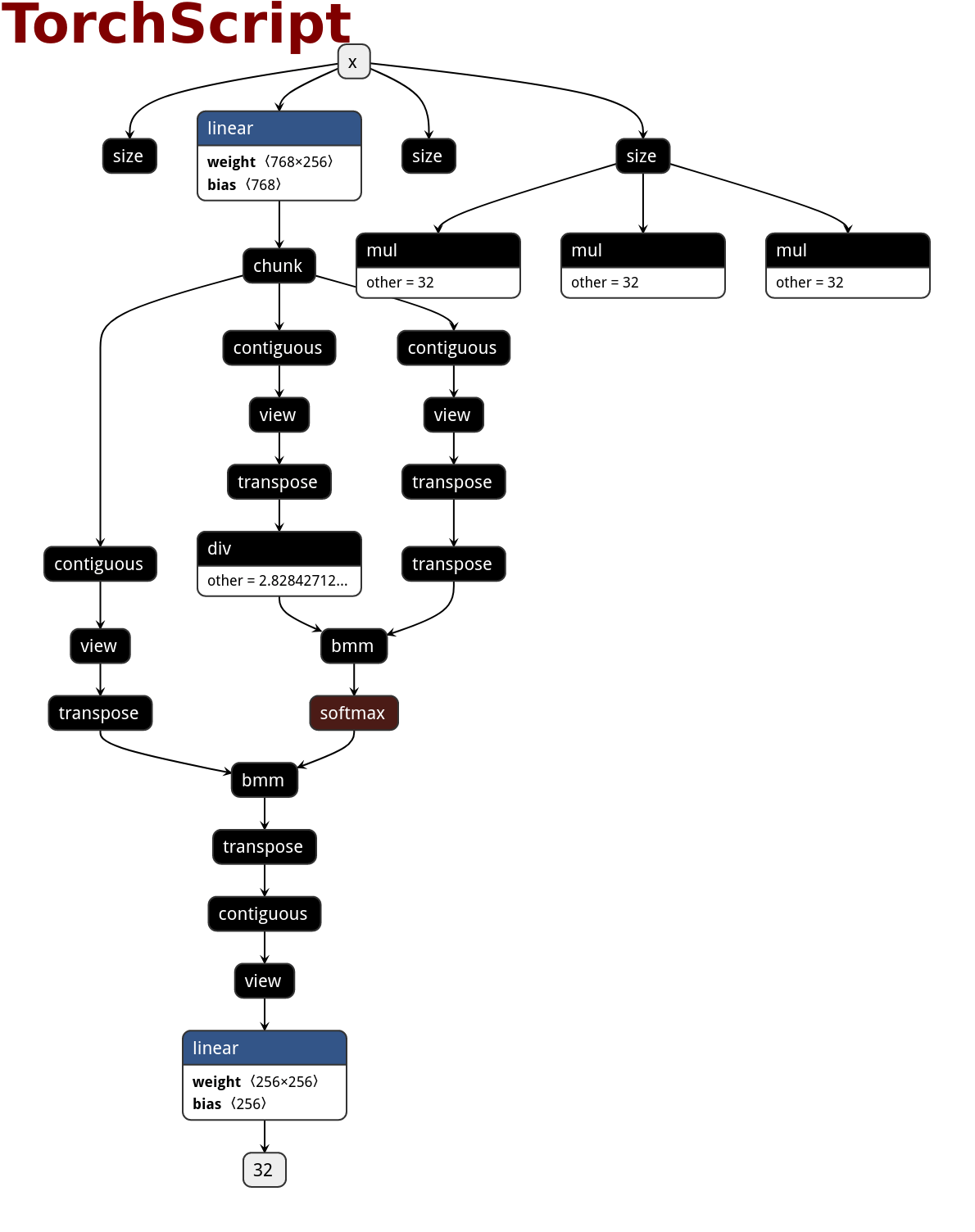|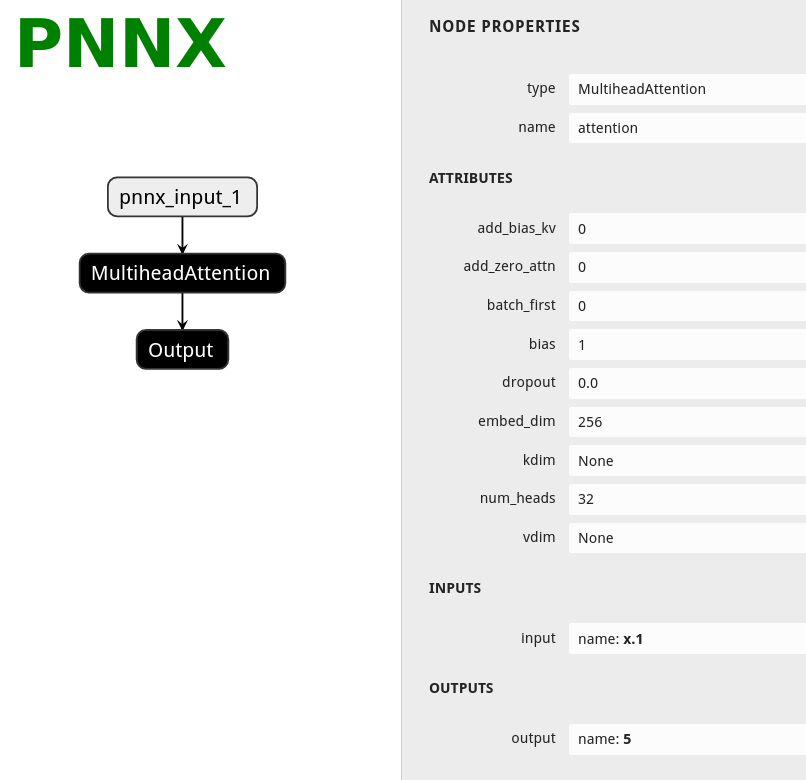|
|
||||
|
||||
# PNNX expression operator
|
||||
PNNX trys to preserve expression from what PyTorch python code writes.
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
def foo(x, y):
|
||||
return torch.sqrt((2 * x + y) / 12)
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|
|
||||
|---|---|---|
|
||||
|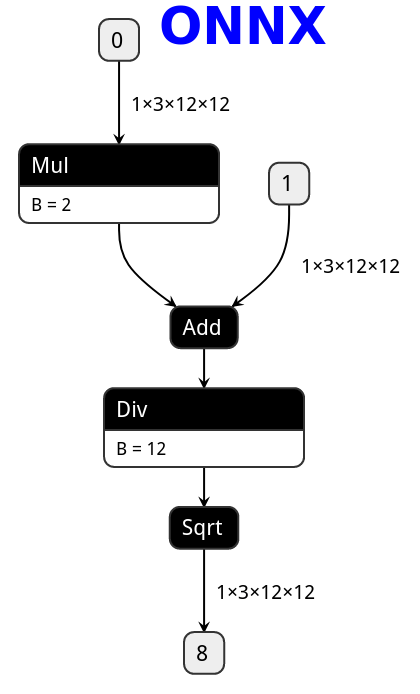|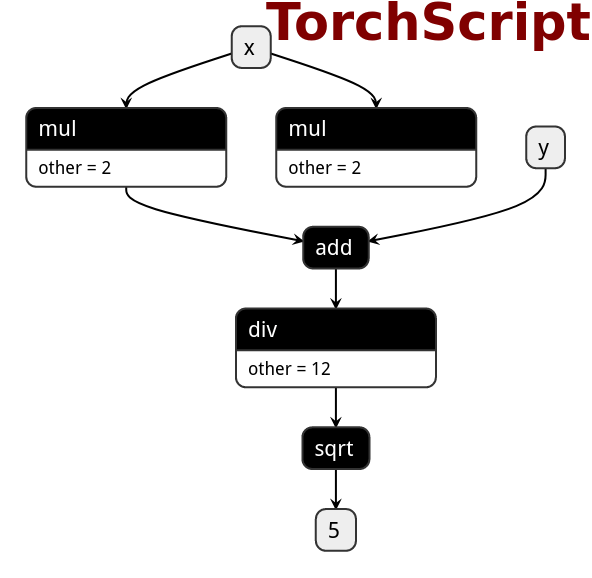||
|
||||
|
||||
# PNNX torch function operator
|
||||
PNNX trys to preserve torch functions and Tensor member functions as one operator from what PyTorch python api provides.
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
def forward(self, x):
|
||||
x = F.normalize(x, eps=1e-3)
|
||||
return x
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|
|
||||
|---|---|---|
|
||||
|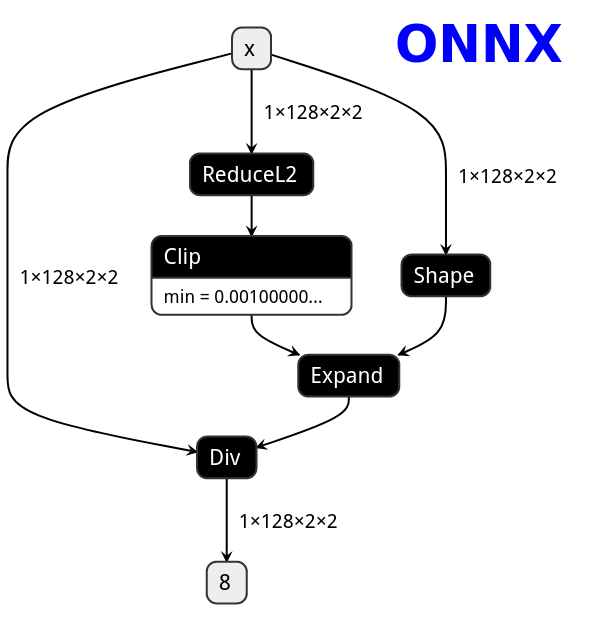|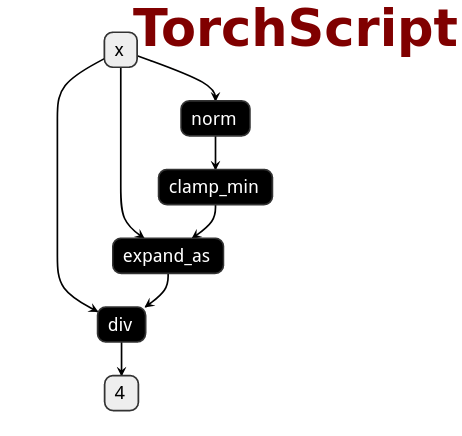||
|
||||
|
||||
|
||||
# PNNX module operator
|
||||
Users could ask PNNX to keep module as one big operator when it has complex logic.
|
||||
|
||||
The process is optional and could be enabled via moduleop command line option.
|
||||
|
||||
After pass_level0, all modules will be presented in terminal output, then you can pick the intersting ones as module operators.
|
||||
```
|
||||
############# pass_level0
|
||||
inline module = models.common.Bottleneck
|
||||
inline module = models.common.C3
|
||||
inline module = models.common.Concat
|
||||
inline module = models.common.Conv
|
||||
inline module = models.common.Focus
|
||||
inline module = models.common.SPP
|
||||
inline module = models.yolo.Detect
|
||||
inline module = utils.activations.SiLU
|
||||
```
|
||||
|
||||
```bash
|
||||
pnnx yolov5s.pt inputshape=[1,3,640,640] moduleop=models.common.Focus,models.yolo.Detect
|
||||
```
|
||||
|
||||
Here is the netron visualization comparision among ONNX, TorchScript and PNNX with the original PyTorch python code shown.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
class Focus(nn.Module):
|
||||
# Focus wh information into c-space
|
||||
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
||||
super().__init__()
|
||||
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
|
||||
|
||||
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
|
||||
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
|
||||
```
|
||||
|
||||
|ONNX|TorchScript|PNNX|PNNX with module operator|
|
||||
|---|---|---|---|
|
||||
|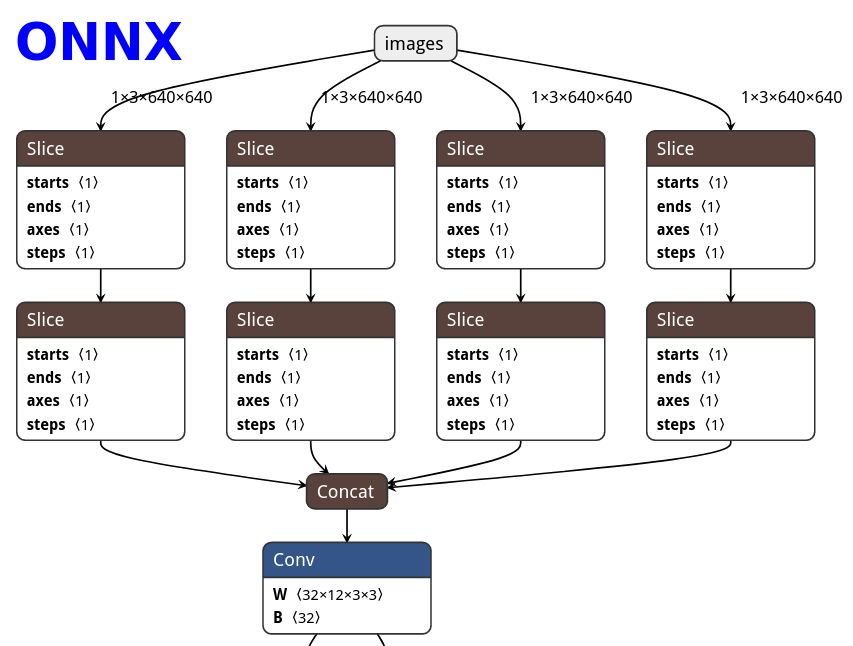|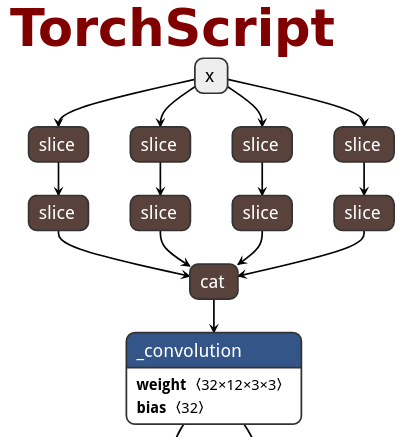|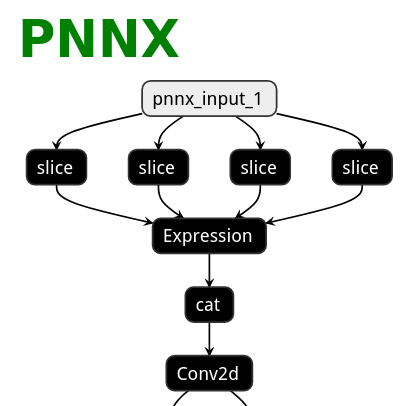|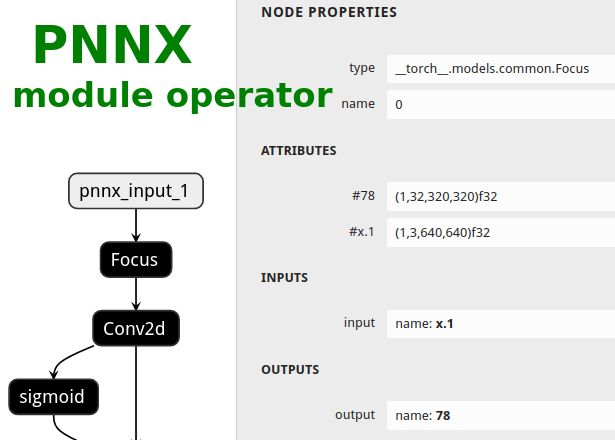|
|
||||
|
||||
|
||||
# PNNX python inference
|
||||
|
||||
A python script will be generated by default when converting torchscript to pnnx.
|
||||
|
||||
This script is the python code representation of PNNX and can be used for model inference.
|
||||
|
||||
There are some utility functions for loading weight binary from pnnx.bin.
|
||||
|
||||
You can even export the model torchscript AGAIN from this generated code!
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
self.linear_0 = nn.Linear(in_features=128, out_features=256, bias=True)
|
||||
self.linear_1 = nn.Linear(in_features=256, out_features=4, bias=True)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.linear_0(x)
|
||||
x = F.leaky_relu(x, 0.15)
|
||||
x = self.linear_1(x)
|
||||
return x
|
||||
```
|
||||
|
||||
```python
|
||||
import os
|
||||
import numpy as np
|
||||
import tempfile, zipfile
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(self):
|
||||
super(Model, self).__init__()
|
||||
|
||||
self.linear_0 = nn.Linear(bias=True, in_features=128, out_features=256)
|
||||
self.linear_1 = nn.Linear(bias=True, in_features=256, out_features=4)
|
||||
|
||||
archive = zipfile.ZipFile('../../function.pnnx.bin', 'r')
|
||||
self.linear_0.bias = self.load_pnnx_bin_as_parameter(archive, 'linear_0.bias', (256), 'float32')
|
||||
self.linear_0.weight = self.load_pnnx_bin_as_parameter(archive, 'linear_0.weight', (256,128), 'float32')
|
||||
self.linear_1.bias = self.load_pnnx_bin_as_parameter(archive, 'linear_1.bias', (4), 'float32')
|
||||
self.linear_1.weight = self.load_pnnx_bin_as_parameter(archive, 'linear_1.weight', (4,256), 'float32')
|
||||
archive.close()
|
||||
|
||||
def load_pnnx_bin_as_parameter(self, archive, key, shape, dtype):
|
||||
return nn.Parameter(self.load_pnnx_bin_as_tensor(archive, key, shape, dtype))
|
||||
|
||||
def load_pnnx_bin_as_tensor(self, archive, key, shape, dtype):
|
||||
_, tmppath = tempfile.mkstemp()
|
||||
tmpf = open(tmppath, 'wb')
|
||||
with archive.open(key) as keyfile:
|
||||
tmpf.write(keyfile.read())
|
||||
tmpf.close()
|
||||
m = np.memmap(tmppath, dtype=dtype, mode='r', shape=shape).copy()
|
||||
os.remove(tmppath)
|
||||
return torch.from_numpy(m)
|
||||
|
||||
def forward(self, v_x_1):
|
||||
v_7 = self.linear_0(v_x_1)
|
||||
v_input_1 = F.leaky_relu(input=v_7, negative_slope=0.150000)
|
||||
v_12 = self.linear_1(v_input_1)
|
||||
return v_12
|
||||
```
|
||||
|
||||
# PNNX shape propagation
|
||||
Users could ask PNNX to resolve all tensor shapes in model graph and constify some common expressions involved when tensor shapes are known.
|
||||
|
||||
The process is optional and could be enabled via inputshape command line option.
|
||||
|
||||
```bash
|
||||
pnnx shufflenet_v2_x1_0.pt inputshape=[1,3,224,224]
|
||||
```
|
||||
|
||||
```python
|
||||
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
|
||||
batchsize, num_channels, height, width = x.size()
|
||||
channels_per_group = num_channels // groups
|
||||
|
||||
# reshape
|
||||
x = x.view(batchsize, groups, channels_per_group, height, width)
|
||||
|
||||
x = torch.transpose(x, 1, 2).contiguous()
|
||||
|
||||
# flatten
|
||||
x = x.view(batchsize, -1, height, width)
|
||||
|
||||
return x
|
||||
```
|
||||
|
||||
|without shape propagation|with shape propagation|
|
||||
|---|---|
|
||||
|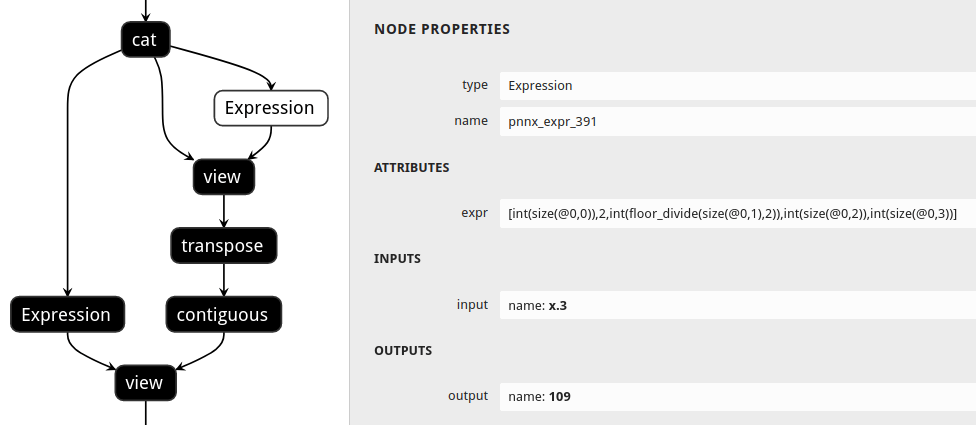|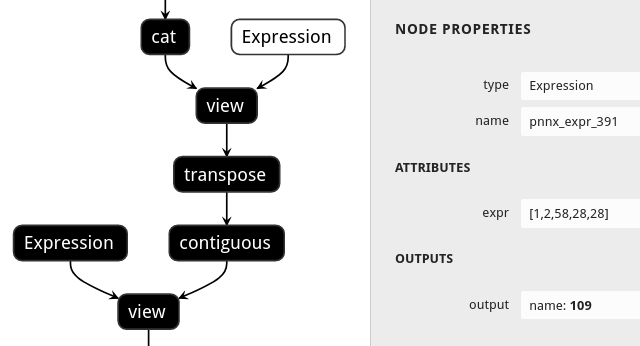|
|
||||
|
||||
|
||||
# PNNX model optimization
|
||||
|
||||
|ONNX|TorchScript|PNNX without optimization|PNNX with optimization|
|
||||
|---|---|---|---|
|
||||
|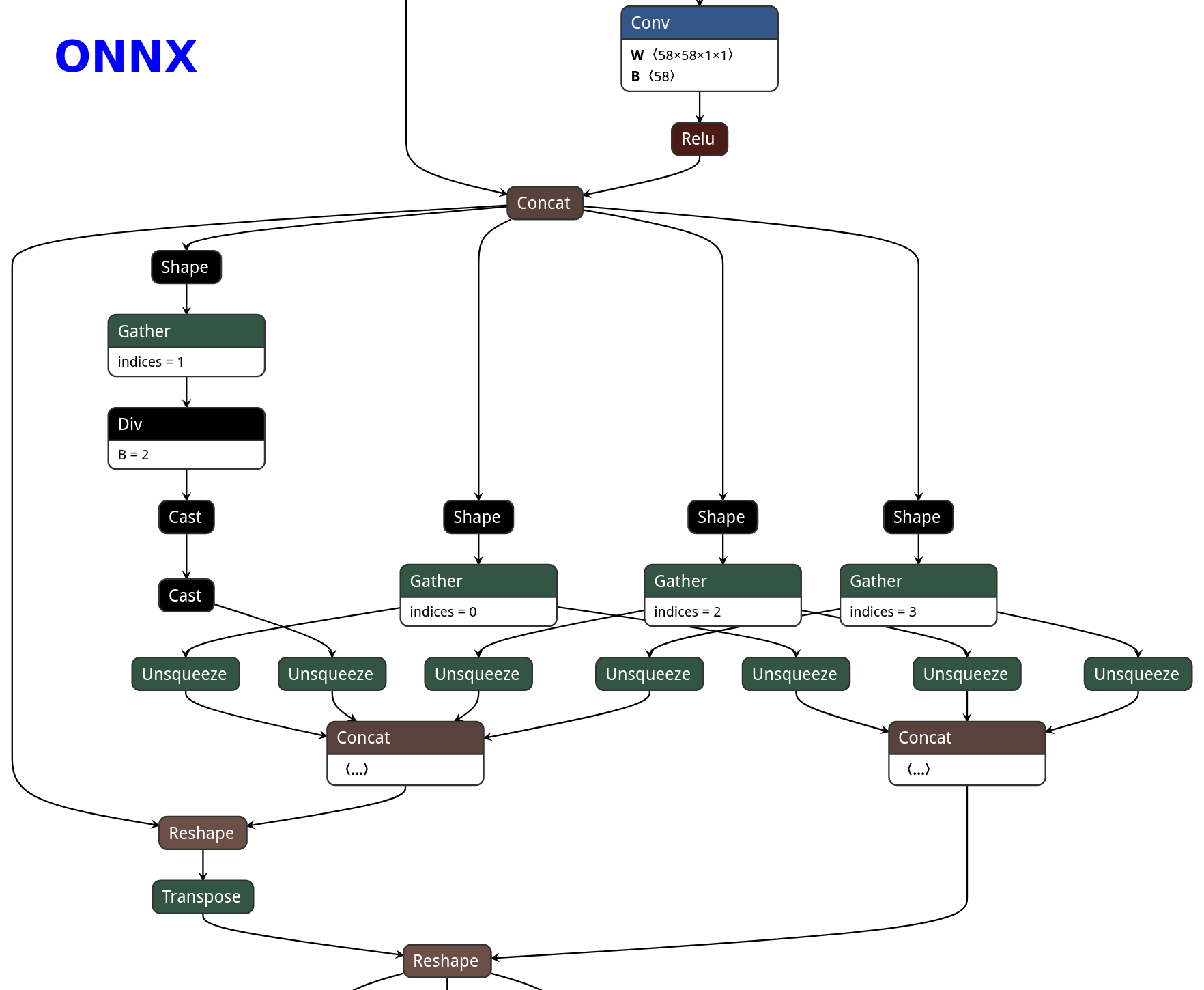|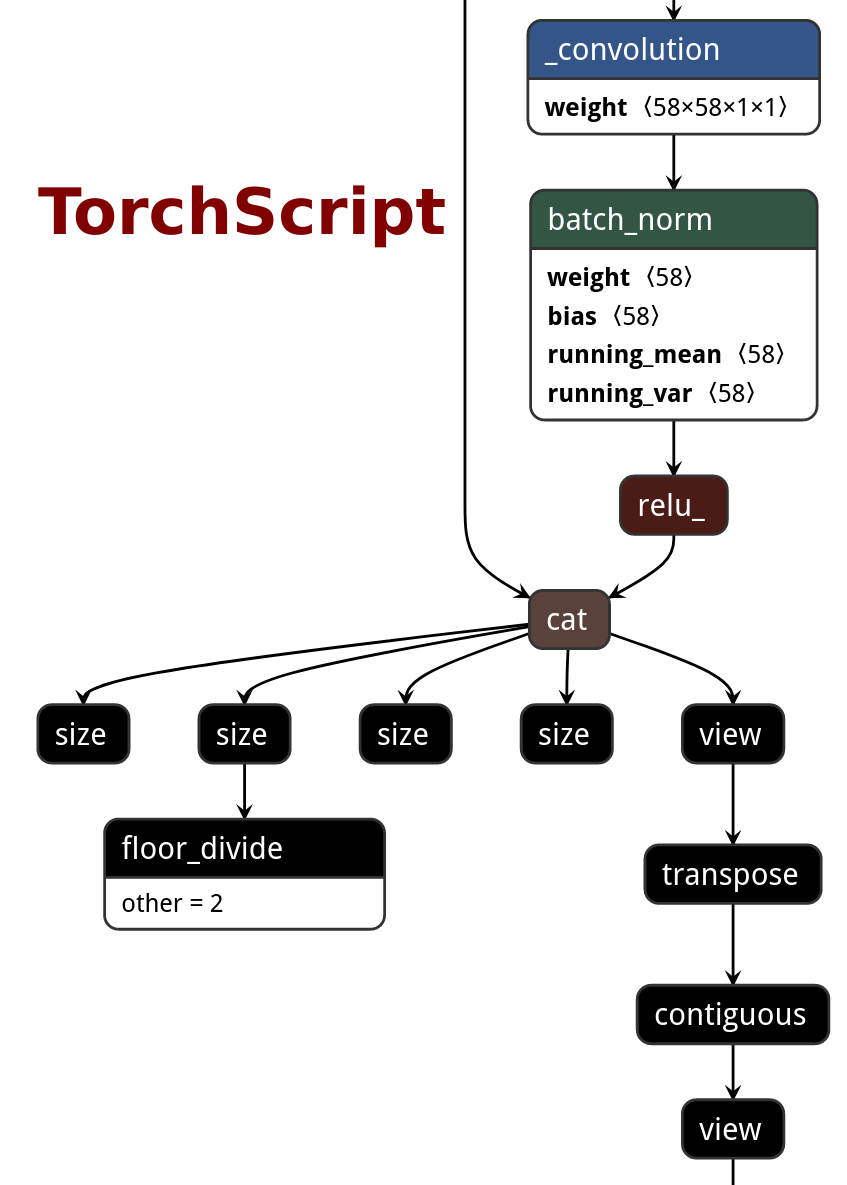|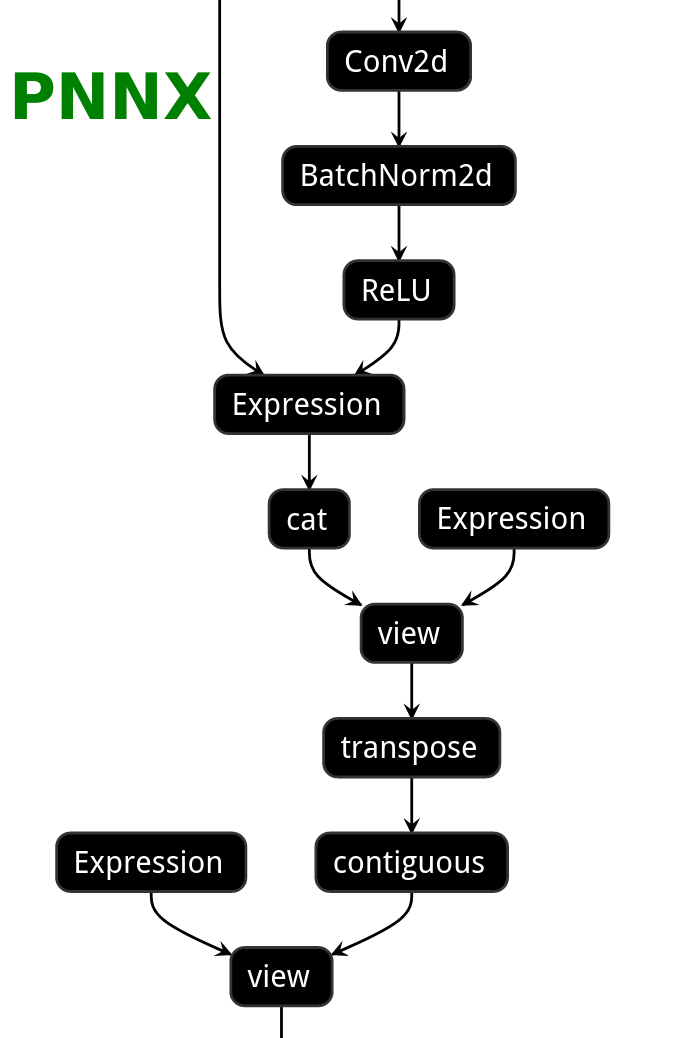|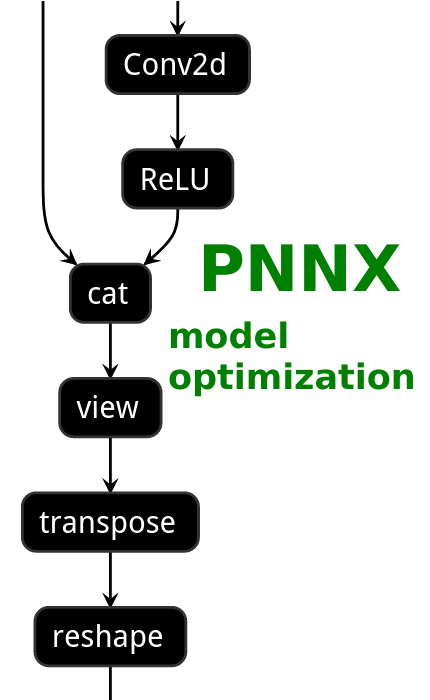|
|
||||
|
||||
|
||||
# PNNX custom operator
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
import torch
|
||||
from torch.autograd import Function
|
||||
from torch.utils.cpp_extension import load, _import_module_from_library
|
||||
|
||||
module_path = os.path.dirname(__file__)
|
||||
upfirdn2d_op = load(
|
||||
'upfirdn2d',
|
||||
sources=[
|
||||
os.path.join(module_path, 'upfirdn2d.cpp'),
|
||||
os.path.join(module_path, 'upfirdn2d_kernel.cu'),
|
||||
],
|
||||
is_python_module=False
|
||||
)
|
||||
|
||||
def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
|
||||
pad_x0 = pad[0]
|
||||
pad_x1 = pad[1]
|
||||
pad_y0 = pad[0]
|
||||
pad_y1 = pad[1]
|
||||
|
||||
kernel_h, kernel_w = kernel.shape
|
||||
batch, channel, in_h, in_w = input.shape
|
||||
|
||||
input = input.reshape(-1, in_h, in_w, 1)
|
||||
|
||||
out_h = (in_h * up + pad_y0 + pad_y1 - kernel_h) // down + 1
|
||||
out_w = (in_w * up + pad_x0 + pad_x1 - kernel_w) // down + 1
|
||||
|
||||
out = torch.ops.upfirdn2d_op.upfirdn2d(input, kernel, up, up, down, down, pad_x0, pad_x1, pad_y0, pad_y1)
|
||||
|
||||
out = out.view(-1, channel, out_h, out_w)
|
||||
|
||||
return out
|
||||
```
|
||||
|
||||
```cpp
|
||||
#include <torch/extension.h>
|
||||
|
||||
torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
|
||||
int64_t up_x, int64_t up_y, int64_t down_x, int64_t down_y,
|
||||
int64_t pad_x0, int64_t pad_x1, int64_t pad_y0, int64_t pad_y1) {
|
||||
// operator body
|
||||
}
|
||||
|
||||
TORCH_LIBRARY(upfirdn2d_op, m) {
|
||||
m.def("upfirdn2d", upfirdn2d);
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://raw.githubusercontent.com/nihui/ncnn-assets/master/pnnx/customop.pnnx.png" width="400" />
|
||||
|
||||
# Supported PyTorch operator status
|
||||
|
||||
| torch.nn | Is Supported | Export to ncnn |
|
||||
|---------------------------|----|---|
|
||||
|nn.AdaptiveAvgPool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveAvgPool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveAvgPool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveMaxPool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveMaxPool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AdaptiveMaxPool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AlphaDropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.AvgPool1d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.AvgPool2d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.AvgPool3d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.BatchNorm1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.BatchNorm2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.BatchNorm3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Bilinear | |
|
||||
|nn.CELU | :heavy_check_mark: |
|
||||
|nn.ChannelShuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConstantPad1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConstantPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConstantPad3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Conv1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Conv2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Conv3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConvTranspose1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConvTranspose2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ConvTranspose3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.CosineSimilarity | |
|
||||
|nn.Dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Dropout2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Dropout3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ELU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Embedding | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.EmbeddingBag | |
|
||||
|nn.Flatten | :heavy_check_mark: |
|
||||
|nn.Fold | |
|
||||
|nn.FractionalMaxPool2d | |
|
||||
|nn.FractionalMaxPool3d | |
|
||||
|nn.GELU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.GroupNorm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.GRU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.GRUCell | |
|
||||
|nn.Hardshrink | :heavy_check_mark: |
|
||||
|nn.Hardsigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Hardswish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Hardtanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Identity | |
|
||||
|nn.InstanceNorm1d | :heavy_check_mark: |
|
||||
|nn.InstanceNorm2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.InstanceNorm3d | :heavy_check_mark: |
|
||||
|nn.LayerNorm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LazyBatchNorm1d | |
|
||||
|nn.LazyBatchNorm2d | |
|
||||
|nn.LazyBatchNorm3d | |
|
||||
|nn.LazyConv1d | |
|
||||
|nn.LazyConv2d | |
|
||||
|nn.LazyConv3d | |
|
||||
|nn.LazyConvTranspose1d | |
|
||||
|nn.LazyConvTranspose2d | |
|
||||
|nn.LazyConvTranspose3d | |
|
||||
|nn.LazyLinear | |
|
||||
|nn.LeakyReLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Linear | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LocalResponseNorm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LogSigmoid | :heavy_check_mark: |
|
||||
|nn.LogSoftmax | :heavy_check_mark: |
|
||||
|nn.LPPool1d | :heavy_check_mark: |
|
||||
|nn.LPPool2d | :heavy_check_mark: |
|
||||
|nn.LSTM | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.LSTMCell | |
|
||||
|nn.MaxPool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MaxPool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MaxPool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MaxUnpool1d | |
|
||||
|nn.MaxUnpool2d | |
|
||||
|nn.MaxUnpool3d | |
|
||||
|nn.Mish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.MultiheadAttention | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.PairwiseDistance | |
|
||||
|nn.PixelShuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.PixelUnshuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.PReLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReflectionPad1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReflectionPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReLU6 | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReplicationPad1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReplicationPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ReplicationPad3d | :heavy_check_mark: |
|
||||
|nn.RNN | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|nn.RNNBase | |
|
||||
|nn.RNNCell | |
|
||||
|nn.RReLU | :heavy_check_mark: |
|
||||
|nn.SELU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Sigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.SiLU | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Softmax | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Softmax2d | |
|
||||
|nn.Softmin | :heavy_check_mark: |
|
||||
|nn.Softplus | :heavy_check_mark: |
|
||||
|nn.Softshrink | :heavy_check_mark: |
|
||||
|nn.Softsign | :heavy_check_mark: |
|
||||
|nn.SyncBatchNorm | |
|
||||
|nn.Tanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.Tanhshrink | :heavy_check_mark: |
|
||||
|nn.Threshold | :heavy_check_mark: |
|
||||
|nn.Transformer | |
|
||||
|nn.TransformerDecoder | |
|
||||
|nn.TransformerDecoderLayer | |
|
||||
|nn.TransformerEncoder | |
|
||||
|nn.TransformerEncoderLayer | |
|
||||
|nn.Unflatten | |
|
||||
|nn.Unfold | |
|
||||
|nn.Upsample | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.UpsamplingBilinear2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.UpsamplingNearest2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|nn.ZeroPad2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|
||||
|
||||
| torch.nn.functional | Is Supported | Export to ncnn |
|
||||
|---------------------------|----|----|
|
||||
|F.adaptive_avg_pool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_avg_pool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_avg_pool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_max_pool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_max_pool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.adaptive_max_pool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.affine_grid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.alpha_dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.avg_pool1d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.avg_pool2d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.avg_pool3d | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.batch_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.bilinear | |
|
||||
|F.celu | :heavy_check_mark: |
|
||||
|F.conv1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv_transpose1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv_transpose2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.conv_transpose3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.cosine_similarity | |
|
||||
|F.dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.dropout2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.dropout3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.elu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.elu_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.embedding | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.embedding_bag | |
|
||||
|F.feature_alpha_dropout | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.fold | |
|
||||
|F.fractional_max_pool2d | |
|
||||
|F.fractional_max_pool3d | |
|
||||
|F.gelu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.glu | |
|
||||
|F.grid_sample | :heavy_check_mark: |
|
||||
|F.group_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.gumbel_softmax | |
|
||||
|F.hardshrink | :heavy_check_mark: |
|
||||
|F.hardsigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.hardswish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.hardtanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.hardtanh_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.instance_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.interpolate | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.layer_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.leaky_relu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.leaky_relu_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.linear | :heavy_check_mark: | :heavy_check_mark:* |
|
||||
|F.local_response_norm | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.logsigmoid | :heavy_check_mark: |
|
||||
|F.log_softmax | :heavy_check_mark: |
|
||||
|F.lp_pool1d | :heavy_check_mark: |
|
||||
|F.lp_pool2d | :heavy_check_mark: |
|
||||
|F.max_pool1d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.max_pool2d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.max_pool3d | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.max_unpool1d | |
|
||||
|F.max_unpool2d | |
|
||||
|F.max_unpool3d | |
|
||||
|F.mish | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.normalize | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.one_hot | |
|
||||
|F.pad | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.pairwise_distance | |
|
||||
|F.pdist | |
|
||||
|F.pixel_shuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.pixel_unshuffle | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.prelu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.relu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.relu_ | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.relu6 | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.rrelu | :heavy_check_mark: |
|
||||
|F.rrelu_ | :heavy_check_mark: |
|
||||
|F.selu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.sigmoid | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.silu | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.softmax | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.softmin | :heavy_check_mark: |
|
||||
|F.softplus | :heavy_check_mark: |
|
||||
|F.softshrink | :heavy_check_mark: |
|
||||
|F.softsign | :heavy_check_mark: |
|
||||
|F.tanh | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.tanhshrink | :heavy_check_mark: |
|
||||
|F.threshold | :heavy_check_mark: |
|
||||
|F.threshold_ | :heavy_check_mark: |
|
||||
|F.unfold | |
|
||||
|F.upsample | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.upsample_bilinear | :heavy_check_mark: | :heavy_check_mark: |
|
||||
|F.upsample_nearest | :heavy_check_mark: | :heavy_check_mark: |
|
||||
32
3rdparty/ncnn/tools/pnnx/cmake/PNNXPyTorch.cmake
vendored
Normal file
32
3rdparty/ncnn/tools/pnnx/cmake/PNNXPyTorch.cmake
vendored
Normal file
@@ -0,0 +1,32 @@
|
||||
# reference to https://github.com/llvm/torch-mlir/blob/main/python/torch_mlir/dialects/torch/importer/jit_ir/cmake/modules/TorchMLIRPyTorch.cmake
|
||||
|
||||
# PNNXProbeForPyTorchInstall
|
||||
# Attempts to find a Torch installation and set the Torch_ROOT variable
|
||||
# based on introspecting the python environment. This allows a subsequent
|
||||
# call to find_package(Torch) to work.
|
||||
function(PNNXProbeForPyTorchInstall)
|
||||
if(Torch_ROOT)
|
||||
message(STATUS "Using cached Torch root = ${Torch_ROOT}")
|
||||
elseif(Torch_INSTALL_DIR)
|
||||
message(STATUS "Using cached Torch install dir = ${Torch_INSTALL_DIR}")
|
||||
set(Torch_DIR "${Torch_INSTALL_DIR}/share/cmake/Torch" CACHE STRING "Torch dir" FORCE)
|
||||
else()
|
||||
#find_package (Python3 COMPONENTS Interpreter Development)
|
||||
find_package (Python3)
|
||||
message(STATUS "Checking for PyTorch using ${Python3_EXECUTABLE} ...")
|
||||
execute_process(
|
||||
COMMAND "${Python3_EXECUTABLE}"
|
||||
-c "import os;import torch;print(torch.utils.cmake_prefix_path, end='')"
|
||||
WORKING_DIRECTORY ${CMAKE_CURRENT_SOURCE_DIR}
|
||||
RESULT_VARIABLE PYTORCH_STATUS
|
||||
OUTPUT_VARIABLE PYTORCH_PACKAGE_DIR)
|
||||
if(NOT PYTORCH_STATUS EQUAL "0")
|
||||
message(STATUS "Unable to 'import torch' with ${Python3_EXECUTABLE} (fallback to explicit config)")
|
||||
return()
|
||||
endif()
|
||||
message(STATUS "Found PyTorch installation at ${PYTORCH_PACKAGE_DIR}")
|
||||
|
||||
set(Torch_ROOT "${PYTORCH_PACKAGE_DIR}" CACHE STRING
|
||||
"Torch configure directory" FORCE)
|
||||
endif()
|
||||
endfunction()
|
||||
488
3rdparty/ncnn/tools/pnnx/src/CMakeLists.txt
vendored
Normal file
488
3rdparty/ncnn/tools/pnnx/src/CMakeLists.txt
vendored
Normal file
@@ -0,0 +1,488 @@
|
||||
|
||||
include_directories(${CMAKE_CURRENT_SOURCE_DIR})
|
||||
|
||||
set(pnnx_pass_level0_SRCS
|
||||
pass_level0/constant_unpooling.cpp
|
||||
pass_level0/inline_block.cpp
|
||||
pass_level0/shape_inference.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level1_SRCS
|
||||
pass_level1/nn_AdaptiveAvgPool1d.cpp
|
||||
pass_level1/nn_AdaptiveAvgPool2d.cpp
|
||||
pass_level1/nn_AdaptiveAvgPool3d.cpp
|
||||
pass_level1/nn_AdaptiveMaxPool1d.cpp
|
||||
pass_level1/nn_AdaptiveMaxPool2d.cpp
|
||||
pass_level1/nn_AdaptiveMaxPool3d.cpp
|
||||
pass_level1/nn_AlphaDropout.cpp
|
||||
pass_level1/nn_AvgPool1d.cpp
|
||||
pass_level1/nn_AvgPool2d.cpp
|
||||
pass_level1/nn_AvgPool3d.cpp
|
||||
pass_level1/nn_BatchNorm1d.cpp
|
||||
pass_level1/nn_BatchNorm2d.cpp
|
||||
pass_level1/nn_BatchNorm3d.cpp
|
||||
pass_level1/nn_CELU.cpp
|
||||
pass_level1/nn_ChannelShuffle.cpp
|
||||
pass_level1/nn_ConstantPad1d.cpp
|
||||
pass_level1/nn_ConstantPad2d.cpp
|
||||
pass_level1/nn_ConstantPad3d.cpp
|
||||
pass_level1/nn_Conv1d.cpp
|
||||
pass_level1/nn_Conv2d.cpp
|
||||
pass_level1/nn_Conv3d.cpp
|
||||
pass_level1/nn_ConvTranspose1d.cpp
|
||||
pass_level1/nn_ConvTranspose2d.cpp
|
||||
pass_level1/nn_ConvTranspose3d.cpp
|
||||
pass_level1/nn_Dropout.cpp
|
||||
pass_level1/nn_Dropout2d.cpp
|
||||
pass_level1/nn_Dropout3d.cpp
|
||||
pass_level1/nn_ELU.cpp
|
||||
pass_level1/nn_Embedding.cpp
|
||||
pass_level1/nn_GELU.cpp
|
||||
pass_level1/nn_GroupNorm.cpp
|
||||
pass_level1/nn_GRU.cpp
|
||||
pass_level1/nn_Hardshrink.cpp
|
||||
pass_level1/nn_Hardsigmoid.cpp
|
||||
pass_level1/nn_Hardswish.cpp
|
||||
pass_level1/nn_Hardtanh.cpp
|
||||
pass_level1/nn_InstanceNorm1d.cpp
|
||||
pass_level1/nn_InstanceNorm2d.cpp
|
||||
pass_level1/nn_InstanceNorm3d.cpp
|
||||
pass_level1/nn_LayerNorm.cpp
|
||||
pass_level1/nn_LeakyReLU.cpp
|
||||
pass_level1/nn_Linear.cpp
|
||||
pass_level1/nn_LocalResponseNorm.cpp
|
||||
pass_level1/nn_LogSigmoid.cpp
|
||||
pass_level1/nn_LogSoftmax.cpp
|
||||
pass_level1/nn_LPPool1d.cpp
|
||||
pass_level1/nn_LPPool2d.cpp
|
||||
pass_level1/nn_LSTM.cpp
|
||||
pass_level1/nn_MaxPool1d.cpp
|
||||
pass_level1/nn_MaxPool2d.cpp
|
||||
pass_level1/nn_MaxPool3d.cpp
|
||||
#pass_level1/nn_maxunpool2d.cpp
|
||||
pass_level1/nn_Mish.cpp
|
||||
pass_level1/nn_MultiheadAttention.cpp
|
||||
pass_level1/nn_PixelShuffle.cpp
|
||||
pass_level1/nn_PixelUnshuffle.cpp
|
||||
pass_level1/nn_PReLU.cpp
|
||||
pass_level1/nn_ReflectionPad1d.cpp
|
||||
pass_level1/nn_ReflectionPad2d.cpp
|
||||
pass_level1/nn_ReLU.cpp
|
||||
pass_level1/nn_ReLU6.cpp
|
||||
pass_level1/nn_ReplicationPad1d.cpp
|
||||
pass_level1/nn_ReplicationPad2d.cpp
|
||||
pass_level1/nn_ReplicationPad3d.cpp
|
||||
pass_level1/nn_RNN.cpp
|
||||
pass_level1/nn_RReLU.cpp
|
||||
pass_level1/nn_SELU.cpp
|
||||
pass_level1/nn_Sigmoid.cpp
|
||||
pass_level1/nn_SiLU.cpp
|
||||
pass_level1/nn_Softmax.cpp
|
||||
pass_level1/nn_Softmin.cpp
|
||||
pass_level1/nn_Softplus.cpp
|
||||
pass_level1/nn_Softshrink.cpp
|
||||
pass_level1/nn_Softsign.cpp
|
||||
pass_level1/nn_Tanh.cpp
|
||||
pass_level1/nn_Tanhshrink.cpp
|
||||
pass_level1/nn_Threshold.cpp
|
||||
pass_level1/nn_Upsample.cpp
|
||||
pass_level1/nn_UpsamplingBilinear2d.cpp
|
||||
pass_level1/nn_UpsamplingNearest2d.cpp
|
||||
pass_level1/nn_ZeroPad2d.cpp
|
||||
|
||||
pass_level1/nn_quantized_Conv2d.cpp
|
||||
pass_level1/nn_quantized_DeQuantize.cpp
|
||||
pass_level1/nn_quantized_Linear.cpp
|
||||
pass_level1/nn_quantized_Quantize.cpp
|
||||
|
||||
pass_level1/torchvision_DeformConv2d.cpp
|
||||
pass_level1/torchvision_RoIAlign.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level2_SRCS
|
||||
pass_level2/F_adaptive_avg_pool1d.cpp
|
||||
pass_level2/F_adaptive_avg_pool2d.cpp
|
||||
pass_level2/F_adaptive_avg_pool3d.cpp
|
||||
pass_level2/F_adaptive_max_pool1d.cpp
|
||||
pass_level2/F_adaptive_max_pool2d.cpp
|
||||
pass_level2/F_adaptive_max_pool3d.cpp
|
||||
pass_level2/F_alpha_dropout.cpp
|
||||
pass_level2/F_affine_grid.cpp
|
||||
pass_level2/F_avg_pool1d.cpp
|
||||
pass_level2/F_avg_pool2d.cpp
|
||||
pass_level2/F_avg_pool3d.cpp
|
||||
pass_level2/F_batch_norm.cpp
|
||||
pass_level2/F_celu.cpp
|
||||
pass_level2/F_conv1d.cpp
|
||||
pass_level2/F_conv2d.cpp
|
||||
pass_level2/F_conv3d.cpp
|
||||
pass_level2/F_conv_transpose123d.cpp
|
||||
pass_level2/F_dropout.cpp
|
||||
pass_level2/F_dropout23d.cpp
|
||||
pass_level2/F_elu.cpp
|
||||
pass_level2/F_embedding.cpp
|
||||
pass_level2/F_feature_alpha_dropout.cpp
|
||||
pass_level2/F_gelu.cpp
|
||||
pass_level2/F_grid_sample.cpp
|
||||
pass_level2/F_group_norm.cpp
|
||||
pass_level2/F_hardshrink.cpp
|
||||
pass_level2/F_hardsigmoid.cpp
|
||||
pass_level2/F_hardswish.cpp
|
||||
pass_level2/F_hardtanh.cpp
|
||||
pass_level2/F_instance_norm.cpp
|
||||
pass_level2/F_interpolate.cpp
|
||||
pass_level2/F_layer_norm.cpp
|
||||
pass_level2/F_leaky_relu.cpp
|
||||
pass_level2/F_linear.cpp
|
||||
pass_level2/F_local_response_norm.cpp
|
||||
pass_level2/F_log_softmax.cpp
|
||||
pass_level2/F_logsigmoid.cpp
|
||||
pass_level2/F_lp_pool1d.cpp
|
||||
pass_level2/F_lp_pool2d.cpp
|
||||
pass_level2/F_max_pool1d.cpp
|
||||
pass_level2/F_max_pool2d.cpp
|
||||
pass_level2/F_max_pool3d.cpp
|
||||
pass_level2/F_mish.cpp
|
||||
pass_level2/F_normalize.cpp
|
||||
pass_level2/F_pad.cpp
|
||||
pass_level2/F_pixel_shuffle.cpp
|
||||
pass_level2/F_pixel_unshuffle.cpp
|
||||
pass_level2/F_prelu.cpp
|
||||
pass_level2/F_relu.cpp
|
||||
pass_level2/F_relu6.cpp
|
||||
pass_level2/F_rrelu.cpp
|
||||
pass_level2/F_selu.cpp
|
||||
pass_level2/F_sigmoid.cpp
|
||||
pass_level2/F_silu.cpp
|
||||
pass_level2/F_softmax.cpp
|
||||
pass_level2/F_softmin.cpp
|
||||
pass_level2/F_softplus.cpp
|
||||
pass_level2/F_softshrink.cpp
|
||||
pass_level2/F_softsign.cpp
|
||||
pass_level2/F_tanh.cpp
|
||||
pass_level2/F_tanhshrink.cpp
|
||||
pass_level2/F_threshold.cpp
|
||||
pass_level2/F_upsample_bilinear.cpp
|
||||
pass_level2/F_upsample_nearest.cpp
|
||||
pass_level2/F_upsample.cpp
|
||||
pass_level2/Tensor_contiguous.cpp
|
||||
pass_level2/Tensor_expand.cpp
|
||||
pass_level2/Tensor_expand_as.cpp
|
||||
pass_level2/Tensor_index.cpp
|
||||
pass_level2/Tensor_new_empty.cpp
|
||||
pass_level2/Tensor_repeat.cpp
|
||||
pass_level2/Tensor_reshape.cpp
|
||||
pass_level2/Tensor_select.cpp
|
||||
pass_level2/Tensor_slice.cpp
|
||||
pass_level2/Tensor_view.cpp
|
||||
pass_level2/torch_addmm.cpp
|
||||
pass_level2/torch_amax.cpp
|
||||
pass_level2/torch_amin.cpp
|
||||
pass_level2/torch_arange.cpp
|
||||
pass_level2/torch_argmax.cpp
|
||||
pass_level2/torch_argmin.cpp
|
||||
pass_level2/torch_cat.cpp
|
||||
pass_level2/torch_chunk.cpp
|
||||
pass_level2/torch_clamp.cpp
|
||||
pass_level2/torch_clone.cpp
|
||||
pass_level2/torch_dequantize.cpp
|
||||
pass_level2/torch_empty.cpp
|
||||
pass_level2/torch_empty_like.cpp
|
||||
pass_level2/torch_flatten.cpp
|
||||
pass_level2/torch_flip.cpp
|
||||
pass_level2/torch_full.cpp
|
||||
pass_level2/torch_full_like.cpp
|
||||
pass_level2/torch_logsumexp.cpp
|
||||
pass_level2/torch_matmul.cpp
|
||||
pass_level2/torch_mean.cpp
|
||||
pass_level2/torch_norm.cpp
|
||||
pass_level2/torch_normal.cpp
|
||||
pass_level2/torch_ones.cpp
|
||||
pass_level2/torch_ones_like.cpp
|
||||
pass_level2/torch_prod.cpp
|
||||
pass_level2/torch_quantize_per_tensor.cpp
|
||||
pass_level2/torch_randn.cpp
|
||||
pass_level2/torch_randn_like.cpp
|
||||
pass_level2/torch_roll.cpp
|
||||
pass_level2/torch_split.cpp
|
||||
pass_level2/torch_squeeze.cpp
|
||||
pass_level2/torch_stack.cpp
|
||||
pass_level2/torch_sum.cpp
|
||||
pass_level2/torch_permute.cpp
|
||||
pass_level2/torch_transpose.cpp
|
||||
pass_level2/torch_unbind.cpp
|
||||
pass_level2/torch_unsqueeze.cpp
|
||||
pass_level2/torch_var.cpp
|
||||
pass_level2/torch_zeros.cpp
|
||||
pass_level2/torch_zeros_like.cpp
|
||||
|
||||
pass_level2/nn_quantized_FloatFunctional.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level3_SRCS
|
||||
pass_level3/assign_unique_name.cpp
|
||||
pass_level3/eliminate_noop_math.cpp
|
||||
pass_level3/eliminate_tuple_pair.cpp
|
||||
pass_level3/expand_quantization_modules.cpp
|
||||
pass_level3/fuse_cat_stack_tensors.cpp
|
||||
pass_level3/fuse_chunk_split_unbind_unpack.cpp
|
||||
pass_level3/fuse_expression.cpp
|
||||
pass_level3/fuse_index_expression.cpp
|
||||
pass_level3/fuse_rnn_unpack.cpp
|
||||
pass_level3/rename_F_conv_transposend.cpp
|
||||
pass_level3/rename_F_convmode.cpp
|
||||
pass_level3/rename_F_dropoutnd.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level4_SRCS
|
||||
pass_level4/canonicalize.cpp
|
||||
pass_level4/dead_code_elimination.cpp
|
||||
pass_level4/fuse_custom_op.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_level5_SRCS
|
||||
pass_level5/eliminate_dropout.cpp
|
||||
pass_level5/eliminate_identity_operator.cpp
|
||||
pass_level5/eliminate_maxpool_indices.cpp
|
||||
pass_level5/eliminate_noop_expression.cpp
|
||||
pass_level5/eliminate_noop_pad.cpp
|
||||
pass_level5/eliminate_slice.cpp
|
||||
pass_level5/eliminate_view_reshape.cpp
|
||||
pass_level5/eval_expression.cpp
|
||||
pass_level5/fold_constants.cpp
|
||||
pass_level5/fuse_channel_shuffle.cpp
|
||||
pass_level5/fuse_constant_expression.cpp
|
||||
pass_level5/fuse_conv1d_batchnorm1d.cpp
|
||||
pass_level5/fuse_conv2d_batchnorm2d.cpp
|
||||
pass_level5/fuse_convtranspose1d_batchnorm1d.cpp
|
||||
pass_level5/fuse_convtranspose2d_batchnorm2d.cpp
|
||||
pass_level5/fuse_contiguous_view.cpp
|
||||
pass_level5/fuse_linear_batchnorm1d.cpp
|
||||
pass_level5/fuse_select_to_unbind.cpp
|
||||
pass_level5/fuse_slice_indices.cpp
|
||||
pass_level5/unroll_rnn_op.cpp
|
||||
)
|
||||
|
||||
set(pnnx_pass_ncnn_SRCS
|
||||
pass_ncnn/convert_attribute.cpp
|
||||
pass_ncnn/convert_custom_op.cpp
|
||||
pass_ncnn/convert_half_to_float.cpp
|
||||
pass_ncnn/convert_input.cpp
|
||||
pass_ncnn/convert_torch_cat.cpp
|
||||
pass_ncnn/convert_torch_chunk.cpp
|
||||
pass_ncnn/convert_torch_split.cpp
|
||||
pass_ncnn/convert_torch_unbind.cpp
|
||||
pass_ncnn/eliminate_output.cpp
|
||||
pass_ncnn/expand_expression.cpp
|
||||
pass_ncnn/insert_split.cpp
|
||||
pass_ncnn/chain_multi_output.cpp
|
||||
pass_ncnn/solve_batch_index.cpp
|
||||
|
||||
pass_ncnn/eliminate_noop.cpp
|
||||
pass_ncnn/eliminate_tail_reshape_permute.cpp
|
||||
pass_ncnn/fuse_convolution_activation.cpp
|
||||
pass_ncnn/fuse_convolution1d_activation.cpp
|
||||
pass_ncnn/fuse_convolutiondepthwise_activation.cpp
|
||||
pass_ncnn/fuse_convolutiondepthwise1d_activation.cpp
|
||||
pass_ncnn/fuse_deconvolution_activation.cpp
|
||||
pass_ncnn/fuse_deconvolutiondepthwise_activation.cpp
|
||||
pass_ncnn/fuse_innerproduct_activation.cpp
|
||||
pass_ncnn/fuse_transpose_matmul.cpp
|
||||
pass_ncnn/insert_reshape_pooling.cpp
|
||||
|
||||
pass_ncnn/F_adaptive_avg_pool1d.cpp
|
||||
pass_ncnn/F_adaptive_avg_pool2d.cpp
|
||||
pass_ncnn/F_adaptive_avg_pool3d.cpp
|
||||
pass_ncnn/F_adaptive_max_pool1d.cpp
|
||||
pass_ncnn/F_adaptive_max_pool2d.cpp
|
||||
pass_ncnn/F_adaptive_max_pool3d.cpp
|
||||
pass_ncnn/F_avg_pool1d.cpp
|
||||
pass_ncnn/F_avg_pool2d.cpp
|
||||
pass_ncnn/F_avg_pool3d.cpp
|
||||
pass_ncnn/F_batch_norm.cpp
|
||||
pass_ncnn/F_conv_transpose1d.cpp
|
||||
pass_ncnn/F_conv_transpose2d.cpp
|
||||
pass_ncnn/F_conv_transpose3d.cpp
|
||||
pass_ncnn/F_conv1d.cpp
|
||||
pass_ncnn/F_conv2d.cpp
|
||||
pass_ncnn/F_conv3d.cpp
|
||||
pass_ncnn/F_elu.cpp
|
||||
pass_ncnn/F_embedding.cpp
|
||||
pass_ncnn/F_gelu.cpp
|
||||
pass_ncnn/F_group_norm.cpp
|
||||
pass_ncnn/F_hardsigmoid.cpp
|
||||
pass_ncnn/F_hardswish.cpp
|
||||
pass_ncnn/F_hardtanh.cpp
|
||||
pass_ncnn/F_instance_norm.cpp
|
||||
pass_ncnn/F_interpolate.cpp
|
||||
pass_ncnn/F_layer_norm.cpp
|
||||
pass_ncnn/F_leaky_relu.cpp
|
||||
pass_ncnn/F_linear.cpp
|
||||
pass_ncnn/F_local_response_norm.cpp
|
||||
pass_ncnn/F_max_pool1d.cpp
|
||||
pass_ncnn/F_max_pool2d.cpp
|
||||
pass_ncnn/F_max_pool3d.cpp
|
||||
pass_ncnn/F_mish.cpp
|
||||
pass_ncnn/F_normalize.cpp
|
||||
pass_ncnn/F_pad.cpp
|
||||
pass_ncnn/F_pixel_shuffle.cpp
|
||||
pass_ncnn/F_pixel_unshuffle.cpp
|
||||
pass_ncnn/F_prelu.cpp
|
||||
pass_ncnn/F_relu.cpp
|
||||
pass_ncnn/F_relu6.cpp
|
||||
pass_ncnn/F_selu.cpp
|
||||
pass_ncnn/F_sigmoid.cpp
|
||||
pass_ncnn/F_silu.cpp
|
||||
pass_ncnn/F_softmax.cpp
|
||||
pass_ncnn/F_tanh.cpp
|
||||
pass_ncnn/F_upsample_bilinear.cpp
|
||||
pass_ncnn/F_upsample_nearest.cpp
|
||||
pass_ncnn/F_upsample.cpp
|
||||
pass_ncnn/nn_AdaptiveAvgPool1d.cpp
|
||||
pass_ncnn/nn_AdaptiveAvgPool2d.cpp
|
||||
pass_ncnn/nn_AdaptiveAvgPool3d.cpp
|
||||
pass_ncnn/nn_AdaptiveMaxPool1d.cpp
|
||||
pass_ncnn/nn_AdaptiveMaxPool2d.cpp
|
||||
pass_ncnn/nn_AdaptiveMaxPool3d.cpp
|
||||
pass_ncnn/nn_AvgPool1d.cpp
|
||||
pass_ncnn/nn_AvgPool2d.cpp
|
||||
pass_ncnn/nn_AvgPool3d.cpp
|
||||
pass_ncnn/nn_BatchNorm1d.cpp
|
||||
pass_ncnn/nn_BatchNorm2d.cpp
|
||||
pass_ncnn/nn_BatchNorm3d.cpp
|
||||
pass_ncnn/nn_ChannelShuffle.cpp
|
||||
pass_ncnn/nn_ConstantPad1d.cpp
|
||||
pass_ncnn/nn_ConstantPad2d.cpp
|
||||
pass_ncnn/nn_ConstantPad3d.cpp
|
||||
pass_ncnn/nn_Conv1d.cpp
|
||||
pass_ncnn/nn_Conv2d.cpp
|
||||
pass_ncnn/nn_Conv3d.cpp
|
||||
pass_ncnn/nn_ConvTranspose1d.cpp
|
||||
pass_ncnn/nn_ConvTranspose2d.cpp
|
||||
pass_ncnn/nn_ConvTranspose3d.cpp
|
||||
pass_ncnn/nn_ELU.cpp
|
||||
pass_ncnn/nn_Embedding.cpp
|
||||
pass_ncnn/nn_GELU.cpp
|
||||
pass_ncnn/nn_GroupNorm.cpp
|
||||
pass_ncnn/nn_GRU.cpp
|
||||
pass_ncnn/nn_Hardsigmoid.cpp
|
||||
pass_ncnn/nn_Hardswish.cpp
|
||||
pass_ncnn/nn_Hardtanh.cpp
|
||||
pass_ncnn/nn_InstanceNorm2d.cpp
|
||||
pass_ncnn/nn_LayerNorm.cpp
|
||||
pass_ncnn/nn_LeakyReLU.cpp
|
||||
pass_ncnn/nn_Linear.cpp
|
||||
pass_ncnn/nn_LocalResponseNorm.cpp
|
||||
pass_ncnn/nn_LSTM.cpp
|
||||
pass_ncnn/nn_MaxPool1d.cpp
|
||||
pass_ncnn/nn_MaxPool2d.cpp
|
||||
pass_ncnn/nn_MaxPool3d.cpp
|
||||
pass_ncnn/nn_Mish.cpp
|
||||
pass_ncnn/nn_MultiheadAttention.cpp
|
||||
pass_ncnn/nn_PixelShuffle.cpp
|
||||
pass_ncnn/nn_PixelUnshuffle.cpp
|
||||
pass_ncnn/nn_PReLU.cpp
|
||||
pass_ncnn/nn_ReflectionPad1d.cpp
|
||||
pass_ncnn/nn_ReflectionPad2d.cpp
|
||||
pass_ncnn/nn_ReLU.cpp
|
||||
pass_ncnn/nn_ReLU6.cpp
|
||||
pass_ncnn/nn_ReplicationPad1d.cpp
|
||||
pass_ncnn/nn_ReplicationPad2d.cpp
|
||||
pass_ncnn/nn_RNN.cpp
|
||||
pass_ncnn/nn_SELU.cpp
|
||||
pass_ncnn/nn_Sigmoid.cpp
|
||||
pass_ncnn/nn_SiLU.cpp
|
||||
pass_ncnn/nn_Softmax.cpp
|
||||
pass_ncnn/nn_Tanh.cpp
|
||||
pass_ncnn/nn_Upsample.cpp
|
||||
pass_ncnn/nn_UpsamplingBilinear2d.cpp
|
||||
pass_ncnn/nn_UpsamplingNearest2d.cpp
|
||||
pass_ncnn/nn_ZeroPad2d.cpp
|
||||
pass_ncnn/Tensor_contiguous.cpp
|
||||
pass_ncnn/Tensor_reshape.cpp
|
||||
pass_ncnn/Tensor_repeat.cpp
|
||||
pass_ncnn/Tensor_slice.cpp
|
||||
pass_ncnn/Tensor_view.cpp
|
||||
pass_ncnn/torch_addmm.cpp
|
||||
pass_ncnn/torch_amax.cpp
|
||||
pass_ncnn/torch_amin.cpp
|
||||
pass_ncnn/torch_clamp.cpp
|
||||
pass_ncnn/torch_clone.cpp
|
||||
pass_ncnn/torch_flatten.cpp
|
||||
pass_ncnn/torch_logsumexp.cpp
|
||||
pass_ncnn/torch_matmul.cpp
|
||||
pass_ncnn/torch_mean.cpp
|
||||
pass_ncnn/torch_permute.cpp
|
||||
pass_ncnn/torch_prod.cpp
|
||||
pass_ncnn/torch_squeeze.cpp
|
||||
pass_ncnn/torch_sum.cpp
|
||||
pass_ncnn/torch_transpose.cpp
|
||||
pass_ncnn/torch_unsqueeze.cpp
|
||||
)
|
||||
|
||||
set(pnnx_SRCS
|
||||
main.cpp
|
||||
ir.cpp
|
||||
storezip.cpp
|
||||
utils.cpp
|
||||
|
||||
pass_level0.cpp
|
||||
pass_level1.cpp
|
||||
pass_level2.cpp
|
||||
pass_level3.cpp
|
||||
pass_level4.cpp
|
||||
pass_level5.cpp
|
||||
|
||||
pass_ncnn.cpp
|
||||
|
||||
${pnnx_pass_level0_SRCS}
|
||||
${pnnx_pass_level1_SRCS}
|
||||
${pnnx_pass_level2_SRCS}
|
||||
${pnnx_pass_level3_SRCS}
|
||||
${pnnx_pass_level4_SRCS}
|
||||
${pnnx_pass_level5_SRCS}
|
||||
|
||||
${pnnx_pass_ncnn_SRCS}
|
||||
)
|
||||
|
||||
if(NOT MSVC)
|
||||
add_definitions(-Wall -Wextra)
|
||||
endif()
|
||||
|
||||
add_executable(pnnx ${pnnx_SRCS})
|
||||
|
||||
if(PNNX_COVERAGE)
|
||||
target_compile_options(pnnx PUBLIC -coverage -fprofile-arcs -ftest-coverage)
|
||||
target_link_libraries(pnnx PUBLIC -coverage -lgcov)
|
||||
endif()
|
||||
|
||||
if(WIN32)
|
||||
target_compile_definitions(pnnx PUBLIC NOMINMAX)
|
||||
endif()
|
||||
|
||||
if(TorchVision_FOUND)
|
||||
target_link_libraries(pnnx PRIVATE TorchVision::TorchVision)
|
||||
endif()
|
||||
|
||||
if(WIN32)
|
||||
target_link_libraries(pnnx PRIVATE ${TORCH_LIBRARIES})
|
||||
else()
|
||||
target_link_libraries(pnnx PRIVATE ${TORCH_LIBRARIES} pthread dl)
|
||||
endif()
|
||||
|
||||
#set_target_properties(pnnx PROPERTIES COMPILE_FLAGS -fsanitize=address)
|
||||
#set_target_properties(pnnx PROPERTIES LINK_FLAGS -fsanitize=address)
|
||||
|
||||
if(APPLE)
|
||||
set_target_properties(pnnx PROPERTIES INSTALL_RPATH "@executable_path/")
|
||||
else()
|
||||
set_target_properties(pnnx PROPERTIES INSTALL_RPATH "$ORIGIN/")
|
||||
endif()
|
||||
set_target_properties(pnnx PROPERTIES MACOSX_RPATH TRUE)
|
||||
|
||||
install(TARGETS pnnx RUNTIME DESTINATION bin)
|
||||
|
||||
if (WIN32)
|
||||
file(GLOB TORCH_DLL "${TORCH_INSTALL_PREFIX}/lib/*.dll")
|
||||
install(FILES ${TORCH_DLL} DESTINATION bin)
|
||||
endif()
|
||||
2597
3rdparty/ncnn/tools/pnnx/src/ir.cpp
vendored
Normal file
2597
3rdparty/ncnn/tools/pnnx/src/ir.cpp
vendored
Normal file
File diff suppressed because it is too large
Load Diff
242
3rdparty/ncnn/tools/pnnx/src/ir.h
vendored
Normal file
242
3rdparty/ncnn/tools/pnnx/src/ir.h
vendored
Normal file
@@ -0,0 +1,242 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef PNNX_IR_H
|
||||
#define PNNX_IR_H
|
||||
|
||||
#include <initializer_list>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
namespace torch {
|
||||
namespace jit {
|
||||
struct Value;
|
||||
struct Node;
|
||||
} // namespace jit
|
||||
} // namespace torch
|
||||
namespace at {
|
||||
class Tensor;
|
||||
}
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Parameter
|
||||
{
|
||||
public:
|
||||
Parameter()
|
||||
: type(0)
|
||||
{
|
||||
}
|
||||
Parameter(bool _b)
|
||||
: type(1), b(_b)
|
||||
{
|
||||
}
|
||||
Parameter(int _i)
|
||||
: type(2), i(_i)
|
||||
{
|
||||
}
|
||||
Parameter(long _l)
|
||||
: type(2), i(_l)
|
||||
{
|
||||
}
|
||||
Parameter(long long _l)
|
||||
: type(2), i(_l)
|
||||
{
|
||||
}
|
||||
Parameter(float _f)
|
||||
: type(3), f(_f)
|
||||
{
|
||||
}
|
||||
Parameter(double _d)
|
||||
: type(3), f(_d)
|
||||
{
|
||||
}
|
||||
Parameter(const char* _s)
|
||||
: type(4), s(_s)
|
||||
{
|
||||
}
|
||||
Parameter(const std::string& _s)
|
||||
: type(4), s(_s)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<int>& _ai)
|
||||
: type(5), ai(_ai)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<int64_t>& _ai)
|
||||
: type(5)
|
||||
{
|
||||
for (const auto& x : _ai)
|
||||
ai.push_back((int)x);
|
||||
}
|
||||
Parameter(const std::vector<int>& _ai)
|
||||
: type(5), ai(_ai)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<float>& _af)
|
||||
: type(6), af(_af)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<double>& _af)
|
||||
: type(6)
|
||||
{
|
||||
for (const auto& x : _af)
|
||||
af.push_back((float)x);
|
||||
}
|
||||
Parameter(const std::vector<float>& _af)
|
||||
: type(6), af(_af)
|
||||
{
|
||||
}
|
||||
Parameter(const std::initializer_list<const char*>& _as)
|
||||
: type(7)
|
||||
{
|
||||
for (const auto& x : _as)
|
||||
as.push_back(std::string(x));
|
||||
}
|
||||
Parameter(const std::initializer_list<std::string>& _as)
|
||||
: type(7), as(_as)
|
||||
{
|
||||
}
|
||||
Parameter(const std::vector<std::string>& _as)
|
||||
: type(7), as(_as)
|
||||
{
|
||||
}
|
||||
|
||||
Parameter(const torch::jit::Node* value_node);
|
||||
Parameter(const torch::jit::Value* value);
|
||||
|
||||
static Parameter parse_from_string(const std::string& value);
|
||||
|
||||
// 0=null 1=b 2=i 3=f 4=s 5=ai 6=af 7=as 8=others
|
||||
int type;
|
||||
|
||||
// value
|
||||
bool b;
|
||||
int i;
|
||||
float f;
|
||||
std::string s;
|
||||
std::vector<int> ai;
|
||||
std::vector<float> af;
|
||||
std::vector<std::string> as;
|
||||
};
|
||||
|
||||
bool operator==(const Parameter& lhs, const Parameter& rhs);
|
||||
|
||||
class Attribute
|
||||
{
|
||||
public:
|
||||
Attribute()
|
||||
: type(0)
|
||||
{
|
||||
}
|
||||
|
||||
Attribute(const at::Tensor& t);
|
||||
|
||||
Attribute(const std::initializer_list<int>& shape, const std::vector<float>& t);
|
||||
|
||||
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8 9=bool
|
||||
int type;
|
||||
std::vector<int> shape;
|
||||
|
||||
std::vector<char> data;
|
||||
};
|
||||
|
||||
bool operator==(const Attribute& lhs, const Attribute& rhs);
|
||||
|
||||
// concat two attributes along the first axis
|
||||
Attribute operator+(const Attribute& a, const Attribute& b);
|
||||
|
||||
class Operator;
|
||||
class Operand
|
||||
{
|
||||
public:
|
||||
void remove_consumer(const Operator* c);
|
||||
|
||||
std::string name;
|
||||
|
||||
Operator* producer;
|
||||
std::vector<Operator*> consumers;
|
||||
|
||||
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8
|
||||
int type;
|
||||
std::vector<int> shape;
|
||||
|
||||
std::map<std::string, Parameter> params;
|
||||
|
||||
private:
|
||||
friend class Graph;
|
||||
Operand()
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
class Operator
|
||||
{
|
||||
public:
|
||||
std::string type;
|
||||
std::string name;
|
||||
|
||||
std::vector<Operand*> inputs;
|
||||
std::vector<Operand*> outputs;
|
||||
|
||||
std::vector<std::string> inputnames;
|
||||
std::map<std::string, Parameter> params;
|
||||
std::map<std::string, Attribute> attrs;
|
||||
|
||||
private:
|
||||
friend class Graph;
|
||||
Operator()
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
class Graph
|
||||
{
|
||||
public:
|
||||
Graph();
|
||||
~Graph();
|
||||
|
||||
int load(const std::string& parampath, const std::string& binpath);
|
||||
int save(const std::string& parampath, const std::string& binpath);
|
||||
|
||||
int python(const std::string& pypath, const std::string& binpath);
|
||||
|
||||
int ncnn(const std::string& parampath, const std::string& binpath, const std::string& pypath);
|
||||
|
||||
int parse(const std::string& param);
|
||||
|
||||
Operator* new_operator(const std::string& type, const std::string& name);
|
||||
|
||||
Operator* new_operator_before(const std::string& type, const std::string& name, const Operator* cur);
|
||||
|
||||
Operator* new_operator_after(const std::string& type, const std::string& name, const Operator* cur);
|
||||
|
||||
Operand* new_operand(const torch::jit::Value* v);
|
||||
|
||||
Operand* new_operand(const std::string& name);
|
||||
|
||||
Operand* get_operand(const std::string& name);
|
||||
|
||||
std::vector<Operator*> ops;
|
||||
std::vector<Operand*> operands;
|
||||
|
||||
private:
|
||||
Graph(const Graph& rhs);
|
||||
Graph& operator=(const Graph& rhs);
|
||||
};
|
||||
|
||||
} // namespace pnnx
|
||||
|
||||
#endif // PNNX_IR_H
|
||||
396
3rdparty/ncnn/tools/pnnx/src/main.cpp
vendored
Normal file
396
3rdparty/ncnn/tools/pnnx/src/main.cpp
vendored
Normal file
@@ -0,0 +1,396 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <stdio.h>
|
||||
|
||||
#if _WIN32
|
||||
#include <windows.h>
|
||||
#else
|
||||
#include <dlfcn.h>
|
||||
#endif
|
||||
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
#include <torch/script.h>
|
||||
|
||||
#ifdef PNNX_TORCHVISION
|
||||
// register torchvision ops via including headers
|
||||
#include <torchvision/vision.h>
|
||||
#endif
|
||||
|
||||
#include "ir.h"
|
||||
#include "pass_level0.h"
|
||||
#include "pass_level1.h"
|
||||
#include "pass_level2.h"
|
||||
#include "pass_level3.h"
|
||||
#include "pass_level4.h"
|
||||
#include "pass_level5.h"
|
||||
|
||||
#include "pass_ncnn.h"
|
||||
|
||||
static std::string get_basename(const std::string& path)
|
||||
{
|
||||
return path.substr(0, path.find_last_of('.'));
|
||||
}
|
||||
|
||||
static void parse_string_list(char* s, std::vector<std::string>& list)
|
||||
{
|
||||
list.clear();
|
||||
|
||||
char* pch = strtok(s, ",");
|
||||
while (pch != NULL)
|
||||
{
|
||||
list.push_back(std::string(pch));
|
||||
|
||||
pch = strtok(NULL, ",");
|
||||
}
|
||||
}
|
||||
|
||||
static void print_string_list(const std::vector<std::string>& list)
|
||||
{
|
||||
for (size_t i = 0; i < list.size(); i++)
|
||||
{
|
||||
fprintf(stderr, "%s", list[i].c_str());
|
||||
if (i + 1 != list.size())
|
||||
fprintf(stderr, ",");
|
||||
}
|
||||
}
|
||||
|
||||
static void parse_shape_list(char* s, std::vector<std::vector<int64_t> >& shapes, std::vector<std::string>& types)
|
||||
{
|
||||
shapes.clear();
|
||||
types.clear();
|
||||
|
||||
char* pch = strtok(s, "[]");
|
||||
while (pch != NULL)
|
||||
{
|
||||
// assign user data type
|
||||
if (!types.empty() && (pch[0] == 'f' || pch[0] == 'i' || pch[0] == 'u'))
|
||||
{
|
||||
char type[32];
|
||||
int nscan = sscanf(pch, "%31[^,]", type);
|
||||
if (nscan == 1)
|
||||
{
|
||||
types[types.size() - 1] = std::string(type);
|
||||
}
|
||||
}
|
||||
|
||||
// parse a,b,c
|
||||
int v;
|
||||
int nconsumed = 0;
|
||||
int nscan = sscanf(pch, "%d%n", &v, &nconsumed);
|
||||
if (nscan == 1)
|
||||
{
|
||||
// ok we get shape
|
||||
pch += nconsumed;
|
||||
|
||||
std::vector<int64_t> s;
|
||||
s.push_back(v);
|
||||
|
||||
nscan = sscanf(pch, ",%d%n", &v, &nconsumed);
|
||||
while (nscan == 1)
|
||||
{
|
||||
pch += nconsumed;
|
||||
|
||||
s.push_back(v);
|
||||
|
||||
nscan = sscanf(pch, ",%d%n", &v, &nconsumed);
|
||||
}
|
||||
|
||||
// shape end
|
||||
shapes.push_back(s);
|
||||
types.push_back("f32");
|
||||
}
|
||||
|
||||
pch = strtok(NULL, "[]");
|
||||
}
|
||||
}
|
||||
|
||||
static void print_shape_list(const std::vector<std::vector<int64_t> >& shapes, const std::vector<std::string>& types)
|
||||
{
|
||||
for (size_t i = 0; i < shapes.size(); i++)
|
||||
{
|
||||
const std::vector<int64_t>& s = shapes[i];
|
||||
const std::string& t = types[i];
|
||||
fprintf(stderr, "[");
|
||||
for (size_t j = 0; j < s.size(); j++)
|
||||
{
|
||||
fprintf(stderr, "%ld", s[j]);
|
||||
if (j != s.size() - 1)
|
||||
fprintf(stderr, ",");
|
||||
}
|
||||
fprintf(stderr, "]");
|
||||
fprintf(stderr, "%s", t.c_str());
|
||||
if (i != shapes.size() - 1)
|
||||
fprintf(stderr, ",");
|
||||
}
|
||||
}
|
||||
|
||||
static c10::ScalarType input_type_to_c10_ScalarType(const std::string& t)
|
||||
{
|
||||
if (t == "f32") return torch::kFloat32;
|
||||
if (t == "f16") return torch::kFloat16;
|
||||
if (t == "f64") return torch::kFloat64;
|
||||
if (t == "i32") return torch::kInt32;
|
||||
if (t == "i16") return torch::kInt16;
|
||||
if (t == "i64") return torch::kInt64;
|
||||
if (t == "i8") return torch::kInt8;
|
||||
if (t == "u8") return torch::kUInt8;
|
||||
|
||||
fprintf(stderr, "unsupported type %s fallback to f32\n", t.c_str());
|
||||
return torch::kFloat32;
|
||||
}
|
||||
|
||||
static void show_usage()
|
||||
{
|
||||
fprintf(stderr, "Usage: pnnx [model.pt] [(key=value)...]\n");
|
||||
fprintf(stderr, " pnnxparam=model.pnnx.param\n");
|
||||
fprintf(stderr, " pnnxbin=model.pnnx.bin\n");
|
||||
fprintf(stderr, " pnnxpy=model_pnnx.py\n");
|
||||
fprintf(stderr, " ncnnparam=model.ncnn.param\n");
|
||||
fprintf(stderr, " ncnnbin=model.ncnn.bin\n");
|
||||
fprintf(stderr, " ncnnpy=model_ncnn.py\n");
|
||||
fprintf(stderr, " optlevel=2\n");
|
||||
fprintf(stderr, " device=cpu/gpu\n");
|
||||
fprintf(stderr, " inputshape=[1,3,224,224],...\n");
|
||||
fprintf(stderr, " inputshape2=[1,3,320,320],...\n");
|
||||
#if _WIN32
|
||||
fprintf(stderr, " customop=C:\\Users\\nihui\\AppData\\Local\\torch_extensions\\torch_extensions\\Cache\\fused\\fused.dll,...\n");
|
||||
#else
|
||||
fprintf(stderr, " customop=/home/nihui/.cache/torch_extensions/fused/fused.so,...\n");
|
||||
#endif
|
||||
fprintf(stderr, " moduleop=models.common.Focus,models.yolo.Detect,...\n");
|
||||
fprintf(stderr, "Sample usage: pnnx mobilenet_v2.pt inputshape=[1,3,224,224]\n");
|
||||
fprintf(stderr, " pnnx yolov5s.pt inputshape=[1,3,640,640]f32 inputshape2=[1,3,320,320]f32 device=gpu moduleop=models.common.Focus,models.yolo.Detect\n");
|
||||
}
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
if (argc < 2)
|
||||
{
|
||||
show_usage();
|
||||
return -1;
|
||||
}
|
||||
|
||||
for (int i = 1; i < argc; i++)
|
||||
{
|
||||
if (argv[i][0] == '-')
|
||||
{
|
||||
show_usage();
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
std::string ptpath = std::string(argv[1]);
|
||||
|
||||
std::string ptbase = get_basename(ptpath);
|
||||
|
||||
std::string pnnxparampath = ptbase + ".pnnx.param";
|
||||
std::string pnnxbinpath = ptbase + ".pnnx.bin";
|
||||
std::string pnnxpypath = ptbase + "_pnnx.py";
|
||||
std::string ncnnparampath = ptbase + ".ncnn.param";
|
||||
std::string ncnnbinpath = ptbase + ".ncnn.bin";
|
||||
std::string ncnnpypath = ptbase + "_ncnn.py";
|
||||
int optlevel = 2;
|
||||
std::string device = "cpu";
|
||||
std::vector<std::vector<int64_t> > input_shapes;
|
||||
std::vector<std::string> input_types;
|
||||
std::vector<std::vector<int64_t> > input_shapes2;
|
||||
std::vector<std::string> input_types2;
|
||||
std::vector<std::string> customop_modules;
|
||||
std::vector<std::string> module_operators;
|
||||
|
||||
for (int i = 2; i < argc; i++)
|
||||
{
|
||||
// key=value
|
||||
char* kv = argv[i];
|
||||
|
||||
char* eqs = strchr(kv, '=');
|
||||
if (eqs == NULL)
|
||||
{
|
||||
fprintf(stderr, "unrecognized arg %s\n", kv);
|
||||
continue;
|
||||
}
|
||||
|
||||
// split k v
|
||||
eqs[0] = '\0';
|
||||
const char* key = kv;
|
||||
char* value = eqs + 1;
|
||||
|
||||
if (strcmp(key, "pnnxparam") == 0)
|
||||
pnnxparampath = std::string(value);
|
||||
if (strcmp(key, "pnnxbin") == 0)
|
||||
pnnxbinpath = std::string(value);
|
||||
if (strcmp(key, "pnnxpy") == 0)
|
||||
pnnxpypath = std::string(value);
|
||||
if (strcmp(key, "ncnnparam") == 0)
|
||||
ncnnparampath = std::string(value);
|
||||
if (strcmp(key, "ncnnbin") == 0)
|
||||
ncnnbinpath = std::string(value);
|
||||
if (strcmp(key, "ncnnpy") == 0)
|
||||
ncnnpypath = std::string(value);
|
||||
if (strcmp(key, "optlevel") == 0)
|
||||
optlevel = atoi(value);
|
||||
if (strcmp(key, "device") == 0)
|
||||
device = value;
|
||||
if (strcmp(key, "inputshape") == 0)
|
||||
parse_shape_list(value, input_shapes, input_types);
|
||||
if (strcmp(key, "inputshape2") == 0)
|
||||
parse_shape_list(value, input_shapes2, input_types2);
|
||||
if (strcmp(key, "customop") == 0)
|
||||
parse_string_list(value, customop_modules);
|
||||
if (strcmp(key, "moduleop") == 0)
|
||||
parse_string_list(value, module_operators);
|
||||
}
|
||||
|
||||
// print options
|
||||
{
|
||||
fprintf(stderr, "pnnxparam = %s\n", pnnxparampath.c_str());
|
||||
fprintf(stderr, "pnnxbin = %s\n", pnnxbinpath.c_str());
|
||||
fprintf(stderr, "pnnxpy = %s\n", pnnxpypath.c_str());
|
||||
fprintf(stderr, "ncnnparam = %s\n", ncnnparampath.c_str());
|
||||
fprintf(stderr, "ncnnbin = %s\n", ncnnbinpath.c_str());
|
||||
fprintf(stderr, "ncnnpy = %s\n", ncnnpypath.c_str());
|
||||
fprintf(stderr, "optlevel = %d\n", optlevel);
|
||||
fprintf(stderr, "device = %s\n", device.c_str());
|
||||
fprintf(stderr, "inputshape = ");
|
||||
print_shape_list(input_shapes, input_types);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "inputshape2 = ");
|
||||
print_shape_list(input_shapes2, input_types2);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "customop = ");
|
||||
print_string_list(customop_modules);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "moduleop = ");
|
||||
print_string_list(module_operators);
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
for (auto m : customop_modules)
|
||||
{
|
||||
fprintf(stderr, "load custom module %s\n", m.c_str());
|
||||
#if _WIN32
|
||||
HMODULE handle = LoadLibraryExA(m.c_str(), NULL, LOAD_WITH_ALTERED_SEARCH_PATH);
|
||||
if (!handle)
|
||||
{
|
||||
fprintf(stderr, "LoadLibraryExA %s failed %s\n", m.c_str(), GetLastError());
|
||||
}
|
||||
#else
|
||||
void* handle = dlopen(m.c_str(), RTLD_LAZY);
|
||||
if (!handle)
|
||||
{
|
||||
fprintf(stderr, "dlopen %s failed %s\n", m.c_str(), dlerror());
|
||||
}
|
||||
#endif
|
||||
}
|
||||
|
||||
std::vector<at::Tensor> input_tensors;
|
||||
for (size_t i = 0; i < input_shapes.size(); i++)
|
||||
{
|
||||
const std::vector<int64_t>& shape = input_shapes[i];
|
||||
const std::string& type = input_types[i];
|
||||
|
||||
at::Tensor t = torch::ones(shape, input_type_to_c10_ScalarType(type));
|
||||
if (device == "gpu")
|
||||
t = t.cuda();
|
||||
|
||||
input_tensors.push_back(t);
|
||||
}
|
||||
|
||||
std::vector<at::Tensor> input_tensors2;
|
||||
for (size_t i = 0; i < input_shapes2.size(); i++)
|
||||
{
|
||||
const std::vector<int64_t>& shape = input_shapes2[i];
|
||||
const std::string& type = input_types2[i];
|
||||
|
||||
at::Tensor t = torch::ones(shape, input_type_to_c10_ScalarType(type));
|
||||
if (device == "gpu")
|
||||
t = t.cuda();
|
||||
|
||||
input_tensors2.push_back(t);
|
||||
}
|
||||
|
||||
torch::jit::Module mod = torch::jit::load(ptpath);
|
||||
|
||||
mod.eval();
|
||||
|
||||
// mod.dump(true, false, false);
|
||||
// mod.dump(true, true, true);
|
||||
|
||||
auto g = mod.get_method("forward").graph();
|
||||
|
||||
// g->dump();
|
||||
|
||||
fprintf(stderr, "############# pass_level0\n");
|
||||
|
||||
std::map<std::string, pnnx::Attribute> foldable_constants;
|
||||
pnnx::pass_level0(mod, g, input_tensors, input_tensors2, module_operators, ptpath, foldable_constants);
|
||||
|
||||
// g->dump();
|
||||
|
||||
fprintf(stderr, "############# pass_level1\n");
|
||||
|
||||
pnnx::Graph pnnx_graph;
|
||||
pnnx::pass_level1(mod, g, pnnx_graph);
|
||||
|
||||
// g->dump();
|
||||
|
||||
fprintf(stderr, "############# pass_level2\n");
|
||||
|
||||
pnnx::pass_level2(pnnx_graph);
|
||||
|
||||
pnnx_graph.save("debug.param", "debug.bin");
|
||||
|
||||
if (optlevel >= 1)
|
||||
{
|
||||
fprintf(stderr, "############# pass_level3\n");
|
||||
|
||||
pnnx::pass_level3(pnnx_graph);
|
||||
|
||||
fprintf(stderr, "############# pass_level4\n");
|
||||
|
||||
pnnx::pass_level4(pnnx_graph);
|
||||
}
|
||||
|
||||
pnnx_graph.save("debug2.param", "debug2.bin");
|
||||
|
||||
if (optlevel >= 2)
|
||||
{
|
||||
fprintf(stderr, "############# pass_level5\n");
|
||||
|
||||
pnnx::pass_level5(pnnx_graph, foldable_constants);
|
||||
}
|
||||
|
||||
pnnx_graph.save(pnnxparampath, pnnxbinpath);
|
||||
|
||||
pnnx_graph.python(pnnxpypath, pnnxbinpath);
|
||||
|
||||
// if (optlevel >= 2)
|
||||
{
|
||||
fprintf(stderr, "############# pass_ncnn\n");
|
||||
|
||||
pnnx::pass_ncnn(pnnx_graph);
|
||||
|
||||
pnnx_graph.ncnn(ncnnparampath, ncnnbinpath, ncnnpypath);
|
||||
}
|
||||
|
||||
// pnnx::Graph pnnx_graph2;
|
||||
|
||||
// pnnx_graph2.load("pnnx.param", "pnnx.bin");
|
||||
// pnnx_graph2.save("pnnx2.param", "pnnx2.bin");
|
||||
|
||||
return 0;
|
||||
}
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level0.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level0.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level0.h"
|
||||
|
||||
#include "pass_level0/constant_unpooling.h"
|
||||
#include "pass_level0/inline_block.h"
|
||||
#include "pass_level0/shape_inference.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void pass_level0(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& g, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants)
|
||||
{
|
||||
inline_block(g, module_operators);
|
||||
|
||||
constant_unpooling(g);
|
||||
|
||||
if (!input_tensors.empty())
|
||||
{
|
||||
shape_inference(mod, g, input_tensors, input_tensors2, module_operators, ptpath, foldable_constants);
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
27
3rdparty/ncnn/tools/pnnx/src/pass_level0.h
vendored
Normal file
27
3rdparty/ncnn/tools/pnnx/src/pass_level0.h
vendored
Normal file
@@ -0,0 +1,27 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef PNNX_PASS_LEVEL0_H
|
||||
#define PNNX_PASS_LEVEL0_H
|
||||
|
||||
#include <torch/script.h>
|
||||
#include "ir.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void pass_level0(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& g, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants);
|
||||
|
||||
} // namespace pnnx
|
||||
|
||||
#endif // PNNX_PASS_LEVEL0_H
|
||||
80
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.cpp
vendored
Normal file
80
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.cpp
vendored
Normal file
@@ -0,0 +1,80 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "constant_unpooling.h"
|
||||
|
||||
#include <unordered_map>
|
||||
#include <unordered_set>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void ConstantUnpooling(std::shared_ptr<torch::jit::Graph>& graph, torch::jit::Block* block, std::unordered_set<torch::jit::Node*>& constants)
|
||||
{
|
||||
for (auto it = block->nodes().begin(); it != block->nodes().end();)
|
||||
{
|
||||
auto node = *it;
|
||||
// node may be moved to a different block so advance iterator now
|
||||
++it;
|
||||
|
||||
if (!node->blocks().empty())
|
||||
{
|
||||
// Traverse sub-blocks.
|
||||
for (auto block : node->blocks())
|
||||
{
|
||||
ConstantUnpooling(graph, block, constants);
|
||||
}
|
||||
|
||||
continue;
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)node->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = node->input(i);
|
||||
|
||||
if (in->node()->kind() != c10::prim::Constant)
|
||||
continue;
|
||||
|
||||
// input constant node
|
||||
if (constants.find(in->node()) == constants.end())
|
||||
{
|
||||
constants.insert(in->node());
|
||||
continue;
|
||||
}
|
||||
|
||||
torch::jit::WithInsertPoint guard(node);
|
||||
|
||||
std::unordered_map<torch::jit::Value*, torch::jit::Value*> value_map;
|
||||
auto value_map_func = [&](torch::jit::Value* v) {
|
||||
return value_map.at(v);
|
||||
};
|
||||
|
||||
// graph->setInsertPoint(node);
|
||||
|
||||
auto* new_constant_node = graph->insertNode(graph->createClone(in->node(), value_map_func, false));
|
||||
|
||||
// fprintf(stderr, "new_constant_node %s\n", new_constant_node->outputs()[0]->debugName().c_str());
|
||||
|
||||
// create new constant node
|
||||
node->replaceInput(i, new_constant_node->outputs()[0]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void constant_unpooling(std::shared_ptr<torch::jit::Graph>& graph)
|
||||
{
|
||||
std::unordered_set<torch::jit::Node*> constants;
|
||||
ConstantUnpooling(graph, graph->block(), constants);
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.h
vendored
Normal file
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/constant_unpooling.h
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/script.h>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void constant_unpooling(std::shared_ptr<torch::jit::Graph>& graph);
|
||||
|
||||
} // namespace pnnx
|
||||
142
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.cpp
vendored
Normal file
142
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.cpp
vendored
Normal file
@@ -0,0 +1,142 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "inline_block.h"
|
||||
#include "../pass_level1.h"
|
||||
|
||||
#include <set>
|
||||
|
||||
#include <torch/csrc/jit/passes/quantization/helper.h>
|
||||
#include <torch/csrc/api/include/torch/version.h>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
static void inlineCallTo(torch::jit::Node* to_replace, torch::jit::Function* callee)
|
||||
{
|
||||
torch::jit::WithInsertPoint guard(to_replace);
|
||||
|
||||
std::unordered_map<torch::jit::Value*, torch::jit::Value*> value_map;
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
std::vector<torch::jit::Value*> new_outputs = torch::jit::insertGraph(*to_replace->owningGraph(), *(toGraphFunction(*callee).graph()), to_replace->inputs(), value_map);
|
||||
#else
|
||||
std::vector<torch::jit::Value*> new_outputs = torch::jit::insertGraph(*to_replace->owningGraph(), *(callee->graph()), to_replace->inputs(), value_map);
|
||||
#endif
|
||||
|
||||
const auto& old_outputs = to_replace->outputs();
|
||||
for (size_t i = 0; i < old_outputs.size(); ++i)
|
||||
{
|
||||
new_outputs[i]->copyMetadata(old_outputs[i]);
|
||||
|
||||
old_outputs[i]->replaceAllUsesWith(new_outputs[i]);
|
||||
}
|
||||
|
||||
to_replace->destroy();
|
||||
}
|
||||
|
||||
static void inlineCalls(torch::jit::Block* block, const std::vector<std::string>& module_operators, std::set<std::string>& inlined_modules)
|
||||
{
|
||||
for (auto it = block->nodes().begin(), end = block->nodes().end(); it != end;)
|
||||
{
|
||||
torch::jit::Node* n = *it++;
|
||||
if (n->kind() == c10::prim::CallFunction)
|
||||
{
|
||||
auto function_constant = n->input(0)->node();
|
||||
auto fun_type = function_constant->output()->type()->expect<torch::jit::FunctionType>();
|
||||
if (!fun_type->function()->isGraphFunction())
|
||||
continue;
|
||||
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
inlineCalls(toGraphFunction(*(fun_type->function())).graph()->block(), module_operators, inlined_modules);
|
||||
#else
|
||||
inlineCalls(fun_type->function()->graph()->block(), module_operators, inlined_modules);
|
||||
#endif
|
||||
|
||||
n->removeInput(0);
|
||||
|
||||
fprintf(stderr, "inline function %s\n", fun_type->function()->name().c_str());
|
||||
|
||||
pnnx::inlineCallTo(n, fun_type->function());
|
||||
}
|
||||
else if (n->kind() == c10::prim::CallMethod)
|
||||
{
|
||||
auto class_type = n->input(0)->type()->cast<torch::jit::ClassType>();
|
||||
if (!class_type)
|
||||
continue;
|
||||
|
||||
const std::string& function_name = n->s(torch::jit::attr::name);
|
||||
torch::jit::Function& function = class_type->getMethod(function_name);
|
||||
if (!function.isGraphFunction())
|
||||
continue;
|
||||
|
||||
std::string class_type_str = torch::jit::removeTorchMangle(class_type->str());
|
||||
|
||||
bool skip_inline = false;
|
||||
for (const auto& ow : get_global_pnnx_fuse_module_passes())
|
||||
{
|
||||
if (class_type_str == ow->match_type_str())
|
||||
{
|
||||
skip_inline = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (skip_inline)
|
||||
continue;
|
||||
|
||||
std::string class_type_str_no_torch_prefix = class_type_str.substr(10);
|
||||
|
||||
if (std::find(module_operators.begin(), module_operators.end(), class_type_str_no_torch_prefix) != module_operators.end())
|
||||
{
|
||||
continue;
|
||||
}
|
||||
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
inlineCalls(toGraphFunction(function).graph()->block(), module_operators, inlined_modules);
|
||||
#else
|
||||
inlineCalls(function.graph()->block(), module_operators, inlined_modules);
|
||||
#endif
|
||||
|
||||
inlined_modules.insert(class_type_str_no_torch_prefix);
|
||||
|
||||
// fprintf(stderr, "inline %s\n", class_type_str_no_torch_prefix.c_str());
|
||||
// fprintf(stderr, "inline method %s %s %s\n", function.name().c_str(), class_type->str().c_str(), n->input(0)->node()->s(torch::jit::attr::name).c_str());
|
||||
|
||||
pnnx::inlineCallTo(n, &function);
|
||||
}
|
||||
else
|
||||
{
|
||||
for (auto b : n->blocks())
|
||||
{
|
||||
inlineCalls(b, module_operators, inlined_modules);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void inline_block(std::shared_ptr<torch::jit::Graph>& graph, const std::vector<std::string>& module_operators)
|
||||
{
|
||||
std::set<std::string> inlined_modules;
|
||||
|
||||
inlineCalls(graph->block(), module_operators, inlined_modules);
|
||||
|
||||
for (const auto& x : inlined_modules)
|
||||
{
|
||||
if (x == "torch.nn.modules.container.Sequential")
|
||||
continue;
|
||||
|
||||
fprintf(stderr, "inline module = %s\n", x.c_str());
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.h
vendored
Normal file
21
3rdparty/ncnn/tools/pnnx/src/pass_level0/inline_block.h
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/script.h>
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void inline_block(std::shared_ptr<torch::jit::Graph>& graph, const std::vector<std::string>& module_operators);
|
||||
|
||||
} // namespace pnnx
|
||||
293
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.cpp
vendored
Normal file
293
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.cpp
vendored
Normal file
@@ -0,0 +1,293 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "shape_inference.h"
|
||||
#include <unordered_set>
|
||||
|
||||
#include "pass_level0/constant_unpooling.h"
|
||||
#include "pass_level0/inline_block.h"
|
||||
#include "pass_level0/shape_inference.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
static bool value_link_input(const torch::jit::Value* v, const std::vector<torch::jit::Value*>& inputs)
|
||||
{
|
||||
for (auto x : inputs)
|
||||
{
|
||||
if (v == x)
|
||||
return true;
|
||||
}
|
||||
|
||||
for (size_t i = 0; i < v->node()->inputs().size(); i++)
|
||||
{
|
||||
bool link = value_link_input(v->node()->inputs()[i], inputs);
|
||||
if (link)
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
static bool value_link_output(const torch::jit::Value* v, const std::vector<torch::jit::Value*>& outputs)
|
||||
{
|
||||
for (auto x : outputs)
|
||||
{
|
||||
if (v == x)
|
||||
return true;
|
||||
}
|
||||
|
||||
for (size_t i = 0; i < v->uses().size(); i++)
|
||||
{
|
||||
auto node = v->uses()[i].user;
|
||||
for (auto x : node->outputs())
|
||||
{
|
||||
bool link = value_link_output(x, outputs);
|
||||
if (link)
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
void shape_inference(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& graph, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants)
|
||||
{
|
||||
// collect all intermediate output tensors
|
||||
std::vector<std::unordered_set<std::string> > more_value_names;
|
||||
std::vector<std::vector<torch::jit::Value*> > more_values;
|
||||
{
|
||||
std::unordered_set<std::string> value_names;
|
||||
std::vector<torch::jit::Value*> values;
|
||||
for (const auto& n : graph->nodes())
|
||||
{
|
||||
for (const auto& v : n->outputs())
|
||||
{
|
||||
auto tensor_type = v->type()->cast<torch::jit::TensorType>();
|
||||
if (!tensor_type)
|
||||
continue;
|
||||
|
||||
value_names.insert(v->debugName());
|
||||
values.push_back(v);
|
||||
}
|
||||
|
||||
// too many intermediate blobs in one inference results oom
|
||||
if (value_names.size() >= 1000)
|
||||
{
|
||||
more_value_names.push_back(value_names);
|
||||
value_names.clear();
|
||||
|
||||
more_values.push_back(values);
|
||||
values.clear();
|
||||
}
|
||||
}
|
||||
|
||||
if (value_names.size() > 0)
|
||||
{
|
||||
more_value_names.push_back(value_names);
|
||||
more_values.push_back(values);
|
||||
}
|
||||
}
|
||||
|
||||
// collect graph inputs outputs
|
||||
std::vector<torch::jit::Value*> g_inputs;
|
||||
for (size_t i = 1; i < graph->inputs().size(); i++)
|
||||
{
|
||||
g_inputs.push_back(graph->inputs()[i]);
|
||||
}
|
||||
std::vector<torch::jit::Value*> g_outputs;
|
||||
for (size_t i = 0; i < graph->outputs().size(); i++)
|
||||
{
|
||||
g_outputs.push_back(graph->outputs()[i]);
|
||||
}
|
||||
|
||||
std::vector<torch::jit::IValue> inputs;
|
||||
for (size_t i = 0; i < input_tensors.size(); i++)
|
||||
{
|
||||
const at::Tensor& it = input_tensors[i];
|
||||
inputs.push_back(it);
|
||||
}
|
||||
|
||||
std::vector<torch::jit::IValue> inputs2;
|
||||
for (size_t i = 0; i < input_tensors2.size(); i++)
|
||||
{
|
||||
const at::Tensor& it = input_tensors2[i];
|
||||
inputs2.push_back(it);
|
||||
}
|
||||
|
||||
std::map<torch::jit::Value*, at::Tensor> output_tensors;
|
||||
|
||||
for (size_t p = 0; p < more_value_names.size(); p++)
|
||||
{
|
||||
std::unordered_set<std::string>& value_names = more_value_names[p];
|
||||
std::vector<torch::jit::Value*>& values = more_values[p];
|
||||
|
||||
// auto mod2 = mod.deepcopy();
|
||||
|
||||
torch::jit::Module mod2 = torch::jit::load(ptpath);
|
||||
mod2.eval();
|
||||
|
||||
auto graph2 = mod2.get_method("forward").graph();
|
||||
|
||||
inline_block(graph2, module_operators);
|
||||
|
||||
constant_unpooling(graph2);
|
||||
|
||||
std::vector<torch::jit::Value*> values2;
|
||||
for (auto n : graph2->nodes())
|
||||
{
|
||||
for (const auto& v : n->outputs())
|
||||
{
|
||||
auto tensor_type = v->type()->cast<torch::jit::TensorType>();
|
||||
if (!tensor_type)
|
||||
continue;
|
||||
|
||||
if (value_names.find(v->debugName()) != value_names.end())
|
||||
{
|
||||
values2.push_back(v);
|
||||
fprintf(stderr, "%s ", v->debugName().c_str());
|
||||
}
|
||||
}
|
||||
}
|
||||
fprintf(stderr, "\n----------------\n\n");
|
||||
|
||||
// set new graph output
|
||||
torch::jit::Node* new_return_node = graph2->createTuple(at::ArrayRef<torch::jit::Value*>(values2));
|
||||
|
||||
graph2->appendNode(new_return_node);
|
||||
|
||||
graph2->eraseOutput(0);
|
||||
graph2->registerOutput(new_return_node->outputs()[0]);
|
||||
|
||||
// inference for all tensors
|
||||
auto outputs = mod2.copy().forward(inputs).toTuple();
|
||||
|
||||
if (input_tensors2.empty())
|
||||
{
|
||||
// assign shape info
|
||||
for (size_t i = 0; i < values2.size(); i++)
|
||||
{
|
||||
auto v = values[i];
|
||||
auto t = outputs->elements()[i].toTensor();
|
||||
|
||||
v->setType(c10::TensorType::create(t));
|
||||
|
||||
// check if value that does not depend on inputs
|
||||
if (!value_link_input(v, g_inputs) && value_link_output(v, g_outputs))
|
||||
{
|
||||
output_tensors[v] = t;
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
// assign dynamic shape info
|
||||
auto outputs2 = mod2.copy().forward(inputs2).toTuple();
|
||||
|
||||
fprintf(stderr, "assign dynamic shape info\n");
|
||||
|
||||
for (size_t i = 0; i < values2.size(); i++)
|
||||
{
|
||||
auto v = values[i];
|
||||
auto t = outputs->elements()[i].toTensor();
|
||||
auto t2 = outputs2->elements()[i].toTensor();
|
||||
|
||||
auto type1 = c10::TensorType::create(t);
|
||||
auto type2 = c10::TensorType::create(t2);
|
||||
|
||||
std::vector<c10::ShapeSymbol> sizes1 = type1->symbolic_sizes().sizes().value();
|
||||
std::vector<c10::ShapeSymbol> sizes2 = type2->symbolic_sizes().sizes().value();
|
||||
|
||||
for (size_t i = 0; i < sizes1.size(); i++)
|
||||
{
|
||||
if (sizes1[i] == sizes2[i])
|
||||
continue;
|
||||
|
||||
sizes1[i] = c10::ShapeSymbol::fromStaticSize(-1);
|
||||
}
|
||||
|
||||
auto finaltype = type1->withSymbolicShapes(c10::SymbolicShape(sizes1));
|
||||
|
||||
v->setType(finaltype);
|
||||
|
||||
// check if value that does not depend on inputs
|
||||
if (!value_link_input(v, g_inputs) && value_link_output(v, g_outputs))
|
||||
{
|
||||
output_tensors[v] = t;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (input_tensors2.empty())
|
||||
{
|
||||
for (size_t i = 0; i < input_tensors.size(); i++)
|
||||
{
|
||||
auto type = c10::TensorType::create(input_tensors[i]);
|
||||
|
||||
graph->inputs()[1 + i]->setType(type);
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
for (size_t i = 0; i < input_tensors.size(); i++)
|
||||
{
|
||||
auto type1 = c10::TensorType::create(input_tensors[i]);
|
||||
auto type2 = c10::TensorType::create(input_tensors2[i]);
|
||||
|
||||
std::vector<c10::ShapeSymbol> sizes1 = type1->symbolic_sizes().sizes().value();
|
||||
std::vector<c10::ShapeSymbol> sizes2 = type2->symbolic_sizes().sizes().value();
|
||||
|
||||
for (size_t i = 0; i < sizes1.size(); i++)
|
||||
{
|
||||
if (sizes1[i] == sizes2[i])
|
||||
continue;
|
||||
|
||||
sizes1[i] = c10::ShapeSymbol::fromStaticSize(-1);
|
||||
}
|
||||
|
||||
auto finaltype = type1->withSymbolicShapes(c10::SymbolicShape(sizes1));
|
||||
|
||||
graph->inputs()[1 + i]->setType(finaltype);
|
||||
}
|
||||
}
|
||||
|
||||
for (auto xx : output_tensors)
|
||||
{
|
||||
auto v = xx.first;
|
||||
auto tensor = xx.second;
|
||||
|
||||
bool link_to_output = false;
|
||||
for (size_t i = 0; i < v->uses().size(); i++)
|
||||
{
|
||||
auto node = v->uses()[i].user;
|
||||
for (auto x : node->outputs())
|
||||
{
|
||||
if (output_tensors.find(x) == output_tensors.end())
|
||||
{
|
||||
link_to_output = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const int ndim = (int)tensor.dim();
|
||||
if (link_to_output && ndim > 0)
|
||||
{
|
||||
fprintf(stderr, "foldable_constant %s\n", v->debugName().c_str());
|
||||
foldable_constants[v->debugName()] = Attribute(tensor);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
23
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.h
vendored
Normal file
23
3rdparty/ncnn/tools/pnnx/src/pass_level0/shape_inference.h
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/script.h>
|
||||
#include <map>
|
||||
#include "ir.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
void shape_inference(const torch::jit::Module& mod, std::shared_ptr<torch::jit::Graph>& graph, const std::vector<at::Tensor>& input_tensors, const std::vector<at::Tensor>& input_tensors2, const std::vector<std::string>& module_operators, const std::string& ptpath, std::map<std::string, Attribute>& foldable_constants);
|
||||
|
||||
} // namespace pnnx
|
||||
313
3rdparty/ncnn/tools/pnnx/src/pass_level1.cpp
vendored
Normal file
313
3rdparty/ncnn/tools/pnnx/src/pass_level1.cpp
vendored
Normal file
@@ -0,0 +1,313 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include <torch/csrc/jit/passes/quantization/helper.h>
|
||||
#include <torch/csrc/api/include/torch/version.h>
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
FuseModulePass::~FuseModulePass()
|
||||
{
|
||||
}
|
||||
|
||||
void FuseModulePass::write(Operator* /*op*/, const std::shared_ptr<torch::jit::Graph>& /*graph*/) const
|
||||
{
|
||||
}
|
||||
|
||||
void FuseModulePass::write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& /*mod*/) const
|
||||
{
|
||||
write(op, graph);
|
||||
}
|
||||
|
||||
static std::vector<const FuseModulePass*> g_global_pnnx_fuse_module_passes;
|
||||
|
||||
const std::vector<const FuseModulePass*>& get_global_pnnx_fuse_module_passes()
|
||||
{
|
||||
return g_global_pnnx_fuse_module_passes;
|
||||
}
|
||||
|
||||
FuseModulePassRegister::FuseModulePassRegister(const FuseModulePass* _pass)
|
||||
: pass(_pass)
|
||||
{
|
||||
g_global_pnnx_fuse_module_passes.push_back(pass);
|
||||
}
|
||||
|
||||
FuseModulePassRegister::~FuseModulePassRegister()
|
||||
{
|
||||
delete pass;
|
||||
}
|
||||
|
||||
void pass_level1(const torch::jit::Module& mod, const std::shared_ptr<torch::jit::Graph>& g, Graph& pg)
|
||||
{
|
||||
for (int i = 1; i < (int)g->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = g->inputs()[i];
|
||||
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_input_%d", i - 1);
|
||||
|
||||
Operator* op = pg.new_operator("pnnx.Input", name);
|
||||
Operand* r = pg.new_operand(in);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
std::map<std::string, std::string> class_type_to_names;
|
||||
int pnnx_unknown_index = 0;
|
||||
|
||||
for (const auto& n : g->block()->nodes())
|
||||
{
|
||||
if (n->kind() == c10::prim::GetAttr)
|
||||
{
|
||||
// pass
|
||||
std::string name = n->s(torch::jit::attr::name);
|
||||
// std::string name = n->debugName();
|
||||
|
||||
auto class_type = n->output(0)->type()->cast<torch::jit::ClassType>();
|
||||
|
||||
if (class_type)
|
||||
{
|
||||
std::string class_type_str = class_type->str();
|
||||
class_type_to_names[class_type_str] = name;
|
||||
// class_type_to_names[class_type_str] = class_type_str + "." + name;
|
||||
}
|
||||
else
|
||||
{
|
||||
// Tensor from some class
|
||||
// Operator* op = pg.new_operator(n->kind().toDisplayString(), name);
|
||||
Operator* op = pg.new_operator("pnnx.Attribute", name);
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
std::deque<std::string> module_names; // = split(n->input(0)->node()->s(torch::jit::attr::name), '.');
|
||||
{
|
||||
auto np = n->input(0)->node();
|
||||
while (np->hasAttribute(torch::jit::attr::name))
|
||||
{
|
||||
module_names.push_front(np->s(torch::jit::attr::name));
|
||||
np = np->input(0)->node();
|
||||
}
|
||||
}
|
||||
|
||||
std::string wrapped_name;
|
||||
auto sub_mod = mod;
|
||||
for (auto module_name : module_names)
|
||||
{
|
||||
if (wrapped_name.size() > 0)
|
||||
wrapped_name = wrapped_name + "." + module_name;
|
||||
else
|
||||
wrapped_name = module_name;
|
||||
sub_mod = sub_mod.attr(module_name).toModule();
|
||||
}
|
||||
|
||||
if (wrapped_name.empty())
|
||||
{
|
||||
// top-level module
|
||||
wrapped_name = name;
|
||||
}
|
||||
|
||||
op->name = wrapped_name;
|
||||
|
||||
// op->params["this"] = n->input(i)
|
||||
|
||||
// sub_mod.dump(true, true, true);
|
||||
|
||||
op->attrs[name] = sub_mod.attr(name).toTensor();
|
||||
}
|
||||
}
|
||||
else if (n->kind() == c10::prim::Constant) // || n->kind() == c10::prim::ListConstruct)
|
||||
{
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_%d", pnnx_unknown_index++);
|
||||
|
||||
Operator* op = pg.new_operator(n->kind().toDisplayString(), name);
|
||||
|
||||
for (int i = 0; i < (int)n->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = n->input(i);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
op->params["value"] = n;
|
||||
|
||||
if (op->params["value"].type == 8)
|
||||
{
|
||||
op->type = "pnnx.Attribute";
|
||||
|
||||
op->params.erase("value");
|
||||
|
||||
op->attrs[name] = n->t(torch::jit::attr::value);
|
||||
}
|
||||
}
|
||||
else if (n->kind() == c10::prim::CallMethod)
|
||||
{
|
||||
auto class_type = n->input(0)->type()->cast<torch::jit::ClassType>();
|
||||
// const std::string& name = n->s(torch::jit::attr::name);
|
||||
|
||||
// fprintf(stderr, "call %s\n", class_type->str().c_str());
|
||||
|
||||
std::string name = class_type_to_names[class_type->str()];
|
||||
|
||||
std::string class_type_str = torch::jit::removeTorchMangle(class_type->str());
|
||||
|
||||
std::string optypename = class_type_str;
|
||||
for (const auto& ow : get_global_pnnx_fuse_module_passes())
|
||||
{
|
||||
if (class_type_str != ow->match_type_str())
|
||||
continue;
|
||||
|
||||
optypename = ow->type_str();
|
||||
break;
|
||||
}
|
||||
|
||||
if (optypename == class_type_str)
|
||||
{
|
||||
optypename = class_type_str.substr(10);
|
||||
}
|
||||
|
||||
Operator* op = pg.new_operator(optypename, name);
|
||||
|
||||
for (int i = 1; i < (int)n->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = n->input(i);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
|
||||
for (const auto& ow : get_global_pnnx_fuse_module_passes())
|
||||
{
|
||||
if (class_type_str != ow->match_type_str())
|
||||
continue;
|
||||
|
||||
auto class_type = n->input(0)->type()->cast<torch::jit::ClassType>();
|
||||
torch::jit::Function& function = class_type->getMethod(n->s(torch::jit::attr::name));
|
||||
|
||||
std::deque<std::string> module_names; // = split(n->input(0)->node()->s(torch::jit::attr::name), '.');
|
||||
{
|
||||
auto np = n->input(0)->node();
|
||||
while (np->hasAttribute(torch::jit::attr::name))
|
||||
{
|
||||
module_names.push_front(np->s(torch::jit::attr::name));
|
||||
np = np->input(0)->node();
|
||||
}
|
||||
}
|
||||
|
||||
std::string wrapped_name;
|
||||
auto sub_mod = mod;
|
||||
for (auto module_name : module_names)
|
||||
{
|
||||
if (wrapped_name.size() > 0)
|
||||
wrapped_name = wrapped_name + "." + module_name;
|
||||
else
|
||||
wrapped_name = module_name;
|
||||
sub_mod = sub_mod.attr(module_name).toModule();
|
||||
}
|
||||
|
||||
op->name = wrapped_name;
|
||||
|
||||
#if TORCH_VERSION_MAJOR >= 1 && TORCH_VERSION_MINOR >= 11
|
||||
ow->write(op, toGraphFunction(function).graph(), sub_mod);
|
||||
#else
|
||||
ow->write(op, function.graph(), sub_mod);
|
||||
#endif
|
||||
|
||||
break;
|
||||
}
|
||||
}
|
||||
// else if (n->kind() == c10::prim::CallFunction)
|
||||
// {
|
||||
// fprintf(stderr, "function %s", n->kind().toDisplayString());
|
||||
//
|
||||
// AT_ASSERT(cur->input(0)->node()->kind() == c10::prim::Constant);
|
||||
// auto function_constant = cur->input(0)->node();
|
||||
// auto fun_type = function_constant->output()->type()->expect<torch::jit::FunctionType>();
|
||||
// if (!fun_type->function()->isGraphFunction())
|
||||
// {
|
||||
// continue;
|
||||
// }
|
||||
// cur->removeInput(0);
|
||||
//
|
||||
// fprintf(stderr, "inline function %s\n", fun_type->function()->name().c_str());
|
||||
//
|
||||
// GRAPH_UPDATE("Inlining function '", fun_type->function()->name(), "' to ", *cur);
|
||||
// GRAPH_UPDATE("Function body: ", *fun_type->function()->optimized_graph());
|
||||
// inlineCallTo(cur, fun_type->function(), false);
|
||||
// break;
|
||||
// }
|
||||
else
|
||||
{
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_%d", pnnx_unknown_index++);
|
||||
|
||||
Operator* op = pg.new_operator(n->kind().toDisplayString(), name);
|
||||
|
||||
for (int i = 0; i < (int)n->inputs().size(); i++)
|
||||
{
|
||||
const auto& in = n->input(i);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)n->outputs().size(); i++)
|
||||
{
|
||||
const auto& on = n->output(i);
|
||||
Operand* r = pg.new_operand(on);
|
||||
r->producer = op;
|
||||
op->outputs.push_back(r);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int)g->outputs().size(); i++)
|
||||
{
|
||||
const auto& in = g->outputs()[i];
|
||||
|
||||
char name[32];
|
||||
sprintf(name, "pnnx_output_%d", i);
|
||||
Operator* op = pg.new_operator("pnnx.Output", name);
|
||||
Operand* r = pg.get_operand(in->debugName());
|
||||
r->consumers.push_back(op);
|
||||
op->inputs.push_back(r);
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace pnnx
|
||||
55
3rdparty/ncnn/tools/pnnx/src/pass_level1.h
vendored
Normal file
55
3rdparty/ncnn/tools/pnnx/src/pass_level1.h
vendored
Normal file
@@ -0,0 +1,55 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#ifndef PNNX_PASS_LEVEL1_H
|
||||
#define PNNX_PASS_LEVEL1_H
|
||||
|
||||
#include <torch/script.h>
|
||||
#include <torch/csrc/jit/api/module.h>
|
||||
#include "ir.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class FuseModulePass
|
||||
{
|
||||
public:
|
||||
virtual ~FuseModulePass();
|
||||
|
||||
virtual const char* match_type_str() const = 0;
|
||||
|
||||
virtual const char* type_str() const = 0;
|
||||
|
||||
virtual void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const;
|
||||
|
||||
virtual void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const;
|
||||
};
|
||||
|
||||
class FuseModulePassRegister
|
||||
{
|
||||
public:
|
||||
FuseModulePassRegister(const FuseModulePass* pass);
|
||||
~FuseModulePassRegister();
|
||||
const FuseModulePass* pass;
|
||||
};
|
||||
|
||||
const std::vector<const FuseModulePass*>& get_global_pnnx_fuse_module_passes();
|
||||
|
||||
#define REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(CLASS) \
|
||||
static FuseModulePassRegister g_global_pnnx_fusemodulepass_##CLASS##_register(new CLASS);
|
||||
|
||||
void pass_level1(const torch::jit::Module& mod, const std::shared_ptr<torch::jit::Graph>& g, Graph& pg);
|
||||
|
||||
} // namespace pnnx
|
||||
|
||||
#endif // PNNX_PASS_LEVEL1_H
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool1d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool1d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveAvgPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveAvgPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveAvgPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_avg_pool1d = find_node_by_kind(graph, "aten::adaptive_avg_pool1d");
|
||||
|
||||
op->params["output_size"] = adaptive_avg_pool1d->namedInput("output_size");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveAvgPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool2d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool2d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveAvgPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveAvgPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveAvgPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_avg_pool2d = find_node_by_kind(graph, "aten::adaptive_avg_pool2d");
|
||||
|
||||
op->params["output_size"] = adaptive_avg_pool2d->namedInput("output_size");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveAvgPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool3d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveAvgPool3d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveAvgPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveAvgPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveAvgPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_avg_pool3d = find_node_by_kind(graph, "aten::adaptive_avg_pool3d");
|
||||
|
||||
op->params["output_size"] = adaptive_avg_pool3d->namedInput("output_size");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveAvgPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool1d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool1d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveMaxPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveMaxPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveMaxPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_max_pool1d = find_node_by_kind(graph, "aten::adaptive_max_pool1d");
|
||||
|
||||
op->params["output_size"] = adaptive_max_pool1d->namedInput("output_size");
|
||||
op->params["return_indices"] = graph->outputs()[0]->node()->kind() == c10::prim::TupleConstruct ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveMaxPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool2d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool2d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveMaxPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveMaxPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveMaxPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_max_pool2d = find_node_by_kind(graph, "aten::adaptive_max_pool2d");
|
||||
|
||||
op->params["output_size"] = adaptive_max_pool2d->namedInput("output_size");
|
||||
op->params["return_indices"] = graph->outputs()[0]->node()->kind() == c10::prim::TupleConstruct ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveMaxPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool3d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AdaptiveMaxPool3d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AdaptiveMaxPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AdaptiveMaxPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AdaptiveMaxPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* adaptive_max_pool3d = find_node_by_kind(graph, "aten::adaptive_max_pool3d");
|
||||
|
||||
op->params["output_size"] = adaptive_max_pool3d->namedInput("output_size");
|
||||
op->params["return_indices"] = graph->outputs()[0]->node()->kind() == c10::prim::TupleConstruct ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AdaptiveMaxPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AlphaDropout.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AlphaDropout.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AlphaDropout : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.AlphaDropout";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AlphaDropout";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AlphaDropout)
|
||||
|
||||
} // namespace pnnx
|
||||
48
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool1d.cpp
vendored
Normal file
48
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool1d.cpp
vendored
Normal file
@@ -0,0 +1,48 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AvgPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AvgPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AvgPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool1d = find_node_by_kind(graph, "aten::avg_pool1d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool1d->namedInput("kernel_size");
|
||||
op->params["stride"] = avg_pool1d->namedInput("stride");
|
||||
op->params["padding"] = avg_pool1d->namedInput("padding");
|
||||
op->params["ceil_mode"] = avg_pool1d->namedInput("ceil_mode");
|
||||
op->params["count_include_pad"] = avg_pool1d->namedInput("count_include_pad");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AvgPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool2d.cpp
vendored
Normal file
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool2d.cpp
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AvgPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AvgPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AvgPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool2d = find_node_by_kind(graph, "aten::avg_pool2d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool2d->namedInput("kernel_size");
|
||||
op->params["stride"] = avg_pool2d->namedInput("stride");
|
||||
op->params["padding"] = avg_pool2d->namedInput("padding");
|
||||
op->params["ceil_mode"] = avg_pool2d->namedInput("ceil_mode");
|
||||
op->params["count_include_pad"] = avg_pool2d->namedInput("count_include_pad");
|
||||
op->params["divisor_override"] = avg_pool2d->namedInput("divisor_override");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AvgPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool3d.cpp
vendored
Normal file
49
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_AvgPool3d.cpp
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class AvgPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.AvgPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.AvgPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool3d = find_node_by_kind(graph, "aten::avg_pool3d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool3d->namedInput("kernel_size");
|
||||
op->params["stride"] = avg_pool3d->namedInput("stride");
|
||||
op->params["padding"] = avg_pool3d->namedInput("padding");
|
||||
op->params["ceil_mode"] = avg_pool3d->namedInput("ceil_mode");
|
||||
op->params["count_include_pad"] = avg_pool3d->namedInput("count_include_pad");
|
||||
op->params["divisor_override"] = avg_pool3d->namedInput("divisor_override");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(AvgPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm1d.cpp
vendored
Normal file
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm1d.cpp
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class BatchNorm1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.batchnorm.BatchNorm1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.BatchNorm1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* bn = find_node_by_kind(graph, "aten::batch_norm");
|
||||
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
const auto& running_var = mod.attr("running_var").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
op->params["eps"] = bn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = running_var;
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(BatchNorm1d)
|
||||
|
||||
} // namespace pnnx
|
||||
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm2d.cpp
vendored
Normal file
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm2d.cpp
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class BatchNorm2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.batchnorm.BatchNorm2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.BatchNorm2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* bn = find_node_by_kind(graph, "aten::batch_norm");
|
||||
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
const auto& running_var = mod.attr("running_var").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
op->params["eps"] = bn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = running_var;
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(BatchNorm2d)
|
||||
|
||||
} // namespace pnnx
|
||||
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm3d.cpp
vendored
Normal file
57
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_BatchNorm3d.cpp
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class BatchNorm3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.batchnorm.BatchNorm3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.BatchNorm3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* bn = find_node_by_kind(graph, "aten::batch_norm");
|
||||
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
const auto& running_var = mod.attr("running_var").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
op->params["eps"] = bn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = running_var;
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(BatchNorm3d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_CELU.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_CELU.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class CELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.CELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.CELU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* celu = find_node_by_kind(graph, "aten::celu");
|
||||
|
||||
op->params["alpha"] = celu->namedInput("alpha");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(CELU)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ChannelShuffle.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ChannelShuffle.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ChannelShuffle : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.channelshuffle.ChannelShuffle";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ChannelShuffle";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* channel_shuffle = find_node_by_kind(graph, "aten::channel_shuffle");
|
||||
|
||||
op->params["groups"] = channel_shuffle->namedInput("groups");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ChannelShuffle)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad1d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad1d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConstantPad1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ConstantPad1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConstantPad1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
op->params["value"] = constant_pad_nd->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConstantPad1d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad2d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad2d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConstantPad2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ConstantPad2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConstantPad2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
op->params["value"] = constant_pad_nd->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConstantPad2d)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad3d.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConstantPad3d.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConstantPad3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ConstantPad3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConstantPad3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
op->params["value"] = constant_pad_nd->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConstantPad3d)
|
||||
|
||||
} // namespace pnnx
|
||||
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv1d.cpp
vendored
Normal file
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv1d.cpp
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
// #include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Conv1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.Conv1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Conv1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// {
|
||||
// pnnx::Graph pnnx_graph;
|
||||
//
|
||||
// pnnx_graph.load(mod, graph);
|
||||
//
|
||||
// pnnx::fuse_expression(pnnx_graph);
|
||||
//
|
||||
// pnnx_graph.save("tmp.param", "tmp.bin");
|
||||
// }
|
||||
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
const torch::jit::Node* convolution_mode = find_node_by_kind(graph, "aten::_convolution_mode");
|
||||
const torch::jit::Node* reflection_pad1d = find_node_by_kind(graph, "aten::reflection_pad1d");
|
||||
const torch::jit::Node* replication_pad1d = find_node_by_kind(graph, "aten::replication_pad1d");
|
||||
|
||||
if (convolution_mode)
|
||||
{
|
||||
convolution = convolution_mode;
|
||||
}
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["out_channels"] = weight.size(0);
|
||||
op->params["kernel_size"] = Parameter{weight.size(2)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
if (reflection_pad1d)
|
||||
{
|
||||
op->params["padding_mode"] = "reflect";
|
||||
op->params["padding"] = reflection_pad1d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 2)
|
||||
{
|
||||
// Conv1d only accepts tuple of one integer
|
||||
if (padding[0] == padding[1])
|
||||
{
|
||||
padding.resize(1);
|
||||
}
|
||||
else if (padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else if (replication_pad1d)
|
||||
{
|
||||
op->params["padding_mode"] = "replicate";
|
||||
op->params["padding"] = replication_pad1d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 2)
|
||||
{
|
||||
// Conv1d only accepts tuple of one integer
|
||||
if (padding[0] == padding[1])
|
||||
{
|
||||
padding.resize(1);
|
||||
}
|
||||
else if (padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
}
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Conv1d)
|
||||
|
||||
} // namespace pnnx
|
||||
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv2d.cpp
vendored
Normal file
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv2d.cpp
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
// #include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Conv2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.Conv2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Conv2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// {
|
||||
// pnnx::Graph pnnx_graph;
|
||||
//
|
||||
// pnnx_graph.load(mod, graph);
|
||||
//
|
||||
// pnnx::fuse_expression(pnnx_graph);
|
||||
//
|
||||
// pnnx_graph.save("tmp.param", "tmp.bin");
|
||||
// }
|
||||
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
const torch::jit::Node* convolution_mode = find_node_by_kind(graph, "aten::_convolution_mode");
|
||||
const torch::jit::Node* reflection_pad2d = find_node_by_kind(graph, "aten::reflection_pad2d");
|
||||
const torch::jit::Node* replication_pad2d = find_node_by_kind(graph, "aten::replication_pad2d");
|
||||
|
||||
if (convolution_mode)
|
||||
{
|
||||
convolution = convolution_mode;
|
||||
}
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["out_channels"] = weight.size(0);
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
if (reflection_pad2d)
|
||||
{
|
||||
op->params["padding_mode"] = "reflect";
|
||||
op->params["padding"] = reflection_pad2d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 4)
|
||||
{
|
||||
// Conv2d only accepts tuple of two integers
|
||||
if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3])
|
||||
{
|
||||
padding.resize(2);
|
||||
}
|
||||
else if (padding[0] == padding[2] && padding[1] == padding[3] && padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else if (replication_pad2d)
|
||||
{
|
||||
op->params["padding_mode"] = "replicate";
|
||||
op->params["padding"] = replication_pad2d->namedInput("padding");
|
||||
std::vector<int>& padding = op->params["padding"].ai;
|
||||
if (padding.size() == 4)
|
||||
{
|
||||
// Conv2d only accepts tuple of two integers
|
||||
if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3])
|
||||
{
|
||||
padding.resize(2);
|
||||
}
|
||||
else if (padding[0] == padding[2] && padding[1] == padding[3] && padding[0] != padding[1])
|
||||
{
|
||||
padding.resize(0);
|
||||
op->params["padding"].s = "same";
|
||||
}
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
}
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Conv2d)
|
||||
|
||||
} // namespace pnnx
|
||||
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv3d.cpp
vendored
Normal file
121
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Conv3d.cpp
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
// #include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Conv3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.Conv3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Conv3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// {
|
||||
// pnnx::Graph pnnx_graph;
|
||||
//
|
||||
// pnnx_graph.load(mod, graph);
|
||||
//
|
||||
// pnnx::fuse_expression(pnnx_graph);
|
||||
//
|
||||
// pnnx_graph.save("tmp.param", "tmp.bin");
|
||||
// }
|
||||
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
const torch::jit::Node* convolution_mode = find_node_by_kind(graph, "aten::_convolution_mode");
|
||||
// const torch::jit::Node* reflection_pad3d = find_node_by_kind(graph, "aten::reflection_pad3d");
|
||||
// const torch::jit::Node* replication_pad3d = find_node_by_kind(graph, "aten::replication_pad3d");
|
||||
|
||||
if (convolution_mode)
|
||||
{
|
||||
convolution = convolution_mode;
|
||||
}
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["out_channels"] = weight.size(0);
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3), weight.size(4)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
// if (reflection_pad3d)
|
||||
// {
|
||||
// op->params["padding_mode"] = "reflect";
|
||||
// op->params["padding"] = reflection_pad3d->namedInput("padding");
|
||||
// std::vector<int>& padding = op->params["padding"].ai;
|
||||
// if (padding.size() == 6)
|
||||
// {
|
||||
// // Conv3d only accepts tuple of three integers
|
||||
// if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3] && padding[3] == padding[4] && padding[4] == padding[5])
|
||||
// {
|
||||
// padding.resize(3);
|
||||
// }
|
||||
// else if (padding[0] == padding[3] && padding[1] == padding[4] && padding[2] == padding[5] && padding[0] != padding[1] && padding[1] != padding[2])
|
||||
// {
|
||||
// padding.resize(0);
|
||||
// op->params["padding"].s = "same";
|
||||
// }
|
||||
// }
|
||||
// }
|
||||
// else if (replication_pad3d)
|
||||
// {
|
||||
// op->params["padding_mode"] = "replicate";
|
||||
// op->params["padding"] = replication_pad3d->namedInput("padding");
|
||||
// std::vector<int>& padding = op->params["padding"].ai;
|
||||
// if (padding.size() == 6)
|
||||
// {
|
||||
// // Conv3d only accepts tuple of three integers
|
||||
// if (padding[0] == padding[1] && padding[1] == padding[2] && padding[2] == padding[3] && padding[3] == padding[4] && padding[4] == padding[5])
|
||||
// {
|
||||
// padding.resize(3);
|
||||
// }
|
||||
// else if (padding[0] == padding[3] && padding[1] == padding[4] && padding[2] == padding[5] && padding[0] != padding[1] && padding[1] != padding[2])
|
||||
// {
|
||||
// padding.resize(0);
|
||||
// op->params["padding"].s = "same";
|
||||
// }
|
||||
// }
|
||||
// }
|
||||
// else
|
||||
{
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
}
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Conv3d)
|
||||
|
||||
} // namespace pnnx
|
||||
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose1d.cpp
vendored
Normal file
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose1d.cpp
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConvTranspose1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.ConvTranspose1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConvTranspose1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(0);
|
||||
op->params["out_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["kernel_size"] = Parameter{weight.size(2)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
op->params["output_padding"] = convolution->namedInput("output_padding");
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConvTranspose1d)
|
||||
|
||||
} // namespace pnnx
|
||||
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose2d.cpp
vendored
Normal file
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose2d.cpp
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConvTranspose2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.ConvTranspose2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConvTranspose2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(0);
|
||||
op->params["out_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
op->params["output_padding"] = convolution->namedInput("output_padding");
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConvTranspose2d)
|
||||
|
||||
} // namespace pnnx
|
||||
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose3d.cpp
vendored
Normal file
60
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ConvTranspose3d.cpp
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ConvTranspose3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.conv.ConvTranspose3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ConvTranspose3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* convolution = find_node_by_kind(graph, "aten::_convolution");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["groups"] = convolution->namedInput("groups");
|
||||
op->params["in_channels"] = weight.size(0);
|
||||
op->params["out_channels"] = weight.size(1) * op->params["groups"].i;
|
||||
op->params["kernel_size"] = Parameter{weight.size(2), weight.size(3), weight.size(4)};
|
||||
op->params["stride"] = convolution->namedInput("stride");
|
||||
op->params["padding"] = convolution->namedInput("padding");
|
||||
op->params["output_padding"] = convolution->namedInput("output_padding");
|
||||
op->params["dilation"] = convolution->namedInput("dilation");
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ConvTranspose3d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Dropout : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.Dropout";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Dropout";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Dropout)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout2d.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout2d.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Dropout2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.Dropout2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Dropout2d";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Dropout2d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout3d.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Dropout3d.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Dropout3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.dropout.Dropout3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Dropout3d";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Dropout3d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ELU.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ELU.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.ELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ELU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* elu = find_node_by_kind(graph, "aten::elu");
|
||||
|
||||
op->params["alpha"] = elu->namedInput("alpha");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ELU)
|
||||
|
||||
} // namespace pnnx
|
||||
53
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Embedding.cpp
vendored
Normal file
53
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Embedding.cpp
vendored
Normal file
@@ -0,0 +1,53 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Embedding : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.sparse.Embedding";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Embedding";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* embedding = find_node_by_kind(graph, "aten::embedding");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_embeddings"] = weight.size(0);
|
||||
op->params["embedding_dim"] = weight.size(1);
|
||||
|
||||
// op->params["padding_idx"] = embedding->namedInput("padding_idx");
|
||||
// op->params["scale_grad_by_freq"] = embedding->namedInput("scale_grad_by_freq");
|
||||
op->params["sparse"] = embedding->namedInput("sparse");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Embedding)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GELU.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GELU.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class GELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.GELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.GELU";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(GELU)
|
||||
|
||||
} // namespace pnnx
|
||||
110
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GRU.cpp
vendored
Normal file
110
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GRU.cpp
vendored
Normal file
@@ -0,0 +1,110 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class GRU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.rnn.GRU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.GRU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// mod.dump(true, true, true);
|
||||
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* gru = find_node_by_kind(graph, "aten::gru");
|
||||
|
||||
const torch::jit::Node* return_tuple = find_node_by_kind(graph, "prim::TupleConstruct");
|
||||
if (return_tuple && return_tuple->inputs().size() == 2 && gru->outputs().size() == 2
|
||||
&& return_tuple->inputs()[0] == gru->outputs()[1] && return_tuple->inputs()[1] == gru->outputs()[0])
|
||||
{
|
||||
// mark the swapped output tuple
|
||||
// we would restore the fine order in pass_level3/fuse_rnn_unpack
|
||||
fprintf(stderr, "swapped detected !\n");
|
||||
op->params["pnnx_rnn_output_swapped"] = 1;
|
||||
}
|
||||
|
||||
// for (auto aa : gru->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
const auto& weight_ih_l0 = mod.attr("weight_ih_l0").toTensor();
|
||||
|
||||
op->params["input_size"] = weight_ih_l0.size(1);
|
||||
op->params["hidden_size"] = weight_ih_l0.size(0) / 3;
|
||||
op->params["num_layers"] = gru->namedInput("num_layers");
|
||||
op->params["bias"] = gru->namedInput("has_biases");
|
||||
op->params["batch_first"] = gru->namedInput("batch_first");
|
||||
op->params["bidirectional"] = gru->namedInput("bidirectional");
|
||||
|
||||
const int num_layers = op->params["num_layers"].i;
|
||||
const bool bias = op->params["bias"].b;
|
||||
const bool bidirectional = op->params["bidirectional"].b;
|
||||
|
||||
for (int k = 0; k < num_layers; k++)
|
||||
{
|
||||
std::string weight_ih_lk_key = std::string("weight_ih_l") + std::to_string(k);
|
||||
std::string weight_hh_lk_key = std::string("weight_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[weight_ih_lk_key] = mod.attr(weight_ih_lk_key).toTensor();
|
||||
op->attrs[weight_hh_lk_key] = mod.attr(weight_hh_lk_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_key = std::string("bias_ih_l") + std::to_string(k);
|
||||
std::string bias_hh_lk_key = std::string("bias_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[bias_ih_lk_key] = mod.attr(bias_ih_lk_key).toTensor();
|
||||
op->attrs[bias_hh_lk_key] = mod.attr(bias_hh_lk_key).toTensor();
|
||||
}
|
||||
|
||||
if (bidirectional)
|
||||
{
|
||||
std::string weight_ih_lk_reverse_key = std::string("weight_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string weight_hh_lk_reverse_key = std::string("weight_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[weight_ih_lk_reverse_key] = mod.attr(weight_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[weight_hh_lk_reverse_key] = mod.attr(weight_hh_lk_reverse_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_reverse_key = std::string("bias_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string bias_hh_lk_reverse_key = std::string("bias_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[bias_ih_lk_reverse_key] = mod.attr(bias_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[bias_hh_lk_reverse_key] = mod.attr(bias_hh_lk_reverse_key).toTensor();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(GRU)
|
||||
|
||||
} // namespace pnnx
|
||||
67
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GroupNorm.cpp
vendored
Normal file
67
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_GroupNorm.cpp
vendored
Normal file
@@ -0,0 +1,67 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class GroupNorm : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.normalization.GroupNorm";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.GroupNorm";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* gn = find_node_by_kind(graph, "aten::group_norm");
|
||||
|
||||
// for (auto aa : gn->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["num_groups"] = gn->namedInput("num_groups");
|
||||
op->params["eps"] = gn->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_channels"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
else
|
||||
{
|
||||
fprintf(stderr, "Cannot resolve GroupNorm num_channels when affint=False\n");
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(GroupNorm)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardshrink.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardshrink.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardshrink : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardshrink";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardshrink";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* hardshrink = find_node_by_kind(graph, "aten::hardshrink");
|
||||
|
||||
op->params["lambd"] = hardshrink->namedInput("lambd");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardshrink)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardsigmoid.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardsigmoid.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardsigmoid : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardsigmoid";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardsigmoid";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardsigmoid)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardswish.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardswish.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardswish : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardswish";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardswish";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardswish)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardtanh.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Hardtanh.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Hardtanh : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Hardtanh";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Hardtanh";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* hardtanh = find_node_by_kind(graph, "aten::hardtanh");
|
||||
|
||||
op->params["min_val"] = hardtanh->namedInput("min_val");
|
||||
op->params["max_val"] = hardtanh->namedInput("max_val");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Hardtanh)
|
||||
|
||||
} // namespace pnnx
|
||||
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm1d.cpp
vendored
Normal file
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm1d.cpp
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class InstanceNorm1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.instancenorm.InstanceNorm1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.InstanceNorm1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* in = find_node_by_kind(graph, "aten::instance_norm");
|
||||
|
||||
// for (auto aa : in->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["eps"] = in->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
op->params["track_running_stats"] = mod.hasattr("running_mean") && mod.hasattr("running_var");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_features"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
|
||||
if (mod.hasattr("running_mean") && mod.hasattr("running_var"))
|
||||
{
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = mod.attr("running_var").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(InstanceNorm1d)
|
||||
|
||||
} // namespace pnnx
|
||||
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm2d.cpp
vendored
Normal file
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm2d.cpp
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class InstanceNorm2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.instancenorm.InstanceNorm2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.InstanceNorm2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* in = find_node_by_kind(graph, "aten::instance_norm");
|
||||
|
||||
// for (auto aa : in->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["eps"] = in->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
op->params["track_running_stats"] = mod.hasattr("running_mean") && mod.hasattr("running_var");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_features"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
|
||||
if (mod.hasattr("running_mean") && mod.hasattr("running_var"))
|
||||
{
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = mod.attr("running_var").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(InstanceNorm2d)
|
||||
|
||||
} // namespace pnnx
|
||||
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm3d.cpp
vendored
Normal file
73
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_InstanceNorm3d.cpp
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class InstanceNorm3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.instancenorm.InstanceNorm3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.InstanceNorm3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* in = find_node_by_kind(graph, "aten::instance_norm");
|
||||
|
||||
// for (auto aa : in->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
op->params["eps"] = in->namedInput("eps");
|
||||
op->params["affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
op->params["track_running_stats"] = mod.hasattr("running_mean") && mod.hasattr("running_var");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_features"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
|
||||
if (mod.hasattr("running_mean") && mod.hasattr("running_var"))
|
||||
{
|
||||
const auto& running_mean = mod.attr("running_mean").toTensor();
|
||||
|
||||
op->params["num_features"] = running_mean.size(0);
|
||||
|
||||
op->attrs["running_mean"] = running_mean;
|
||||
op->attrs["running_var"] = mod.attr("running_var").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(InstanceNorm3d)
|
||||
|
||||
} // namespace pnnx
|
||||
56
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LPPool1d.cpp
vendored
Normal file
56
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LPPool1d.cpp
vendored
Normal file
@@ -0,0 +1,56 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LPPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.LPPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LPPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* pow = find_node_by_kind(graph, "aten::pow");
|
||||
op->params["norm_type"] = pow->inputs()[1];
|
||||
|
||||
const torch::jit::Node* avg_pool1d = find_node_by_kind(graph, "aten::avg_pool1d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool1d->namedInput("kernel_size")->node()->inputs()[0];
|
||||
if (avg_pool1d->namedInput("stride")->node()->inputs().size() == 0)
|
||||
{
|
||||
op->params["stride"] = op->params["kernel_size"];
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["stride"] = avg_pool1d->namedInput("stride")->node()->inputs()[0];
|
||||
}
|
||||
op->params["ceil_mode"] = avg_pool1d->namedInput("ceil_mode");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LPPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
56
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LPPool2d.cpp
vendored
Normal file
56
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LPPool2d.cpp
vendored
Normal file
@@ -0,0 +1,56 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LPPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.LPPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LPPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* pow = find_node_by_kind(graph, "aten::pow");
|
||||
op->params["norm_type"] = pow->inputs()[1];
|
||||
|
||||
const torch::jit::Node* avg_pool2d = find_node_by_kind(graph, "aten::avg_pool2d");
|
||||
|
||||
op->params["kernel_size"] = avg_pool2d->namedInput("kernel_size");
|
||||
if (avg_pool2d->namedInput("stride")->node()->inputs().size() == 0)
|
||||
{
|
||||
op->params["stride"] = op->params["kernel_size"];
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["stride"] = avg_pool2d->namedInput("stride");
|
||||
}
|
||||
op->params["ceil_mode"] = avg_pool2d->namedInput("ceil_mode");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LPPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
110
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LSTM.cpp
vendored
Normal file
110
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LSTM.cpp
vendored
Normal file
@@ -0,0 +1,110 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LSTM : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.rnn.LSTM";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LSTM";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// mod.dump(true, true, true);
|
||||
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* lstm = find_node_by_kind(graph, "aten::lstm");
|
||||
|
||||
const torch::jit::Node* return_tuple = find_node_by_kind(graph, "prim::TupleConstruct");
|
||||
if (return_tuple && return_tuple->inputs().size() == 3 && lstm->outputs().size() == 3
|
||||
&& return_tuple->inputs()[0] == lstm->outputs()[1] && return_tuple->inputs()[1] == lstm->outputs()[2] && return_tuple->inputs()[2] == lstm->outputs()[0])
|
||||
{
|
||||
// mark the swapped output tuple
|
||||
// we would restore the fine order in pass_level3/fuse_rnn_unpack
|
||||
fprintf(stderr, "swapped detected !\n");
|
||||
op->params["pnnx_rnn_output_swapped"] = 1;
|
||||
}
|
||||
|
||||
// for (auto aa : lstm->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
const auto& weight_ih_l0 = mod.attr("weight_ih_l0").toTensor();
|
||||
|
||||
op->params["input_size"] = weight_ih_l0.size(1);
|
||||
op->params["hidden_size"] = weight_ih_l0.size(0) / 4;
|
||||
op->params["num_layers"] = lstm->namedInput("num_layers");
|
||||
op->params["bias"] = lstm->namedInput("has_biases");
|
||||
op->params["batch_first"] = lstm->namedInput("batch_first");
|
||||
op->params["bidirectional"] = lstm->namedInput("bidirectional");
|
||||
|
||||
const int num_layers = op->params["num_layers"].i;
|
||||
const bool bias = op->params["bias"].b;
|
||||
const bool bidirectional = op->params["bidirectional"].b;
|
||||
|
||||
for (int k = 0; k < num_layers; k++)
|
||||
{
|
||||
std::string weight_ih_lk_key = std::string("weight_ih_l") + std::to_string(k);
|
||||
std::string weight_hh_lk_key = std::string("weight_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[weight_ih_lk_key] = mod.attr(weight_ih_lk_key).toTensor();
|
||||
op->attrs[weight_hh_lk_key] = mod.attr(weight_hh_lk_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_key = std::string("bias_ih_l") + std::to_string(k);
|
||||
std::string bias_hh_lk_key = std::string("bias_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[bias_ih_lk_key] = mod.attr(bias_ih_lk_key).toTensor();
|
||||
op->attrs[bias_hh_lk_key] = mod.attr(bias_hh_lk_key).toTensor();
|
||||
}
|
||||
|
||||
if (bidirectional)
|
||||
{
|
||||
std::string weight_ih_lk_reverse_key = std::string("weight_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string weight_hh_lk_reverse_key = std::string("weight_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[weight_ih_lk_reverse_key] = mod.attr(weight_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[weight_hh_lk_reverse_key] = mod.attr(weight_hh_lk_reverse_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_reverse_key = std::string("bias_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string bias_hh_lk_reverse_key = std::string("bias_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[bias_ih_lk_reverse_key] = mod.attr(bias_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[bias_hh_lk_reverse_key] = mod.attr(bias_hh_lk_reverse_key).toTensor();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LSTM)
|
||||
|
||||
} // namespace pnnx
|
||||
52
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LayerNorm.cpp
vendored
Normal file
52
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LayerNorm.cpp
vendored
Normal file
@@ -0,0 +1,52 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LayerNorm : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.normalization.LayerNorm";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LayerNorm";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* ln = find_node_by_kind(graph, "aten::layer_norm");
|
||||
|
||||
op->params["normalized_shape"] = ln->namedInput("normalized_shape");
|
||||
op->params["eps"] = ln->namedInput("eps");
|
||||
op->params["elementwise_affine"] = mod.hasattr("weight") && mod.hasattr("bias");
|
||||
|
||||
if (mod.hasattr("weight") && mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["weight"] = mod.attr("weight").toTensor();
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LayerNorm)
|
||||
|
||||
} // namespace pnnx
|
||||
50
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LeakyReLU.cpp
vendored
Normal file
50
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LeakyReLU.cpp
vendored
Normal file
@@ -0,0 +1,50 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LeakyReLU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.LeakyReLU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LeakyReLU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* leaky_relu = find_node_by_kind(graph, "aten::leaky_relu");
|
||||
const torch::jit::Node* leaky_relu_ = find_node_by_kind(graph, "aten::leaky_relu_");
|
||||
|
||||
if (leaky_relu_)
|
||||
{
|
||||
leaky_relu = leaky_relu_;
|
||||
}
|
||||
|
||||
op->params["negative_slope"] = leaky_relu->namedInput("negative_slope");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LeakyReLU)
|
||||
|
||||
} // namespace pnnx
|
||||
54
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Linear.cpp
vendored
Normal file
54
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Linear.cpp
vendored
Normal file
@@ -0,0 +1,54 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Linear : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.linear.Linear";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Linear";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
const torch::jit::Node* addmm = find_node_by_kind(graph, "aten::addmm");
|
||||
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["in_features"] = weight.size(1);
|
||||
op->params["out_features"] = weight.size(0);
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
if (mod.hasattr("bias"))
|
||||
{
|
||||
op->attrs["bias"] = mod.attr("bias").toTensor();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Linear)
|
||||
|
||||
} // namespace pnnx
|
||||
59
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LocalResponseNorm.cpp
vendored
Normal file
59
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LocalResponseNorm.cpp
vendored
Normal file
@@ -0,0 +1,59 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LocalResponseNorm : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.normalization.LocalResponseNorm";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LocalResponseNorm";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* avg_pool = find_node_by_kind(graph, "aten::avg_pool2d");
|
||||
const torch::jit::Node* avg_pool3d = find_node_by_kind(graph, "aten::avg_pool3d");
|
||||
|
||||
if (avg_pool3d)
|
||||
{
|
||||
avg_pool = avg_pool3d;
|
||||
}
|
||||
|
||||
op->params["size"] = avg_pool->namedInput("kernel_size")->node()->inputs()[0];
|
||||
|
||||
const torch::jit::Node* pow = find_node_by_kind(graph, "aten::pow");
|
||||
op->params["beta"] = pow->inputs()[1];
|
||||
|
||||
const torch::jit::Node* add = pow->inputs()[0]->node();
|
||||
op->params["k"] = add->inputs()[1];
|
||||
|
||||
const torch::jit::Node* mul = add->inputs()[0]->node();
|
||||
op->params["alpha"] = mul->inputs()[1];
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LocalResponseNorm)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LogSigmoid.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LogSigmoid.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LogSigmoid : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.LogSigmoid";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LogSigmoid";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LogSigmoid)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LogSoftmax.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_LogSoftmax.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class LogSoftmax : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.LogSoftmax";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.LogSoftmax";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* log_softmax = find_node_by_kind(graph, "aten::log_softmax");
|
||||
|
||||
op->params["dim"] = log_softmax->namedInput("dim");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(LogSoftmax)
|
||||
|
||||
} // namespace pnnx
|
||||
55
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MaxPool1d.cpp
vendored
Normal file
55
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MaxPool1d.cpp
vendored
Normal file
@@ -0,0 +1,55 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class MaxPool1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.MaxPool1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.MaxPool1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* max_pool1d = find_node_by_kind(graph, "aten::max_pool1d");
|
||||
const torch::jit::Node* max_pool1d_with_indices = find_node_by_kind(graph, "aten::max_pool1d_with_indices");
|
||||
|
||||
if (max_pool1d_with_indices)
|
||||
{
|
||||
max_pool1d = max_pool1d_with_indices;
|
||||
}
|
||||
|
||||
op->params["kernel_size"] = max_pool1d->namedInput("kernel_size");
|
||||
op->params["stride"] = max_pool1d->namedInput("stride");
|
||||
op->params["padding"] = max_pool1d->namedInput("padding");
|
||||
op->params["dilation"] = max_pool1d->namedInput("dilation");
|
||||
op->params["ceil_mode"] = max_pool1d->namedInput("ceil_mode");
|
||||
op->params["return_indices"] = max_pool1d_with_indices ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(MaxPool1d)
|
||||
|
||||
} // namespace pnnx
|
||||
55
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MaxPool2d.cpp
vendored
Normal file
55
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MaxPool2d.cpp
vendored
Normal file
@@ -0,0 +1,55 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class MaxPool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.MaxPool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.MaxPool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* max_pool2d = find_node_by_kind(graph, "aten::max_pool2d");
|
||||
const torch::jit::Node* max_pool2d_with_indices = find_node_by_kind(graph, "aten::max_pool2d_with_indices");
|
||||
|
||||
if (max_pool2d_with_indices)
|
||||
{
|
||||
max_pool2d = max_pool2d_with_indices;
|
||||
}
|
||||
|
||||
op->params["kernel_size"] = max_pool2d->namedInput("kernel_size");
|
||||
op->params["stride"] = max_pool2d->namedInput("stride");
|
||||
op->params["padding"] = max_pool2d->namedInput("padding");
|
||||
op->params["dilation"] = max_pool2d->namedInput("dilation");
|
||||
op->params["ceil_mode"] = max_pool2d->namedInput("ceil_mode");
|
||||
op->params["return_indices"] = max_pool2d_with_indices ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(MaxPool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
55
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MaxPool3d.cpp
vendored
Normal file
55
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MaxPool3d.cpp
vendored
Normal file
@@ -0,0 +1,55 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class MaxPool3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.MaxPool3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.MaxPool3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* max_pool3d = find_node_by_kind(graph, "aten::max_pool3d");
|
||||
const torch::jit::Node* max_pool3d_with_indices = find_node_by_kind(graph, "aten::max_pool3d_with_indices");
|
||||
|
||||
if (max_pool3d_with_indices)
|
||||
{
|
||||
max_pool3d = max_pool3d_with_indices;
|
||||
}
|
||||
|
||||
op->params["kernel_size"] = max_pool3d->namedInput("kernel_size");
|
||||
op->params["stride"] = max_pool3d->namedInput("stride");
|
||||
op->params["padding"] = max_pool3d->namedInput("padding");
|
||||
op->params["dilation"] = max_pool3d->namedInput("dilation");
|
||||
op->params["ceil_mode"] = max_pool3d->namedInput("ceil_mode");
|
||||
op->params["return_indices"] = max_pool3d_with_indices ? true : false;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(MaxPool3d)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Mish.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Mish.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Mish : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Mish";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Mish";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Mish)
|
||||
|
||||
} // namespace pnnx
|
||||
126
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MultiheadAttention.cpp
vendored
Normal file
126
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_MultiheadAttention.cpp
vendored
Normal file
@@ -0,0 +1,126 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include <torch/csrc/api/include/torch/torch.h>
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class MultiheadAttention : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.MultiheadAttention";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.MultiheadAttention";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// mod.dump(false, false, false);
|
||||
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* div_num_heads = find_node_by_kind(graph, "aten::div");
|
||||
const torch::jit::Node* div_num_heads_18 = find_node_by_kind(graph, "aten::floor_divide");
|
||||
if (div_num_heads_18)
|
||||
{
|
||||
div_num_heads = div_num_heads_18;
|
||||
}
|
||||
|
||||
op->params["num_heads"] = (int)div_num_heads->input(1)->node()->t(torch::jit::attr::value).item<int64_t>();
|
||||
|
||||
const torch::jit::Node* transpose_batch_seq = find_node_by_kind(graph, "aten::transpose");
|
||||
|
||||
int transpose_dim0 = transpose_batch_seq->input(1)->node()->i(torch::jit::attr::value);
|
||||
int transpose_dim1 = transpose_batch_seq->input(2)->node()->i(torch::jit::attr::value);
|
||||
if (transpose_dim0 == 1 && transpose_dim1 == 0)
|
||||
{
|
||||
op->params["batch_first"] = true;
|
||||
}
|
||||
#if TORCH_VERSION_MAJOR == 1 && TORCH_VERSION_MINOR >= 9
|
||||
else
|
||||
{
|
||||
op->params["batch_first"] = false;
|
||||
}
|
||||
#endif
|
||||
|
||||
const torch::jit::Node* add_zero_attn = find_node_by_kind(graph, "aten::zeros");
|
||||
if (add_zero_attn)
|
||||
{
|
||||
op->params["add_zero_attn"] = true;
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["add_zero_attn"] = false;
|
||||
}
|
||||
|
||||
const auto& in_proj_weight = mod.attr("in_proj_weight").toTensor();
|
||||
const auto& out_proj_weight = mod.attr("out_proj").toModule().attr("weight").toTensor();
|
||||
|
||||
op->params["embed_dim"] = in_proj_weight.size(1);
|
||||
op->attrs["in_proj_weight"] = in_proj_weight;
|
||||
op->attrs["out_proj.weight"] = out_proj_weight;
|
||||
|
||||
if (mod.hasattr("in_proj_bias") && mod.attr("out_proj").toModule().hasattr("bias"))
|
||||
{
|
||||
// bias=True
|
||||
const auto& in_proj_bias = mod.attr("in_proj_bias").toTensor();
|
||||
const auto& out_proj_bias = mod.attr("out_proj").toModule().attr("bias").toTensor();
|
||||
|
||||
op->params["bias"] = true;
|
||||
op->attrs["in_proj_bias"] = in_proj_bias;
|
||||
op->attrs["out_proj.bias"] = out_proj_bias;
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["bias"] = false;
|
||||
#if TORCH_VERSION_MAJOR == 1 && TORCH_VERSION_MINOR == 8
|
||||
// the output projection bias always there no matter bias is False in pytorch 1.8
|
||||
// this behavior changes since https://github.com/pytorch/pytorch/commit/58d1b3639bc07f9519de18e5a18e575f260c7eeb
|
||||
if (mod.attr("out_proj").toModule().hasattr("bias"))
|
||||
{
|
||||
const auto& out_proj_bias = mod.attr("out_proj").toModule().attr("bias").toTensor();
|
||||
op->attrs["out_proj.bias"] = out_proj_bias;
|
||||
}
|
||||
#endif
|
||||
}
|
||||
|
||||
if (mod.hasattr("bias_k") && mod.hasattr("bias_v"))
|
||||
{
|
||||
// add_bias_kv=True
|
||||
const auto& bias_k = mod.attr("bias_k").toTensor();
|
||||
const auto& bias_v = mod.attr("bias_v").toTensor();
|
||||
|
||||
op->params["add_bias_kv"] = true;
|
||||
op->attrs["bias_k"] = bias_k;
|
||||
op->attrs["bias_v"] = bias_v;
|
||||
}
|
||||
else
|
||||
{
|
||||
op->params["add_bias_kv"] = false;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(MultiheadAttention)
|
||||
|
||||
} // namespace pnnx
|
||||
46
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_PReLU.cpp
vendored
Normal file
46
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_PReLU.cpp
vendored
Normal file
@@ -0,0 +1,46 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class PReLU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.PReLU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.PReLU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& /*graph*/, const torch::jit::Module& mod) const
|
||||
{
|
||||
const auto& weight = mod.attr("weight").toTensor();
|
||||
|
||||
op->params["num_parameters"] = weight.size(0);
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(PReLU)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_PixelShuffle.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_PixelShuffle.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class PixelShuffle : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pixelshuffle.PixelShuffle";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.PixelShuffle";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* pixel_shuffle = find_node_by_kind(graph, "aten::pixel_shuffle");
|
||||
|
||||
op->params["upscale_factor"] = pixel_shuffle->namedInput("upscale_factor");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(PixelShuffle)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_PixelUnshuffle.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_PixelUnshuffle.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class PixelUnshuffle : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pixelshuffle.PixelUnshuffle";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.PixelUnshuffle";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* pixel_unshuffle = find_node_by_kind(graph, "aten::pixel_unshuffle");
|
||||
|
||||
op->params["downscale_factor"] = pixel_unshuffle->namedInput("downscale_factor");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(PixelUnshuffle)
|
||||
|
||||
} // namespace pnnx
|
||||
117
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_RNN.cpp
vendored
Normal file
117
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_RNN.cpp
vendored
Normal file
@@ -0,0 +1,117 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class RNN : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.rnn.RNN";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.RNN";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// mod.dump(true, true, true);
|
||||
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* rnn = find_node_by_kind(graph, "aten::rnn_tanh");
|
||||
const torch::jit::Node* rnn_relu = find_node_by_kind(graph, "aten::rnn_relu");
|
||||
|
||||
if (rnn_relu)
|
||||
{
|
||||
rnn = rnn_relu;
|
||||
}
|
||||
|
||||
const torch::jit::Node* return_tuple = find_node_by_kind(graph, "prim::TupleConstruct");
|
||||
if (return_tuple && return_tuple->inputs().size() == 2 && rnn->outputs().size() == 2
|
||||
&& return_tuple->inputs()[0] == rnn->outputs()[1] && return_tuple->inputs()[1] == rnn->outputs()[0])
|
||||
{
|
||||
// mark the swapped output tuple
|
||||
// we would restore the fine order in pass_level3/fuse_rnn_unpack
|
||||
fprintf(stderr, "swapped detected !\n");
|
||||
op->params["pnnx_rnn_output_swapped"] = 1;
|
||||
}
|
||||
|
||||
// for (auto aa : rnn->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
const auto& weight_ih_l0 = mod.attr("weight_ih_l0").toTensor();
|
||||
|
||||
op->params["input_size"] = weight_ih_l0.size(1);
|
||||
op->params["hidden_size"] = weight_ih_l0.size(0);
|
||||
op->params["num_layers"] = rnn->namedInput("num_layers");
|
||||
op->params["nonlinearity"] = rnn_relu ? "relu" : "tanh";
|
||||
op->params["bias"] = rnn->namedInput("has_biases");
|
||||
op->params["batch_first"] = rnn->namedInput("batch_first");
|
||||
op->params["bidirectional"] = rnn->namedInput("bidirectional");
|
||||
|
||||
const int num_layers = op->params["num_layers"].i;
|
||||
const bool bias = op->params["bias"].b;
|
||||
const bool bidirectional = op->params["bidirectional"].b;
|
||||
|
||||
for (int k = 0; k < num_layers; k++)
|
||||
{
|
||||
std::string weight_ih_lk_key = std::string("weight_ih_l") + std::to_string(k);
|
||||
std::string weight_hh_lk_key = std::string("weight_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[weight_ih_lk_key] = mod.attr(weight_ih_lk_key).toTensor();
|
||||
op->attrs[weight_hh_lk_key] = mod.attr(weight_hh_lk_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_key = std::string("bias_ih_l") + std::to_string(k);
|
||||
std::string bias_hh_lk_key = std::string("bias_hh_l") + std::to_string(k);
|
||||
|
||||
op->attrs[bias_ih_lk_key] = mod.attr(bias_ih_lk_key).toTensor();
|
||||
op->attrs[bias_hh_lk_key] = mod.attr(bias_hh_lk_key).toTensor();
|
||||
}
|
||||
|
||||
if (bidirectional)
|
||||
{
|
||||
std::string weight_ih_lk_reverse_key = std::string("weight_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string weight_hh_lk_reverse_key = std::string("weight_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[weight_ih_lk_reverse_key] = mod.attr(weight_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[weight_hh_lk_reverse_key] = mod.attr(weight_hh_lk_reverse_key).toTensor();
|
||||
|
||||
if (bias)
|
||||
{
|
||||
std::string bias_ih_lk_reverse_key = std::string("bias_ih_l") + std::to_string(k) + "_reverse";
|
||||
std::string bias_hh_lk_reverse_key = std::string("bias_hh_l") + std::to_string(k) + "_reverse";
|
||||
|
||||
op->attrs[bias_ih_lk_reverse_key] = mod.attr(bias_ih_lk_reverse_key).toTensor();
|
||||
op->attrs[bias_hh_lk_reverse_key] = mod.attr(bias_hh_lk_reverse_key).toTensor();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(RNN)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_RReLU.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_RReLU.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class RReLU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.RReLU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.RReLU";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* rrelu = find_node_by_kind(graph, "aten::rrelu");
|
||||
|
||||
op->params["lower"] = rrelu->namedInput("lower");
|
||||
op->params["upper"] = rrelu->namedInput("upper");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(RReLU)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReLU.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReLU.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReLU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.ReLU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReLU";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReLU)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReLU6.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReLU6.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReLU6 : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.ReLU6";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReLU6";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReLU6)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReflectionPad1d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReflectionPad1d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReflectionPad1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ReflectionPad1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReflectionPad1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* reflection_pad1d = find_node_by_kind(graph, "aten::reflection_pad1d");
|
||||
|
||||
op->params["padding"] = reflection_pad1d->namedInput("padding");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReflectionPad1d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReflectionPad2d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReflectionPad2d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReflectionPad2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ReflectionPad2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReflectionPad2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* reflection_pad2d = find_node_by_kind(graph, "aten::reflection_pad2d");
|
||||
|
||||
op->params["padding"] = reflection_pad2d->namedInput("padding");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReflectionPad2d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReplicationPad1d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReplicationPad1d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReplicationPad1d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ReplicationPad1d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReplicationPad1d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* replication_pad1d = find_node_by_kind(graph, "aten::replication_pad1d");
|
||||
|
||||
op->params["padding"] = replication_pad1d->namedInput("padding");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReplicationPad1d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReplicationPad2d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReplicationPad2d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReplicationPad2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ReplicationPad2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReplicationPad2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* replication_pad2d = find_node_by_kind(graph, "aten::replication_pad2d");
|
||||
|
||||
op->params["padding"] = replication_pad2d->namedInput("padding");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReplicationPad2d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReplicationPad3d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ReplicationPad3d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ReplicationPad3d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ReplicationPad3d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ReplicationPad3d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* replication_pad3d = find_node_by_kind(graph, "aten::replication_pad3d");
|
||||
|
||||
op->params["padding"] = replication_pad3d->namedInput("padding");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ReplicationPad3d)
|
||||
|
||||
} // namespace pnnx
|
||||
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_SELU.cpp
vendored
Normal file
37
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_SELU.cpp
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class SELU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.SELU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.SELU";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(SELU)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_SiLU.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_SiLU.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class SiLU : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.SiLU";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.SiLU";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(SiLU)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Sigmoid.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Sigmoid.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Sigmoid : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Sigmoid";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Sigmoid";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Sigmoid)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softmax.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softmax.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Softmax : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Softmax";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Softmax";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* softmax = find_node_by_kind(graph, "aten::softmax");
|
||||
|
||||
op->params["dim"] = softmax->namedInput("dim");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Softmax)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softmin.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softmin.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Softmin : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Softmin";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Softmin";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* softmax = find_node_by_kind(graph, "aten::softmax");
|
||||
|
||||
op->params["dim"] = softmax->namedInput("dim");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Softmin)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softplus.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softplus.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Softplus : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Softplus";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Softplus";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* softplus = find_node_by_kind(graph, "aten::softplus");
|
||||
|
||||
op->params["beta"] = softplus->namedInput("beta");
|
||||
op->params["threshold"] = softplus->namedInput("threshold");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Softplus)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softshrink.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softshrink.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Softshrink : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Softshrink";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Softshrink";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* softshrink = find_node_by_kind(graph, "aten::softshrink");
|
||||
|
||||
op->params["lambd"] = softshrink->namedInput("lambd");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Softshrink)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softsign.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Softsign.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Softsign : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Softsign";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Softsign";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Softsign)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Tanh.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Tanh.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Tanh : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Tanh";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Tanh";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Tanh)
|
||||
|
||||
} // namespace pnnx
|
||||
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Tanhshrink.cpp
vendored
Normal file
35
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Tanhshrink.cpp
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Tanhshrink : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Tanhshrink";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Tanhshrink";
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Tanhshrink)
|
||||
|
||||
} // namespace pnnx
|
||||
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Threshold.cpp
vendored
Normal file
45
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Threshold.cpp
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Threshold : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.activation.Threshold";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Threshold";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* threshold = find_node_by_kind(graph, "aten::threshold");
|
||||
|
||||
op->params["threshold"] = threshold->namedInput("threshold");
|
||||
op->params["value"] = threshold->namedInput("value");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Threshold)
|
||||
|
||||
} // namespace pnnx
|
||||
102
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Upsample.cpp
vendored
Normal file
102
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_Upsample.cpp
vendored
Normal file
@@ -0,0 +1,102 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class Upsample : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.upsampling.Upsample";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.Upsample";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* upsample_nearest1d = find_node_by_kind(graph, "aten::upsample_nearest1d");
|
||||
const torch::jit::Node* upsample_linear1d = find_node_by_kind(graph, "aten::upsample_linear1d");
|
||||
|
||||
const torch::jit::Node* upsample_nearest2d = find_node_by_kind(graph, "aten::upsample_nearest2d");
|
||||
const torch::jit::Node* upsample_bilinear2d = find_node_by_kind(graph, "aten::upsample_bilinear2d");
|
||||
const torch::jit::Node* upsample_bicubic2d = find_node_by_kind(graph, "aten::upsample_bicubic2d");
|
||||
|
||||
const torch::jit::Node* upsample_nearest3d = find_node_by_kind(graph, "aten::upsample_nearest3d");
|
||||
const torch::jit::Node* upsample_trilinear3d = find_node_by_kind(graph, "aten::upsample_trilinear3d");
|
||||
|
||||
const torch::jit::Node* upsample = 0;
|
||||
if (upsample_nearest1d)
|
||||
{
|
||||
upsample = upsample_nearest1d;
|
||||
op->params["mode"] = "nearest";
|
||||
}
|
||||
else if (upsample_linear1d)
|
||||
{
|
||||
upsample = upsample_linear1d;
|
||||
op->params["mode"] = "linear";
|
||||
}
|
||||
else if (upsample_nearest2d)
|
||||
{
|
||||
upsample = upsample_nearest2d;
|
||||
op->params["mode"] = "nearest";
|
||||
}
|
||||
else if (upsample_bilinear2d)
|
||||
{
|
||||
upsample = upsample_bilinear2d;
|
||||
op->params["mode"] = "bilinear";
|
||||
}
|
||||
else if (upsample_bicubic2d)
|
||||
{
|
||||
upsample = upsample_bicubic2d;
|
||||
op->params["mode"] = "bicubic";
|
||||
}
|
||||
else if (upsample_nearest3d)
|
||||
{
|
||||
upsample = upsample_nearest3d;
|
||||
op->params["mode"] = "nearest";
|
||||
}
|
||||
else if (upsample_trilinear3d)
|
||||
{
|
||||
upsample = upsample_trilinear3d;
|
||||
op->params["mode"] = "trilinear";
|
||||
}
|
||||
|
||||
if (upsample->hasNamedInput("output_size"))
|
||||
{
|
||||
op->params["size"] = upsample->namedInput("output_size");
|
||||
}
|
||||
|
||||
if (upsample->hasNamedInput("scale_factors"))
|
||||
{
|
||||
op->params["scale_factor"] = upsample->namedInput("scale_factors");
|
||||
}
|
||||
|
||||
if (upsample->hasNamedInput("align_corners"))
|
||||
{
|
||||
op->params["align_corners"] = upsample->namedInput("align_corners");
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(Upsample)
|
||||
|
||||
} // namespace pnnx
|
||||
52
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_UpsamplingBilinear2d.cpp
vendored
Normal file
52
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_UpsamplingBilinear2d.cpp
vendored
Normal file
@@ -0,0 +1,52 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class UpsamplingBilinear2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.upsampling.UpsamplingBilinear2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.UpsamplingBilinear2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* upsample = find_node_by_kind(graph, "aten::upsample_bilinear2d");
|
||||
|
||||
if (upsample->hasNamedInput("output_size"))
|
||||
{
|
||||
op->params["size"] = upsample->namedInput("output_size");
|
||||
}
|
||||
|
||||
if (upsample->hasNamedInput("scale_factors"))
|
||||
{
|
||||
op->params["scale_factor"] = upsample->namedInput("scale_factors");
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(UpsamplingBilinear2d)
|
||||
|
||||
} // namespace pnnx
|
||||
52
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_UpsamplingNearest2d.cpp
vendored
Normal file
52
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_UpsamplingNearest2d.cpp
vendored
Normal file
@@ -0,0 +1,52 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class UpsamplingNearest2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.upsampling.UpsamplingNearest2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.UpsamplingNearest2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* upsample = find_node_by_kind(graph, "aten::upsample_nearest2d");
|
||||
|
||||
if (upsample->hasNamedInput("output_size"))
|
||||
{
|
||||
op->params["size"] = upsample->namedInput("output_size");
|
||||
}
|
||||
|
||||
if (upsample->hasNamedInput("scale_factors"))
|
||||
{
|
||||
op->params["scale_factor"] = upsample->namedInput("scale_factors");
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(UpsamplingNearest2d)
|
||||
|
||||
} // namespace pnnx
|
||||
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ZeroPad2d.cpp
vendored
Normal file
44
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_ZeroPad2d.cpp
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class ZeroPad2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.padding.ZeroPad2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.ZeroPad2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph) const
|
||||
{
|
||||
const torch::jit::Node* constant_pad_nd = find_node_by_kind(graph, "aten::constant_pad_nd");
|
||||
|
||||
op->params["padding"] = constant_pad_nd->namedInput("pad");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(ZeroPad2d)
|
||||
|
||||
} // namespace pnnx
|
||||
80
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_maxunpool2d.cpp
vendored
Normal file
80
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_maxunpool2d.cpp
vendored
Normal file
@@ -0,0 +1,80 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../pass_level3/fuse_expression.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class MaxUnpool2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.modules.pooling.MaxUnpool2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.MaxUnpool2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
graph->dump();
|
||||
|
||||
{
|
||||
Graph pnnx_graph;
|
||||
|
||||
pass_level1(mod, graph, pnnx_graph);
|
||||
|
||||
fuse_expression(pnnx_graph);
|
||||
|
||||
Operator* expr_op = pnnx_graph.ops[2];
|
||||
|
||||
if (expr_op->type == "pnnx.Expression")
|
||||
{
|
||||
std::string expr = expr_op->params["expr"].s;
|
||||
|
||||
int stride0;
|
||||
int stride1;
|
||||
int kernel_size0;
|
||||
int kernel_size1;
|
||||
int padding0;
|
||||
int padding1;
|
||||
int nscan = sscanf(expr.c_str(), "(int(sub(add(mul(sub(size(@0,2),1),%d),%d),%d)),int(sub(add(mul(sub(size(@1,3),1),%d),%d),%d)))", &stride0, &kernel_size0, &padding0, &stride1, &kernel_size1, &padding1);
|
||||
if (nscan == 6)
|
||||
{
|
||||
op->params["kernel_size"] = Parameter{kernel_size0, kernel_size1};
|
||||
op->params["stride"] = Parameter{stride0, stride1};
|
||||
op->params["padding"] = Parameter{padding0 / 2, padding1 / 2};
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const torch::jit::Node* max_unpool2d = find_node_by_kind(graph, "aten::max_unpool2d");
|
||||
|
||||
for (auto aa : max_unpool2d->schema().arguments())
|
||||
{
|
||||
fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(MaxUnpool2d)
|
||||
|
||||
} // namespace pnnx
|
||||
185
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_quantized_Conv2d.cpp
vendored
Normal file
185
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_quantized_Conv2d.cpp
vendored
Normal file
@@ -0,0 +1,185 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class QuantizedConv2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.quantized.modules.conv.Conv2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.quantized.Conv2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* quantized_convolution = find_node_by_kind(graph, "quantized::conv2d");
|
||||
|
||||
// for (auto aa : quantized_convolution->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
// torch::jit::Node* packed_params_node = 0;
|
||||
// for (const auto& n : graph->nodes())
|
||||
// {
|
||||
// if (n->kind() == c10::prim::GetAttr && n->s(torch::jit::attr::name) == "_packed_params")
|
||||
// {
|
||||
// packed_params_node = n;
|
||||
// break;
|
||||
// }
|
||||
// }
|
||||
|
||||
// quantized_convolution->namedInput("output_scale");
|
||||
|
||||
const auto& packed_params = mod.attr("_packed_params").toObject();
|
||||
|
||||
// auto x = torch::jit::script::Object(packed_params).run_method("__getstate__");
|
||||
auto x = torch::jit::script::Object(packed_params).run_method("unpack").toTuple();
|
||||
// std::cout << x->elements()[0].toTensor() << std::endl;
|
||||
// std::cout << x->elements()[0].toTensor().quantizer() << std::endl;
|
||||
// std::cout << x->elements()[1] << std::endl;
|
||||
// at::Tensor dequantize() const;
|
||||
// double q_scale() const;
|
||||
// int64_t q_zero_point() const;
|
||||
// at::Tensor q_per_channel_scales() const;
|
||||
// at::Tensor q_per_channel_zero_points() const;
|
||||
// int64_t q_per_channel_axis() const;
|
||||
|
||||
// auto quantizer = x->elements()[0].toTensor().quantizer();
|
||||
|
||||
auto weight = x->elements()[0].toTensor();
|
||||
auto bias = x->elements()[1].toTensor();
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = bias;
|
||||
|
||||
if (weight.qscheme() == c10::kPerChannelAffine)
|
||||
{
|
||||
op->attrs["weight.q_per_channel_scales"] = weight.q_per_channel_scales();
|
||||
op->attrs["weight.q_per_channel_zero_points"] = weight.q_per_channel_zero_points();
|
||||
// op->params["weight.q_per_channel_axis"] = weight.q_per_channel_axis();
|
||||
}
|
||||
|
||||
op->params["in_channels"] = mod.attr("in_channels").toInt();
|
||||
op->params["out_channels"] = mod.attr("out_channels").toInt();
|
||||
op->params["kernel_size"] = Parameter{mod.attr("kernel_size").toTuple()->elements()[0].toInt(), mod.attr("kernel_size").toTuple()->elements()[1].toInt()};
|
||||
op->params["stride"] = Parameter{mod.attr("stride").toTuple()->elements()[0].toInt(), mod.attr("stride").toTuple()->elements()[1].toInt()};
|
||||
op->params["padding"] = Parameter{mod.attr("padding").toTuple()->elements()[0].toInt(), mod.attr("padding").toTuple()->elements()[1].toInt()};
|
||||
op->params["dilation"] = Parameter{mod.attr("dilation").toTuple()->elements()[0].toInt(), mod.attr("dilation").toTuple()->elements()[1].toInt()};
|
||||
op->params["groups"] = mod.attr("groups").toInt();
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->params["scale"] = quantized_convolution->namedInput("output_scale");
|
||||
op->params["zero_point"] = quantized_convolution->namedInput("output_zero_point");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(QuantizedConv2d)
|
||||
|
||||
class QuantizedConvReLU2d : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.intrinsic.quantized.ConvReLU2d";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* quantized_convolution = find_node_by_kind(graph, "quantized::conv2d_relu");
|
||||
|
||||
// for (auto aa : quantized_convolution->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
|
||||
// torch::jit::Node* packed_params_node = 0;
|
||||
// for (const auto& n : graph->nodes())
|
||||
// {
|
||||
// if (n->kind() == c10::prim::GetAttr && n->s(torch::jit::attr::name) == "_packed_params")
|
||||
// {
|
||||
// packed_params_node = n;
|
||||
// break;
|
||||
// }
|
||||
// }
|
||||
|
||||
// quantized_convolution->namedInput("output_scale");
|
||||
|
||||
const auto& packed_params = mod.attr("_packed_params").toObject();
|
||||
|
||||
// auto x = torch::jit::script::Object(packed_params).run_method("__getstate__");
|
||||
auto x = torch::jit::script::Object(packed_params).run_method("unpack").toTuple();
|
||||
// std::cout << x->elements()[0].toTensor() << std::endl;
|
||||
// std::cout << x->elements()[0].toTensor().quantizer() << std::endl;
|
||||
// std::cout << x->elements()[1] << std::endl;
|
||||
// at::Tensor dequantize() const;
|
||||
// double q_scale() const;
|
||||
// int64_t q_zero_point() const;
|
||||
// at::Tensor q_per_channel_scales() const;
|
||||
// at::Tensor q_per_channel_zero_points() const;
|
||||
// int64_t q_per_channel_axis() const;
|
||||
|
||||
// auto quantizer = x->elements()[0].toTensor().quantizer();
|
||||
|
||||
auto weight = x->elements()[0].toTensor();
|
||||
auto bias = x->elements()[1].toTensor();
|
||||
|
||||
op->attrs["weight"] = weight;
|
||||
op->attrs["bias"] = bias;
|
||||
|
||||
if (weight.qscheme() == c10::kPerChannelAffine)
|
||||
{
|
||||
op->attrs["weight.q_per_channel_scales"] = weight.q_per_channel_scales();
|
||||
op->attrs["weight.q_per_channel_zero_points"] = weight.q_per_channel_zero_points();
|
||||
// op->params["weight.q_per_channel_axis"] = weight.q_per_channel_axis();
|
||||
}
|
||||
|
||||
op->params["in_channels"] = mod.attr("in_channels").toInt();
|
||||
op->params["out_channels"] = mod.attr("out_channels").toInt();
|
||||
op->params["kernel_size"] = Parameter{mod.attr("kernel_size").toTuple()->elements()[0].toInt(), mod.attr("kernel_size").toTuple()->elements()[1].toInt()};
|
||||
op->params["stride"] = Parameter{mod.attr("stride").toTuple()->elements()[0].toInt(), mod.attr("stride").toTuple()->elements()[1].toInt()};
|
||||
op->params["padding"] = Parameter{mod.attr("padding").toTuple()->elements()[0].toInt(), mod.attr("padding").toTuple()->elements()[1].toInt()};
|
||||
op->params["dilation"] = Parameter{mod.attr("dilation").toTuple()->elements()[0].toInt(), mod.attr("dilation").toTuple()->elements()[1].toInt()};
|
||||
op->params["groups"] = mod.attr("groups").toInt();
|
||||
op->params["padding_mode"] = "zeros";
|
||||
op->params["bias"] = mod.hasattr("bias");
|
||||
|
||||
op->params["scale"] = quantized_convolution->namedInput("output_scale");
|
||||
op->params["zero_point"] = quantized_convolution->namedInput("output_zero_point");
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(QuantizedConvReLU2d)
|
||||
|
||||
} // namespace pnnx
|
||||
51
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_quantized_DeQuantize.cpp
vendored
Normal file
51
3rdparty/ncnn/tools/pnnx/src/pass_level1/nn_quantized_DeQuantize.cpp
vendored
Normal file
@@ -0,0 +1,51 @@
|
||||
// Tencent is pleased to support the open source community by making ncnn available.
|
||||
//
|
||||
// Copyright (C) 2021 THL A29 Limited, a Tencent company. All rights reserved.
|
||||
//
|
||||
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
|
||||
// in compliance with the License. You may obtain a copy of the License at
|
||||
//
|
||||
// https://opensource.org/licenses/BSD-3-Clause
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software distributed
|
||||
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
|
||||
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
// specific language governing permissions and limitations under the License.
|
||||
|
||||
#include "pass_level1.h"
|
||||
|
||||
#include "../utils.h"
|
||||
|
||||
namespace pnnx {
|
||||
|
||||
class DeQuantize : public FuseModulePass
|
||||
{
|
||||
public:
|
||||
const char* match_type_str() const
|
||||
{
|
||||
return "__torch__.torch.nn.quantized.modules.DeQuantize";
|
||||
}
|
||||
|
||||
const char* type_str() const
|
||||
{
|
||||
return "nn.quantized.DeQuantize";
|
||||
}
|
||||
|
||||
void write(Operator* op, const std::shared_ptr<torch::jit::Graph>& graph, const torch::jit::Module& mod) const
|
||||
{
|
||||
// mod.dump(true, false, false);
|
||||
|
||||
// graph->dump();
|
||||
|
||||
const torch::jit::Node* dequantize = find_node_by_kind(graph, "aten::dequantize");
|
||||
|
||||
// for (auto aa : dequantize->schema().arguments())
|
||||
// {
|
||||
// fprintf(stderr, "arg %s\n", aa.name().c_str());
|
||||
// }
|
||||
}
|
||||
};
|
||||
|
||||
REGISTER_GLOBAL_PNNX_FUSE_MODULE_PASS(DeQuantize)
|
||||
|
||||
} // namespace pnnx
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user